Sign Up
Log In
Log In
or
Sign Up
Places
All Projects
Status Monitor
Collapse sidebar
openSUSE:Factory
tokei
tokei-13.0.0.alpha.5+git0.obscpio
Overview
Repositories
Revisions
Requests
Users
Attributes
Meta
File tokei-13.0.0.alpha.5+git0.obscpio of Package tokei
07070100000000000081A400000000000000000000000166C8A4FD00000060000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/.git-blame-ignore-revs# Format JSON d7c548537cd5828b2d58e09f3207ddacc517b227 f356d27ab21e0f93839da90393c0edf9225740c2 07070100000001000081A400000000000000000000000166C8A4FD00000024000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/.gitattributestests/data/* linguist-documentation 07070100000002000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000002200000000tokei-13.0.0.alpha.5+git0/.github07070100000003000081A400000000000000000000000166C8A4FD00000042000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/.github/FUNDING.yml# These are supported funding model platforms github: XAMPPRocky 07070100000004000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000002C00000000tokei-13.0.0.alpha.5+git0/.github/workflows07070100000005000081A400000000000000000000000166C8A4FD00001606000000000000000000000000000000000000003D00000000tokei-13.0.0.alpha.5+git0/.github/workflows/mean_bean_ci.ymlname: Mean Bean CI on: push: branches: - master pull_request: jobs: # This job downloads and stores `cross` as an artifact, so that it can be # redownloaded across all of the jobs. Currently this copied pasted between # `ci.yml` and `deploy.yml`. Make sure to update both places when making # changes. install-cross: runs-on: ubuntu-latest steps: - uses: XAMPPRocky/get-github-release@v1 id: cross with: owner: rust-embedded repo: cross matches: ${{ matrix.platform }} token: ${{ secrets.GITHUB_TOKEN }} - uses: actions/upload-artifact@v3 with: name: cross-${{ matrix.platform }} path: ${{ steps.cross.outputs.install_path }} strategy: matrix: platform: [linux-musl, apple-darwin] windows: runs-on: windows-latest # Windows technically doesn't need this, but if we don't block windows on it # some of the windows jobs could fill up the concurrent job queue before # one of the install-cross jobs has started, so this makes sure all # artifacts are downloaded first. needs: install-cross steps: - uses: actions/checkout@v3 - run: ci/set_rust_version.bash ${{ matrix.channel }} ${{ matrix.target }} shell: bash - run: ci/build.bash cargo ${{ matrix.target }} shell: bash - run: ci/test.bash cargo ${{ matrix.target }} shell: bash strategy: fail-fast: true matrix: channel: [stable, beta, nightly] target: # MSVC - i686-pc-windows-msvc - x86_64-pc-windows-msvc # GNU: You typically only need to test Windows GNU if you're # specifically targeting it, and it can cause issues with some # dependencies if you're not so it's disabled by self. # - i686-pc-windows-gnu # - x86_64-pc-windows-gnu macos: runs-on: macos-latest needs: install-cross steps: - uses: actions/checkout@v3 - uses: actions/download-artifact@v3 with: name: cross-apple-darwin path: /usr/local/bin/ - run: chmod +x /usr/local/bin/cross - run: ci/set_rust_version.bash ${{ matrix.channel }} ${{ matrix.target }} - run: ci/build.bash cross ${{ matrix.target }} # Only test on macOS platforms since we can't simulate iOS. - run: ci/test.bash cross ${{ matrix.target }} if: matrix.target == 'x86_64-apple-darwin' strategy: fail-fast: true matrix: channel: [stable, beta, nightly] target: # macOS - x86_64-apple-darwin # iOS - aarch64-apple-ios - x86_64-apple-ios linux: runs-on: ubuntu-latest needs: install-cross steps: - uses: actions/checkout@v3 - name: Download Cross uses: actions/download-artifact@v3 with: name: cross-linux-musl path: /tmp/ - run: chmod +x /tmp/cross - run: ci/set_rust_version.bash ${{ matrix.channel }} ${{ matrix.target }} - run: ci/build.bash /tmp/cross ${{ matrix.target }} # These targets have issues with being tested so they are disabled # by default. You can try disabling to see if they work for # your project. - run: ci/test.bash /tmp/cross ${{ matrix.target }} if: | !contains(matrix.target, 'android') && !contains(matrix.target, 'bsd') && !contains(matrix.target, 'solaris') && matrix.target != 'armv5te-unknown-linux-musleabi' && matrix.target != 'sparc64-unknown-linux-gnu' strategy: fail-fast: true matrix: channel: [stable, beta, nightly] target: # WASM, off by default as most rust projects aren't compatible yet. # - wasm32-unknown-emscripten # Linux - aarch64-unknown-linux-gnu - aarch64-unknown-linux-musl - arm-unknown-linux-gnueabi - arm-unknown-linux-gnueabihf - arm-unknown-linux-musleabi - arm-unknown-linux-musleabihf - armv5te-unknown-linux-musleabi - armv7-unknown-linux-gnueabihf - armv7-unknown-linux-musleabihf - i586-unknown-linux-gnu - i586-unknown-linux-musl - i686-unknown-linux-gnu - i686-unknown-linux-musl # - mips-unknown-linux-gnu # - mips-unknown-linux-musl # - mips64-unknown-linux-gnuabi64 # - mips64el-unknown-linux-gnuabi64 # - mipsel-unknown-linux-gnu # - mipsel-unknown-linux-musl - powerpc-unknown-linux-gnu - powerpc64le-unknown-linux-gnu - s390x-unknown-linux-gnu - x86_64-unknown-linux-gnu - x86_64-unknown-linux-musl # Android # - aarch64-linux-android # - arm-linux-androideabi # - armv7-linux-androideabi # - i686-linux-android # - x86_64-linux-android # *BSD # The FreeBSD targets can have issues linking so they are disabled # by default. # - i686-unknown-freebsd # - x86_64-unknown-freebsd # - x86_64-unknown-netbsd # Solaris # - sparcv9-sun-solaris # - x86_64-sun-solaris # Bare Metal # These are no-std embedded targets, so they will only build if your # crate is `no_std` compatible. # - thumbv6m-none-eabi # - thumbv7em-none-eabi # - thumbv7em-none-eabihf # - thumbv7m-none-eabi 07070100000006000081A400000000000000000000000166C8A4FD000019AC000000000000000000000000000000000000004100000000tokei-13.0.0.alpha.5+git0/.github/workflows/mean_bean_deploy.ymlon: workflow_run: workflows: ["Release-plz"] branches: [main] types: - completed name: Mean Bean Deploy env: BIN: tokei jobs: # This job downloads and stores `cross` as an artifact, so that it can be # redownloaded across all of the jobs. Currently this copied pasted between # `ci.yml` and `deploy.yml`. Make sure to update both places when making # changes. install-cross: runs-on: ubuntu-latest steps: - uses: XAMPPRocky/get-github-release@v1 id: cross with: owner: rust-embedded repo: cross matches: ${{ matrix.platform }} token: ${{ secrets.GITHUB_TOKEN }} - uses: actions/upload-artifact@v3 with: name: cross-${{ matrix.platform }} path: ${{ steps.cross.outputs.install_path }} strategy: matrix: platform: [linux-musl, apple-darwin] windows: runs-on: windows-latest needs: install-cross strategy: matrix: target: # MSVC - i686-pc-windows-msvc - x86_64-pc-windows-msvc # GNU # - i686-pc-windows-gnu # - x86_64-pc-windows-gnu steps: - uses: actions/checkout@v3 # FIXME: Hack around thinLTO being broken. - run: echo "RUSTFLAGS=-Clto=fat" >> $GITHUB_ENV - run: bash ci/set_rust_version.bash stable ${{ matrix.target }} - run: bash ci/build.bash cargo ${{ matrix.target }} RELEASE # We're using using a fork of `actions/create-release` that detects # whether a release is already available or not first. - uses: XAMPPRocky/create-release@v1.0.2 id: create_release env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} with: tag_name: ${{ github.ref }} release_name: ${{ github.ref }} # Draft should **always** be false. GitHub doesn't provide a way to # get draft releases from its API, so there's no point using it. draft: false prerelease: true - uses: actions/upload-release-asset@v1 id: upload-release-asset env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} with: upload_url: ${{ steps.create_release.outputs.upload_url }} asset_path: target/${{ matrix.target }}/release/${{ env.BIN }}.exe asset_name: ${{ env.BIN }}-${{ matrix.target }}.exe asset_content_type: application/zip macos: runs-on: macos-latest needs: install-cross strategy: matrix: target: # macOS - x86_64-apple-darwin # iOS # - aarch64-apple-ios # - armv7-apple-ios # - armv7s-apple-ios # - i386-apple-ios # - x86_64-apple-ios steps: - uses: actions/checkout@v3 - uses: actions/download-artifact@v3 with: name: cross-apple-darwin path: /usr/local/bin/ - run: chmod +x /usr/local/bin/cross - run: ci/set_rust_version.bash stable ${{ matrix.target }} - run: ci/build.bash cross ${{ matrix.target }} RELEASE - run: tar -czvf ${{ env.BIN }}.tar.gz --directory=target/${{ matrix.target }}/release ${{ env.BIN }} - uses: XAMPPRocky/create-release@v1.0.2 id: create_release env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} with: tag_name: ${{ github.ref }} release_name: ${{ github.ref }} draft: false prerelease: true - uses: actions/upload-release-asset@v1 id: upload-release-asset env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} with: upload_url: ${{ steps.create_release.outputs.upload_url }} asset_path: ${{ env.BIN }}.tar.gz asset_name: ${{ env.BIN }}-${{ matrix.target }}.tar.gz asset_content_type: application/gzip linux: runs-on: ubuntu-latest needs: install-cross strategy: fail-fast: false matrix: target: # WASM, off by default as most rust projects aren't compatible yet. # - wasm32-unknown-emscripten # Linux - aarch64-unknown-linux-gnu - arm-unknown-linux-gnueabi - armv7-unknown-linux-gnueabihf - i686-unknown-linux-gnu - i686-unknown-linux-musl - mips-unknown-linux-gnu - mips64-unknown-linux-gnuabi64 - mips64el-unknown-linux-gnuabi64 - mipsel-unknown-linux-gnu - powerpc64-unknown-linux-gnu - powerpc64le-unknown-linux-gnu - s390x-unknown-linux-gnu - x86_64-unknown-linux-gnu - x86_64-unknown-linux-musl # Android - aarch64-linux-android - arm-linux-androideabi - armv7-linux-androideabi - i686-linux-android - x86_64-linux-android # *BSD # The FreeBSD targets can have issues linking so they are disabled # by default. # - i686-unknown-freebsd # - x86_64-unknown-freebsd - x86_64-unknown-netbsd # Solaris - sparcv9-sun-solaris # Bare Metal # These are no-std embedded targets, so they will only build if your # crate is `no_std` compatible. # - thumbv6m-none-eabi # - thumbv7em-none-eabi # - thumbv7em-none-eabihf # - thumbv7m-none-eabi steps: - uses: actions/checkout@v3 - uses: actions/download-artifact@v3 with: name: cross-linux-musl path: /tmp/ - run: chmod +x /tmp/cross - run: ci/set_rust_version.bash stable ${{ matrix.target }} - run: ci/build.bash /tmp/cross ${{ matrix.target }} RELEASE - run: tar -czvf ${{ env.BIN }}.tar.gz --directory=target/${{ matrix.target }}/release ${{ env.BIN }} - uses: XAMPPRocky/create-release@v1.0.2 id: create_release env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} with: tag_name: ${{ github.ref }} release_name: ${{ github.ref }} draft: false prerelease: false - name: Upload Release Asset id: upload-release-asset uses: actions/upload-release-asset@v1 env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} with: upload_url: ${{ steps.create_release.outputs.upload_url }} asset_path: ${{ env.BIN }}.tar.gz asset_name: ${{ env.BIN }}-${{ matrix.target }}.tar.gz asset_content_type: application/gzip 07070100000007000081A400000000000000000000000166C8A4FD00000494000000000000000000000000000000000000003F00000000tokei-13.0.0.alpha.5+git0/.github/workflows/publish_image.yamlname: Publish Docker Images on: push: branches: - master tags: - v* jobs: image: concurrency: group: ${{ github.workflow }}-${{ github.ref }} cancel-in-progress: true runs-on: ubuntu-latest permissions: packages: write contents: read attestations: write steps: - uses: earthly/actions-setup@v1 with: github-token: ${{ secrets.GITHUB_TOKEN }} - name: Check out the repo uses: actions/checkout@v4 - name: Extract metadata (tags, labels) for Docker id: meta uses: docker/metadata-action@v5 with: images: ghcr.io/${{ github.repository }} tags: | type=semver,pattern={{raw}} type=raw,value=latest,enable={{is_default_branch}} - name: Log in to the Container registry uses: docker/login-action@v3 with: registry: ghcr.io username: ${{ github.actor }} password: ${{ secrets.GITHUB_TOKEN }} - name: Build and Push Docker Image run: echo "${{ steps.meta.outputs.tags }}" | xargs -I {} earthly --ci --push +docker --image_name="{}" 07070100000008000081A400000000000000000000000166C8A4FD00000254000000000000000000000000000000000000003D00000000tokei-13.0.0.alpha.5+git0/.github/workflows/release-plz.yamlname: Release-plz permissions: pull-requests: write contents: write on: push: branches: - master jobs: release-plz: name: Release-plz runs-on: ubuntu-22.04 steps: - name: Checkout repository uses: actions/checkout@v3 with: fetch-depth: 0 - name: Install Rust toolchain uses: dtolnay/rust-toolchain@stable - name: Run release-plz uses: MarcoIeni/release-plz-action@v0.5 env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} CARGO_REGISTRY_TOKEN: ${{ secrets.CARGO_REGISTRY_TOKEN }} 07070100000009000081A400000000000000000000000166C8A4FD00000251000000000000000000000000000000000000002500000000tokei-13.0.0.alpha.5+git0/.gitignore# Created by https://www.toptal.com/developers/gitignore/api/rust # Edit at https://www.toptal.com/developers/gitignore?templates=rust ### Rust ### # Generated by Cargo # will have compiled files and executables debug/ target/ # These are backup files generated by rustfmt **/*.rs.bk # MSVC Windows builds of rustc generate these, which store debugging information *.pdb # End of https://www.toptal.com/developers/gitignore/api/rust ### IDE ### .vscode .idea/ *.iml ### Other ### # macOS .DS_Store # settings .settings .tokeirc # benchmark results.csv node_modules *.code-workspace 0707010000000A000081A400000000000000000000000166C8A4FD00000118000000000000000000000000000000000000002300000000tokei-13.0.0.alpha.5+git0/.mailmapErin Power <xampprocky@gmail.com> <theaaronepower@gmail.com> Erin Power <xampprocky@gmail.com> <Aaronepower@users.noreply.github.com> Erin Power <xampprocky@gmail.com> <4464295+XAMPPRocky@users.noreply.github.com> Erin Power <xampprocky@gmail.com> <aaron.power@softwaredesign.ie> 0707010000000B000081A400000000000000000000000166C8A4FD00000015000000000000000000000000000000000000002600000000tokei-13.0.0.alpha.5+git0/.tokeignoretests/data resources 0707010000000C000081A400000000000000000000000166C8A4FD000090AA000000000000000000000000000000000000002700000000tokei-13.0.0.alpha.5+git0/CHANGELOG.md# Changelog All notable changes to this project will be documented in this file. The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/), and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html). ## [Unreleased] ## [13.0.0-alpha.5](https://github.com/XAMPPRocky/tokei/compare/v13.0.0-alpha.4...v13.0.0-alpha.5) - 2024-08-23 ### Fixed - fix issue https://github.com/XAMPPRocky/tokei/issues/1147 ([#1149](https://github.com/XAMPPRocky/tokei/pull/1149)) ### Other - Fix issue [#1145](https://github.com/XAMPPRocky/tokei/pull/1145) (part 2) ([#1148](https://github.com/XAMPPRocky/tokei/pull/1148)) ## [13.0.0-alpha.4](https://github.com/XAMPPRocky/tokei/compare/v13.0.0-alpha.3...v13.0.0-alpha.4) - 2024-08-22 ### Fixed - fix issue https://github.com/XAMPPRocky/tokei/issues/1145 ([#1146](https://github.com/XAMPPRocky/tokei/pull/1146)) ### Other - Add support for Glimmer JS/TS ([#1052](https://github.com/XAMPPRocky/tokei/pull/1052)) - Fix issue [#1141](https://github.com/XAMPPRocky/tokei/pull/1141) ([#1142](https://github.com/XAMPPRocky/tokei/pull/1142)) ## [13.0.0-alpha.3](https://github.com/XAMPPRocky/tokei/compare/v13.0.0-alpha.2...v13.0.0-alpha.3) - 2024-08-20 ### Fixed - fix issue https://github.com/XAMPPRocky/tokei/issues/1138 ([#1139](https://github.com/XAMPPRocky/tokei/pull/1139)) ## [13.0.0-alpha.2](https://github.com/XAMPPRocky/tokei/compare/v13.0.0-alpha.1...v13.0.0-alpha.2) - 2024-08-19 ### Added - Add support for Monkey C ([#1081](https://github.com/XAMPPRocky/tokei/pull/1081)) - added plantuml support ([#1125](https://github.com/XAMPPRocky/tokei/pull/1125)) - add language Tact ([#1103](https://github.com/XAMPPRocky/tokei/pull/1103)) - add support for bicep ([#1100](https://github.com/XAMPPRocky/tokei/pull/1100)) - add hledger ([#1121](https://github.com/XAMPPRocky/tokei/pull/1121)) - add SELinux CIL policy source files ([#1124](https://github.com/XAMPPRocky/tokei/pull/1124)) - --files argument now sorts alphabetically ([#1059](https://github.com/XAMPPRocky/tokei/pull/1059)) - add support for LALRPOP ([#1077](https://github.com/XAMPPRocky/tokei/pull/1077)) ### Fixed - read hidden from config file ([#1093](https://github.com/XAMPPRocky/tokei/pull/1093)) ### Other - Fix cargo audit issues ([#1137](https://github.com/XAMPPRocky/tokei/pull/1137)) - Add support for MDX ([#1046](https://github.com/XAMPPRocky/tokei/pull/1046)) - Add PRQL to README.md ([#1088](https://github.com/XAMPPRocky/tokei/pull/1088)) - add fypp extension `.fpp` to `languages.json` for Modern Fortran ([#1060](https://github.com/XAMPPRocky/tokei/pull/1060)) - Add support for Lex ([#1087](https://github.com/XAMPPRocky/tokei/pull/1087)) - Add d2 ([#1091](https://github.com/XAMPPRocky/tokei/pull/1091)) - Add support for Stata ([#1112](https://github.com/XAMPPRocky/tokei/pull/1112)) - Add support for CUE ([#1049](https://github.com/XAMPPRocky/tokei/pull/1049)) - bump libc from 0.2.147 to 0.2.155 ([#1104](https://github.com/XAMPPRocky/tokei/pull/1104)) - add cangjie language support ([#1127](https://github.com/XAMPPRocky/tokei/pull/1127)) ([#1128](https://github.com/XAMPPRocky/tokei/pull/1128)) - Add support for JSLT ([#1129](https://github.com/XAMPPRocky/tokei/pull/1129)) - Add Arturo support ([#1108](https://github.com/XAMPPRocky/tokei/pull/1108)) - Support Bazel's MODULE files and *.bzlmod files ([#1130](https://github.com/XAMPPRocky/tokei/pull/1130)) - read only first 128B from the file when searching for shebang ([#1040](https://github.com/XAMPPRocky/tokei/pull/1040)) - add OpenCL as a languages.json entry ([#980](https://github.com/XAMPPRocky/tokei/pull/980)) - Add GetText Portable Object (PO) files ([#814](https://github.com/XAMPPRocky/tokei/pull/814)) - Support godot shader ([#1118](https://github.com/XAMPPRocky/tokei/pull/1118)) - Add Modelica language ([#1061](https://github.com/XAMPPRocky/tokei/pull/1061)) - Add menhir support ([#781](https://github.com/XAMPPRocky/tokei/pull/781)) - Update README.md - [issue_1114] remove Cargo.lock from .gitignore ([#1115](https://github.com/XAMPPRocky/tokei/pull/1115)) - [issue_891] give more space for Files column ([#933](https://github.com/XAMPPRocky/tokei/pull/933)) - GitHub Action to publish docker images ([#1096](https://github.com/XAMPPRocky/tokei/pull/1096)) - Support MoonBit language. ([#1095](https://github.com/XAMPPRocky/tokei/pull/1095)) - Add OpenSCAD ([#1097](https://github.com/XAMPPRocky/tokei/pull/1097)) - add jinja extension for Jinja2 ([#1083](https://github.com/XAMPPRocky/tokei/pull/1083)) - Fix slang ([#1089](https://github.com/XAMPPRocky/tokei/pull/1089)) - Temporarily remove Hare - Support .pyi python file ([#1075](https://github.com/XAMPPRocky/tokei/pull/1075)) - add luau extension to lua ([#1066](https://github.com/XAMPPRocky/tokei/pull/1066)) - Adding support for Snakemake ([#1045](https://github.com/XAMPPRocky/tokei/pull/1045)) - Add Janet to languages.json ([#1042](https://github.com/XAMPPRocky/tokei/pull/1042)) - Add OpenQASM support ([#1041](https://github.com/XAMPPRocky/tokei/pull/1041)) - typst ([#1037](https://github.com/XAMPPRocky/tokei/pull/1037)) - Add the ZoKrates language ([#1035](https://github.com/XAMPPRocky/tokei/pull/1035)) - Add PRQL ([#1030](https://github.com/XAMPPRocky/tokei/pull/1030)) - remove refs ([#1006](https://github.com/XAMPPRocky/tokei/pull/1006)) - Add lingua franca language ([#993](https://github.com/XAMPPRocky/tokei/pull/993)) - Add support for Razor Components ([#992](https://github.com/XAMPPRocky/tokei/pull/992)) - Add arch's PKGBUILD files ([#972](https://github.com/XAMPPRocky/tokei/pull/972)) - Add Hare support ([#971](https://github.com/XAMPPRocky/tokei/pull/971)) - Add Max support ([#963](https://github.com/XAMPPRocky/tokei/pull/963)) - Add support for Chapel ([#960](https://github.com/XAMPPRocky/tokei/pull/960)) - Add language support for Slang ([#956](https://github.com/XAMPPRocky/tokei/pull/956)) - Update TypeScript language ([#953](https://github.com/XAMPPRocky/tokei/pull/953)) - Added support for Circom ([#949](https://github.com/XAMPPRocky/tokei/pull/949)) - link to earthly project ([#1078](https://github.com/XAMPPRocky/tokei/pull/1078)) ## [13.0.0-alpha.1](https://github.com/XAMPPRocky/tokei/compare/v13.0.0-alpha.0...v13.0.0-alpha.1) - 2024-03-04 ### Fixed - fixed language names not showing when in Light mode (light background ([#1048](https://github.com/XAMPPRocky/tokei/pull/1048)) ### Other - Create release-plz.yaml - Update mean_bean_ci.yml - Fix LD Script language data ([#1028](https://github.com/XAMPPRocky/tokei/pull/1028)) - Fix language data example in CONTRIBUTING.md ([#1029](https://github.com/XAMPPRocky/tokei/pull/1029)) - Update dependencies - Add widget install instructions - Update mean_bean_ci.yml - Dockerize tokei ([#930](https://github.com/XAMPPRocky/tokei/pull/930)) - Ignore format commits for `languages.json` ([#1013](https://github.com/XAMPPRocky/tokei/pull/1013)) - Upgrade GitHub Actions ([#955](https://github.com/XAMPPRocky/tokei/pull/955)) - add --languages ouput formatter ([#1007](https://github.com/XAMPPRocky/tokei/pull/1007)) - Add Nuget Config, Bazel and EdgeQL Support, Fix Output Formatter ([#999](https://github.com/XAMPPRocky/tokei/pull/999)) - show nushell in the readme ([#991](https://github.com/XAMPPRocky/tokei/pull/991)) - Add support for Redscript ([#994](https://github.com/XAMPPRocky/tokei/pull/994)) - Add support for jq ([#965](https://github.com/XAMPPRocky/tokei/pull/965)) - Add support for Astro ([#966](https://github.com/XAMPPRocky/tokei/pull/966)) - Use XDG conventions on macOS too ([#989](https://github.com/XAMPPRocky/tokei/pull/989)) - Add JSON5 support for languages.json ([#986](https://github.com/XAMPPRocky/tokei/pull/986)) - Delete Smalltalk.cs.st ([#990](https://github.com/XAMPPRocky/tokei/pull/990)) - Add support for smalltalk ([#839](https://github.com/XAMPPRocky/tokei/pull/839)) - Disable *-android - Add HiCAD to languages.json ([#985](https://github.com/XAMPPRocky/tokei/pull/985)) - Add Nushell to languages.json ([#982](https://github.com/XAMPPRocky/tokei/pull/982)) # 12.1.0 ## Introduction Tokei is a fast and accurate code analysis CLI tool and library, allowing you to easily and quickly see how many blank lines, comments, and lines of code are in your codebase. All releases and work on Tokei and tokei.rs ([the free companion badge service][rs-info]) are [funded by the community through GitHub Sponsors][sponsor]. You can always download the latest version of tokei through GitHub Releases or Cargo. Tokei is also available through other [package managers][pkg], though they may not always contain the latest release. ``` cargo install tokei ``` [pkg]: https://github.com/XAMPPRocky/tokei#package-managers [rs-info]: https://github.com/XAMPPRocky/tokei/blob/master/README.md#Badges [sponsor]: https://github.com/sponsors/XAMPPRocky ## What's New? - [Added `-n/--num-format=[commas, dots, plain, underscores]` for adding separator formatting for numbers.](https://github.com/XAMPPRocky/tokei/pull/591) - [The total is now included in output formats such as JSON.](https://github.com/XAMPPRocky/tokei/pull/580) - [`--no-ignore` now implies other ignore flags.](https://github.com/XAMPPRocky/tokei/pull/588) - [Added `--no-ignore-dot` flag to ignore files such as `.ignore`.](https://github.com/XAMPPRocky/tokei/pull/588) - [Added single line comments to F\*](https://github.com/XAMPPRocky/tokei/pull/670) - Updated various dependencies. ### Added Languages - [ABNF](https://github.com/XAMPPRocky/tokei/pull/577) - [CodeQL](https://github.com/XAMPPRocky/tokei/pull/604) - [LiveScript](https://github.com/XAMPPRocky/tokei/pull/607) - [Stylus](https://github.com/XAMPPRocky/tokei/pull/619) - [DAML](https://github.com/XAMPPRocky/tokei/pull/620) - [Tera](https://github.com/XAMPPRocky/tokei/pull/627) - [TTCN-3](https://github.com/XAMPPRocky/tokei/pull/621) - [Beancount](https://github.com/XAMPPRocky/tokei/pull/630) - [Gleam](https://github.com/XAMPPRocky/tokei/pull/646) - [JSONNet](https://github.com/XAMPPRocky/tokei/pull/634) - [Stan](https://github.com/XAMPPRocky/tokei/pull/633) - [Gwion](https://github.com/XAMPPRocky/tokei/pull/659) # 12.0.0 ## What's New? Tokei 12 comes with some of the biggest user facing changes since 1.0, now in the latest version tokei will now **analyse and count multiple languages embedded in your source code** as well as adding support for **Jupyter Notebooks**. Now for the first time is able to handle and display different languages contained in a single source file. This currently available for a limited set of languages, with plans to add more support for more in the future. The currently supported languages are; ### HTML + Siblings (Vue, Svelte, Etc...) Tokei will now analyse and report the source code contained in `<script>`, `<style>`, and `<template>` tags in HTML and other similar languages. Tokei will read the value of the`type` attribute from the `<script>` tag and detects the appropriate language based on its mime type or JavaScript if not present. Tokei will do the same for `<style>` and `<template>` except reading the `lang` attribute instead of `type` and defaulting to CSS and HTML each respectively. ### Jupyter Notebooks Tokei will now read Jupyter Notebook files (`.ipynb`) and will read the source code and markdown from Jupyter's JSON and output the analysed result. ### Markdown Tokei will now detect any code blocks marked with specified source language and count each as their respective languages or as Markdown if not present or not found. Now you can easily see how many code examples are included in your documentation. ### Rust Tokei will now detect blocks of rustdoc documentation (e.g. `///`/`//!`) and parse them as markdown. ### Verbatim Strings Tokei is now also capable of handling "verbatim" strings, which are strings that do not accept escape sequences like `\`. Thanks to @NickHackman for providing the implementation! This is initially supported for C++, C#, F#, and Rust. ## New Look To be able to show these new features, tokei's output has been changed to look like below. For brevity the CLI only displays one level deep in each language, however the library's parser is fully recursive and you can get access to the complete report using the library or by outputting the JSON format. ``` =============================================================================== Language Files Lines Code Comments Blanks =============================================================================== BASH 4 49 30 10 9 JSON 1 1332 1332 0 0 Shell 1 49 38 1 10 TOML 2 77 64 4 9 ------------------------------------------------------------------------------- Markdown 5 1230 0 965 265 |- JSON 1 41 41 0 0 |- Rust 2 53 42 6 5 |- Shell 1 22 18 0 4 (Total) 1346 101 971 274 ------------------------------------------------------------------------------- Rust 19 3349 2782 116 451 |- Markdown 12 351 5 295 51 (Total) 3700 2787 411 502 =============================================================================== Total 32 6553 4352 1397 804 =============================================================================== ``` This feature is not just limited to the default output of tokei. You can see it broken down by each file with the `--files` option. ``` =============================================================================== Language Files Lines Code Comments Blanks =============================================================================== Markdown 5 1230 0 965 265 |- JSON 1 41 41 0 0 |- Rust 2 53 42 6 5 |- Shell 1 22 18 0 4 (Total) 1346 101 971 274 ------------------------------------------------------------------------------- ./CODE_OF_CONDUCT.md 46 0 28 18 ./CHANGELOG.md 570 0 434 136 -- ./markdown.md -------------------------------------------------------------- |- Markdown 4 0 3 1 |- Rust 6 4 1 1 |- (Total) 10 4 4 2 -- ./README.md ---------------------------------------------------------------- |- Markdown 498 0 421 77 |- Shell 22 18 0 4 |- (Total) 520 18 421 81 -- ./CONTRIBUTING.md ---------------------------------------------------------- |- Markdown 112 0 79 33 |- JSON 41 41 0 0 |- Rust 46 38 4 4 |- (Total) 200 79 84 37 =============================================================================== Total 5 1346 101 971 274 =============================================================================== ``` ## Breaking Changes - The JSON Output and format of `Languages` has changed. - The JSON feature has been removed and is now included by default. - `Stats` has been split into `Report` and `CodeStats` to better represent the separation between analysing a file versus a blob of code. # 11.2.0 - @alexmaco Added shebang and env detection for Crystal. - @NickHackman Updated both Vue and HTML to count CSS & JS comments as comments. - @XAMPPRocky renamed Perl6's display name to Rakudo. - @dbackeus Added `erb` extension for Ruby HTML. - @kobataiwan Tokei will now check for a configuration file in your home directory as well as your current and configuration directory. - @dependabot Updated dependencies **Added Languages** - @alexmaco Dhall - @NickHackman Svelte - @athas Futhark - @morphy2k Gohtml - @LucasMW Headache - @rosasynstylae Tsx - @XAMPPRocky OpenType Feature Files # 11.1.0 **Added Languages** - @rubdos Arduino - @LuqueDaniel Pan - @itkovian Ren'Py - Added `LanguageType::shebangs`, `LanguageType::from_file_extension`, and `LanguageType::from_shebang`. (@solanav) # 11.0.0 **Added languages** - @bwidawsk GNU Assembly, GDB Script - @isker Dust, Apache Velocity - @andreblanke FreeMarker Thanks to some major internal refactoring, Tokei has received significant performance improvements, and is now one of the fastest code counters across any size of codebase. With Tokei 11 showing up to 40–60% faster results than tokei's previous version. To showcase the improvements I've highlighted benchmarks of counting five differently sized codebases. Redis (~220k lines), Rust (~16M lines), and the Unreal Engine (~37.5M lines). In every one of these benchmarks Tokei 11 performed the best by a noticeable margin. *All benchmarks were done on a 15-inch MacBook Pro, with a 2.7GHz Intel Core i7 processor and 16GB 2133 MHz LPDDR3 RAM running macOS Catalina 10.15.3. Your mileage may vary, All benchmarks were done using [hyperfine], using default settings for all programs.* [hyperfine]: https://github.com/sharkdp/hyperfine ### Tokei **Note** This benchmark is not accurate due to `tokei` and `loc` both taking less than 5ms to complete, there is a high degree of error between the times and should mostly be considered equivalent. However it is included because it is notable that `scc` takes nearly 3x as long to complete on smaller codebases (~5k lines).  ### Redis 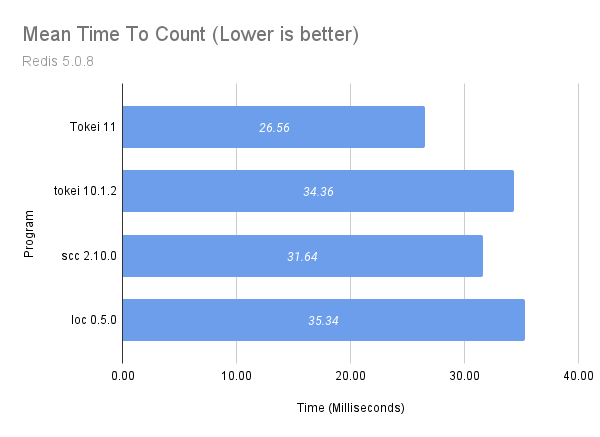 ### Rust 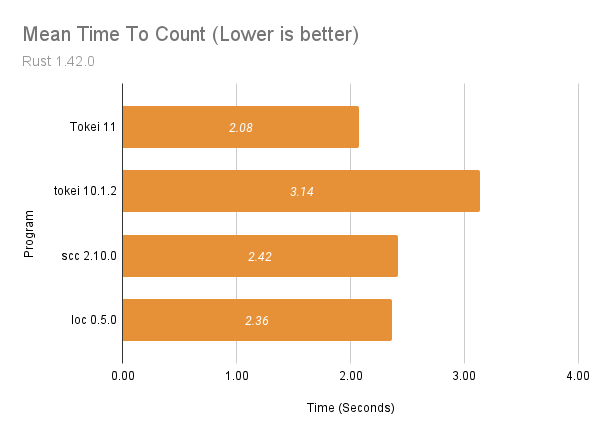 ### Unreal 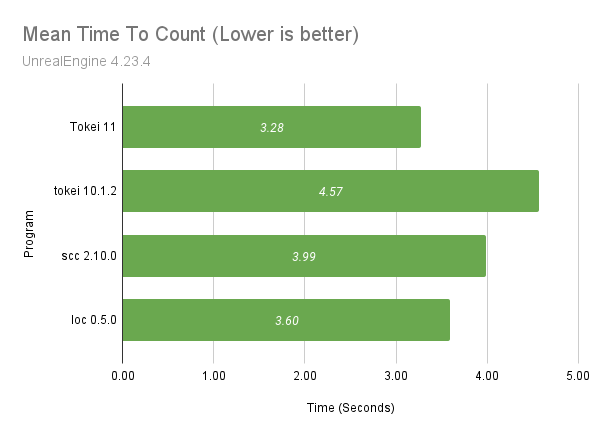 # 10.1.2 - Added `pyw` extension to Python. - Updated dependencies # 10.1.1 - Fixed `.tokeignore` always working even when `--no-ignore` is present. - Updated dependencies **Added languages** - @erikaxel Gherkin (Cucumber) # 10.1.0 - Added `cjsx` extension to CoffeeScript. - Tokei will now recognise files with `#!/usr/bin/env ruby` as Ruby. - Updated dependencies. - Tokei now uses `crossbeam` channels over `std::mpsc`, which should have a noticeable performance improvement on large repos. - Improved documentation for `libtokei`. **Added languages** - @lzybkr PowerShell - @turbo MoonScript - @dtolnay Thrift - @Tranzystorek FlatBuffers - @NieDzejkob Emojicode - @DanteFalzone0 HolyC - @sci4me Odin - @fkarg Rusty Object Notation (RON) # 10.0.0 - Fixed minor parsing bugs. - Width is now limited to 80 unless you use the `--files` flag. - Added the `mjs` extension to JavaScript. - Added the `tpp` extension to C++. - You can now disable Tokei's git ignore detection, similar to ripgrep. See `--help` for options. - You can now add a `.tokeignore` file to your project to specify file paths for tokei to always ignore. This file uses the same syntax as `.gitignore`. - Improved Pascal representation **Added languages** - @hobofan solidity - @stefanmaric GraphQL - @jhpratt PostCSS - @evitalis RPM - @alexmaco Pony - @yjhmelody WASM, LLVM, Pest - @XAMPPRocky ASN.1 # 9.0.0 - Tokei now has config files. You can now specify some commonly used arguments in a `.tokeirc`/`tokei.toml`. Namely `columns` to set the default column output, `types` to filter your count to just a single set of languages, and `treat_doc_strings_as_comments` which is a new option that allows you to specify whether to treat doc strings such as `"""` in Python as comments or code. The config files can be specified in two places, the current directory tokei is running in and your [system configuration directory](//docs.rs/tokei/struct.Config.html#method.from_config_files). The priority of options is as follows `CLI > <current_directory> > <configuration_directory>`. - Tokei is now available on [Conda](https://anaconda.org/conda-forge/tokei). - [Tokei's README has been translated to chinese.](https://github.com/chinanf-boy/tokei-zh#tokei-) - `LanguageType` now implements `Hash`. - Tokei now batches it's console output, this should result in a small performance boost. - There is now a `--columns` argument for manually setting tokei's output width. - The `--sort` argument is now case-insensitive. - Tokei will now mark languages who's files failed to parse correctly as potentially inaccurate. - Due to a bug in trust-ci `x86_64-unknown-netbsd` versions are will not be available in GitHub releases. (You will still be able to install from source.) - Due to toml-rs's lacking enum support the TOML output option has been disabled. **Added languages** - @t-richards Liquid - @diaphore Added the `.glsl` extension to GLSL. - @ahmedelgabri Twig - @pmoura Logtalk - @alekratz Perl, Not Quite Perl - @XAMPPRocky Automake, .NET Resource, HLSL, INI, Unreal Plugin, Unreal Project, Unreal Shader, Unreal Shader Header, Unreal Markdown, Visual Basic, Visual Studio Solution, Visual Studio Project, Xcode Config, - @TheMrNomis SWIG - @xnorme Added the `.vhdl` extension to VHDL # 8.0.0 - A language's comments, and quotes are now available through the `LanguageType` enum. - You can filter by language using the `-t/--type` option. e.g. `tokei -t "Rust,C"` will print only Rust and C files. - Tokei now understands terminal width and will expand to fit it. (Thanks to @Veykril) - Added [comparison](./COMPARISON.md) document to compare Tokei to other code counters. - Updated dependencies **Added languages** - @BrandonBoone VB6, VBScript, XSLT - @ialpert BrightScript - @PJB3005 Dream Maker - @schmee edn # 7.0.3 Made various optimisations, up to 65% faster in some cases. **Added languages** - @DenialAdams Added Forsyth-Edwards-Notation (FEN) - @DjebbZ Added ClojureC - @grimm26 Added HCL/Terraform # 7.0.2 - Updated dependencies. - Changed how compilied serialization formats are handled. - Fixed minor parser inaccuracies. - Tokei should now recognise more python files from their shebang. **Added languages** - @ignatenko Added Meson - @sprang Added Scheme - @fengcms Added Vue - @mark.knol Added Haxe - @rleungx Added ABAP, COBOL, and Groovy - @tiehuis Added Zig - @murielsilveira Added Mint - @notramo Added Elvish Shell and Kakoune - @aatxe Added Racket - @kamilchm Added ReasonML - @cyplp Added XSL # 7.0.1 - Updated dependencies # 7.0.0 - Fixed parsing corner cases - Changed storage of comments and quotes from `Vec` to static slices. - Added tracing for debugging single files. Not recommended for use on multiple file - Updated `log` # 6.1.0 - Fixed inaccuracies relating to the end comment being smaller than start comment. **Added languages** - @mattico Added Xaml - @weakish Added Ceylon - @theduke Added tsx extension to typescript - @vmchale Added Hamlet, Cassius, Lucius, Cabal, Nix, Happy, Alex, and Madlang - @notramo Added Crystal # 6.0.2 - Now can recognise file languages based on their filename. **Added Languages:** - @kazimuth CMake, Dockerfile, Rakefile, Scons # 6.0.1 - Multiple exclude flags now allowed. **Added Languages:** - @seiks Added Fish Shell - @XAMPPRocky Added Module-Definition - @tbu- Added Vala # 6.0.0 - Reworked internals - Now uses serde*derive(\_and thusly requires rust v1.15*) - Now has better file based testing **Added languages:** - @tuncer Added Ur/Web - @svisser Added PureScript - @tjodden Add some common extensions for HTML, C++ and Makefile - @xd009642 Added VHDL # 5.0.0 - Optimised internals **Added languages:** - @GungnirInd Added GDScript - @tuncer Differentiate between sh and Bash, Added Cogent, F\*, F# - @pthariensflame Added Agda # 4.5.0 - Added Regex based hueristics so more expensive multi line handling isn't used if there are no multi line comments in the file. - Now uses the `ignore` crate for getting files. Which now also makes determining language from path/file parallelised - File counting used to only be parallelised per language, now it is also parallelised per file per language. - Updated homepage, and documentation links - @rmbreak Tokei will now not add directories with `foo.bar` like syntax to a language. - @Michael-F-Bryan tokei will now exit gracefully when a feature is missing instead of panicking **Added languages:** - @hauleth Added Elixir support # 4.4.0 - Simplified language definitions, now consolidated into a single JSON file. - Fixed regression where lines and files weren't sorted. - @llogiq : made clippy fixes - @lligo : Added long verbose name **Added languages:** - @little-dude : Tcl(_tcl_) - @svenstaro : GLSL(_vert, tesc, tese, geom, frag, comp_) - @not-fl3 : Elm(_elm_) **Changes to existing languages:** - @xpayn : Added `pm` extension to Perl. # 4.3.0 - @lligo : Tokei no longer panics on non-character-boundary when printing file names. - Fixed regression where no comment style files(_json, markdown_) weren't counted. - Tokei can now handle files in different encodings.(_using the [encoding](https://crates.io/crates/encoding) library_) - Tokei now prints errors instead of silently skipping them. - Tokei can now print unused extensions using `-v` option. **Added languages:** - Asp(_asa, asp_) - Asp.NET(_asax, ascx, asmx, aspx, master, sitemap, webinfo_) - Hex(_hex_) - Intel Hex(_ihex_) - ReStructuredText(_rst_) - Razor(_cshtml_) **Changes to existing languages Thanks to @mwilli20 :** - Another Ada extension(_pad_) - Assembly - Uses `' '` or `" "` and added another extension(_asm_) - Bash - Uses `' '` or `" "` - Batch - They don't use quotes for strings, added `::` - Cold Fusion - Uses `' '` or `" "` - D - Uses `" "` or - Dart - Uses `" "` or `' '` or `""" """` or `''' '''` - Forth - Uses `" "` but new, doesn't have a preset - Fortrans - Use `" "` or `' '` - Idris - Uses `" "` or `""" """` - Julia - Uses `" "` or `""" """` - Kotlin - Uses `" "` or `""" """` - Lisp - Comments can be nested - Moustache - Uses `" "` or `' '` - Nim - Uses `" "` or `""" """` - Pascal - Uses `' '` - Perl - Uses `" "` or `' '` - Php - Uses `" "` or `' '` - Python - Uses `" "` or `' '` or `""" """` or `''' '''` - Ruby - Uses `" "` or `' '` - Sass - Uses `" "` or `' '` - Sql - Uses `' '` - Toml - Uses `" "` or `' '` or `""" """` or `''' '''` - Typescript - Uses `" "` or `' '` or - Vimscript - Uses `" "` or `' '` - Yaml - Uses `" "` or `' '` - Zsh - Uses `" "` or `' '` - Clojure - Removed `#` - Forth - `( Comment)` style comments need a space after the opening paren - Haskell - Has nested comments - Idris - Has nested comments - Jai - Has nested block comments - Julia - Has nested block comments - Kotlin - Has nested block comments - Pascal - Pascal should be multiline from `{` or `(*` to `}` or `*)` - Perl - Perl5 and earlier for multiline comments need `=pod` to `=cut`. - Swift - Has nested block comments ### Tokei's code count ``` ------------------------------------------------------------------------------- Language Files Lines Code Comments Blanks ------------------------------------------------------------------------------- Rust 13 2413 1596 601 216 ------------------------------------------------------------------------------- |ib\language\languages.rs 693 420 197 76 |anguage\language_type.rs 500 386 102 12 .\src\main.rs 314 256 17 41 |lib\language\language.rs 356 166 166 24 .\src\lib\utils\fs.rs 129 107 9 13 |\lib\utils\multi_line.rs 149 89 39 21 .\src\lib\utils\macros.rs 59 50 3 6 .\src\lib\stats.rs 63 45 12 6 .\src\lib\lib.rs 76 25 47 4 .\src\lib\build.rs 31 23 0 8 .\src\lib\sort.rs 28 19 6 3 .\src\lib\language\mod.rs 11 6 3 2 .\src\lib\utils\mod.rs 4 4 0 0 ------------------------------------------------------------------------------- Markdown 4 492 492 0 0 ------------------------------------------------------------------------------- .\README.md 252 252 0 0 .\CHANGELOG.md 202 202 0 0 .\CONTRIBUTING.md 25 25 0 0 .\CONTRIBUTORS.md 13 13 0 0 ------------------------------------------------------------------------------- YAML 2 70 67 3 0 ------------------------------------------------------------------------------- .\cli.yml 53 50 3 0 .\.travis.yml 17 17 0 0 ------------------------------------------------------------------------------- TOML 1 80 65 0 15 ------------------------------------------------------------------------------- .\Cargo.toml 80 65 0 15 ------------------------------------------------------------------------------- Autoconf 1 9 7 1 1 ------------------------------------------------------------------------------- .\src\lib\lib.rs.in 9 7 1 1 ------------------------------------------------------------------------------- Total 21 3064 2227 605 232 ------------------------------------------------------------------------------- ``` # 4.2.0 Tokei is now more precise, and shouldn't ever panic. Tokei now handles comments in quotes and more precise nested comments properly. Fixes #53 ### Tokei's code count. ``` ------------------------------------------------------------------------------- Language Files Lines Code Comments Blanks ------------------------------------------------------------------------------- Rust 13 2303 1487 594 222 ------------------------------------------------------------------------------- |ib\language\languages.rs 682 401 198 83 |anguage\language_type.rs 467 359 96 12 .\src\main.rs 302 243 17 42 |lib\language\language.rs 356 166 166 24 .\src\lib\utils\fs.rs 116 95 9 12 |\lib\utils\multi_line.rs 156 93 41 22 .\src\lib\stats.rs 54 36 12 6 .\src\lib\build.rs 31 23 0 8 .\src\lib\lib.rs 69 22 43 4 .\src\lib\utils\macros.rs 27 20 3 4 .\src\lib\sort.rs 28 19 6 3 .\src\lib\language\mod.rs 11 6 3 2 .\src\lib\utils\mod.rs 4 4 0 0 ------------------------------------------------------------------------------- YAML 2 68 65 3 0 ------------------------------------------------------------------------------- .\cli.yml 49 46 3 0 .\.travis.yml 19 19 0 0 ------------------------------------------------------------------------------- TOML 1 71 58 0 13 ------------------------------------------------------------------------------- .\Cargo.toml 71 58 0 13 ------------------------------------------------------------------------------- Autoconf 1 9 7 1 1 ------------------------------------------------------------------------------- .\src\lib\lib.rs.in 9 7 1 1 ------------------------------------------------------------------------------- Total 17 2451 1617 598 236 ------------------------------------------------------------------------------- ``` # 4.1.0 Tokei is now **~40%** faster. **Added languages** - Ada - Forth # 4.0.0 Tokei now has a minimal version without `serde` for faster compilation. Updated various dependencies. Internal dependencies removed. ## Regressions - CBOR is not supported till it supports `serde 0.8` **Added languages** - Handlebars # 3.0.0 Tokei is now available as a library. Tokei now has a lot more tests. Tokei now supports TOML Fixed #41 Fixed #44 Fixed #45 # 2.1.0 Tokei, can now output results in various formats(_cbor, json, yaml_) Conversely tokei can now take in results in those formats, and add them to the current run. Premilarily support for nested comments(_currently only supported for rust_) Change in the output format [PR #35](https://github.com/XAMPPRocky/tokei/pull/35) Moved `.sc` from Lisp to Scala. Internals changed to allow for multiple multi line comment formats. **Added languages:** - Isabelle # 2.0.0 Major rewrite, now parallelized. Can now support sorting files. Added a progress message for when it is counting files. Fixed #29 **Added languages:** - Coq - Erlang - Kotlin - Idris - Nim - Oz - Prolog - Qcl - Scala - Unreal Script - Wolfram # 1.6.0 Added file counting. # 1.5.0 Added Shebang support. **Added languages:** - Assembly - LD Scripts - Device Trees - Makefiles - Plain Text - C Shell # 1.4.1 Changed the formatting so tokei looks nice for consoles of 80 column width. # 1.4.0 Changed from handmade recursive file opening to [walkdir](https://github.com/BurntSushi/walkdir) 0707010000000D000081A400000000000000000000000166C8A4FD00000C95000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/CODE_OF_CONDUCT.md# Contributor Covenant Code of Conduct ## Our Pledge In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, gender identity and expression, level of experience, nationality, personal appearance, race, religion, or sexual identity and orientation. ## Our Standards Examples of behavior that contributes to creating a positive environment include: * Using welcoming and inclusive language * Being respectful of differing viewpoints and experiences * Gracefully accepting constructive criticism * Focusing on what is best for the community * Showing empathy towards other community members Examples of unacceptable behavior by participants include: * The use of sexualized language or imagery and unwelcome sexual attention or advances * Trolling, insulting/derogatory comments, and personal or political attacks * Public or private harassment * Publishing others' private information, such as a physical or electronic address, without explicit permission * Other conduct which could reasonably be considered inappropriate in a professional setting ## Our Responsibilities Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior. Project maintainers have the right and responsibility to remove, edit, or reject comments, commits, code, wiki edits, issues, and other contributions that are not aligned to this Code of Conduct, or to ban temporarily or permanently any contributor for other behaviors that they deem inappropriate, threatening, offensive, or harmful. ## Scope This Code of Conduct applies both within project spaces and in public spaces when an individual is representing the project or its community. Examples of representing a project or community include using an official project e-mail address, posting via an official social media account, or acting as an appointed representative at an online or offline event. Representation of a project may be further defined and clarified by project maintainers. ## Enforcement Instances of abusive, harassing, or otherwise unacceptable behavior may be reported by contacting the project team at xampprocky+coc@gmail.com. The project team will review and investigate all complaints, and will respond in a way that it deems appropriate to the circumstances. The project team is obligated to maintain confidentiality with regard to the reporter of an incident. Further details of specific enforcement policies may be posted separately. Project maintainers who do not follow or enforce the Code of Conduct in good faith may face temporary or permanent repercussions as determined by other members of the project's leadership. ## Attribution This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4, available at [http://contributor-covenant.org/version/1/4][version] [homepage]: http://contributor-covenant.org [version]: http://contributor-covenant.org/version/1/4/ 0707010000000E000081A400000000000000000000000166C8A4FD000013D5000000000000000000000000000000000000002A00000000tokei-13.0.0.alpha.5+git0/CONTRIBUTING.md# Contributing to Tokei - [Language Addition](#language-addition) - [Bug Reports](#bug-reports) # Language Addition Currently, Tokei generates languages from the [`languages.json`](languages.json) file. JSON was chosen to make it easy to add new languages and change code structure without changing large data structures. Here, we will go over the properties of a language in `languages.json` through examples. ```json "JavaScript": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "extensions": ["js", "mjs"] }, ``` Above is the JavaScript's definition. The first thing that needs to be defined is the key. The key's format should be same as [Rust's enum style]. As this key will be used in an enum for identifying the language. For a lot of languages, this also works for showing the language when we print to the screen. However, there are some languages whose names don't work with the enum style. For example, `JSON` is usually shown in all caps, but that doesn't fit in Rust's enum style. So we have an additional optional field called `name` which defines how the language should look when displayed to the user. ```json "Json": { "name": "JSON", //... }, ``` For defining comments, there are a few properties. The most commonly used property is `line_comment` which defines single line comments. These are comments which don't continue onto the next line. Here is an example in Rust: ```rust let x = 5; // default x position let y = 0; // default y position ``` The `line_comment` property expects an array of strings, as some languages have multiple syntaxes for defining a single line comment. For example, `PHP` allows both `#` and `//` for single line comments. ```json "Php": { "line_comment": [ "#", "//" ], //... }, ``` For defining comments that also have an ending syntax, there is the `multi_line` property. An example for such comments in Rust: ```rust let x = /* There is a reason for this comment, I swear! */ 10; ``` The `verbatim_quotes` property expects an array of strings, as some languages have multiple syntaxes for defining verbatim strings. A verbatim string in the context of Tokei is a string literal that can have unescaped `"`s. For example [`CSharp`](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/strings/#regular-and-verbatim-string-literals) ```json "CSharp": { "verbatim_quotes": [ [ "@\\\"", "\\\"" ] ], //... }, ``` ```csharp const string BasePath = @"C:\"; ``` Some languages have a single, standard filename with no extension like `Makefile` or `Dockerfile`. These can be defined with the `filenames` property: ```json "Makefile": { "filenames": [ "makefile" ], "extensions": [ "makefile", "mak", "mk" ] }, ``` Filenames should be all-lowercase, whether or not the filename typically has capital letters included. Note that filenames will **override** extensions. With the following definition, a file named `CMakeLists.txt` will be detected as a `CMake` file, not a `Text` file. ```json "Text": { "extensions": [ "txt" ] }, "CMake": { "filenames": [ "cmakelists.txt" ] }, ``` # Tests A test file is required for language additions. The file should contain every variant comments and quotes, as well as a comment at the top of the file containing the manually verified lines, code, comments, blanks in the following format: ``` NUM lines NUM code NUM comments NUM blanks ``` ### Example In Rust for example, the first line should look like the following: ```rust //! 39 lines 32 code 2 comments 5 blanks ``` The comment should use the syntax of the language you're testing. A good example of a test file is [`tests/data/rust.rs`](tests/data/rust.rs). ```rust //! 48 lines 36 code 6 comments 6 blanks //! ```rust //! fn main () { //! // Comment //! //! println!("Hello World!"); //! } //! ``` /* /**/ */ fn main() { let start = r##"/*##\" \"##; // comment loop { if x.len() >= 2 && x[0] == '*' && x[1] == '/' { // found the */ break; } } } fn foo<'a, 'b>(name: &'b str) { let this_ends = "a \"test/*."; call1(); call2(); let this_does_not = /* a /* nested */ comment " */ "*/another /*test call3(); */"; } fn foobar() { let does_not_start = // " "until here, test/* test"; // a quote: " let also_doesnt_start = /* " */ "until here, test,*/ test"; // another quote: " } fn foo() { let a = 4; // /* let b = 5; let c = 6; // */ } ``` # Bug Reports Please include the error message and a minimum working example including the file or file structure. ```` This file crashes the program: <filename> ``` <file/file structure> ``` ```` [Rust's enum style]: https://github.com/rust-lang/rfcs/blob/master/text/0430-finalizing-naming-conventions.md#general-naming-conventions 0707010000000F000081A400000000000000000000000166C8A4FD0000BA25000000000000000000000000000000000000002500000000tokei-13.0.0.alpha.5+git0/Cargo.lock# This file is automatically @generated by Cargo. # It is not intended for manual editing. version = 3 [[package]] name = "aho-corasick" version = "1.1.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "8e60d3430d3a69478ad0993f19238d2df97c507009a52b3c10addcd7f6bcb916" dependencies = [ "memchr", ] [[package]] name = "android-tzdata" version = "0.1.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e999941b234f3131b00bc13c22d06e8c5ff726d1b6318ac7eb276997bbb4fef0" [[package]] name = "android_system_properties" version = "0.1.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "819e7219dbd41043ac279b19830f2efc897156490d7fd6ea916720117ee66311" dependencies = [ "libc", ] [[package]] name = "anstream" version = "0.6.15" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "64e15c1ab1f89faffbf04a634d5e1962e9074f2741eef6d97f3c4e322426d526" dependencies = [ "anstyle", "anstyle-parse", "anstyle-query", "anstyle-wincon", "colorchoice", "is_terminal_polyfill", "utf8parse", ] [[package]] name = "anstyle" version = "1.0.8" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1bec1de6f59aedf83baf9ff929c98f2ad654b97c9510f4e70cf6f661d49fd5b1" [[package]] name = "anstyle-parse" version = "0.2.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "eb47de1e80c2b463c735db5b217a0ddc39d612e7ac9e2e96a5aed1f57616c1cb" dependencies = [ "utf8parse", ] [[package]] name = "anstyle-query" version = "1.1.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "6d36fc52c7f6c869915e99412912f22093507da8d9e942ceaf66fe4b7c14422a" dependencies = [ "windows-sys 0.52.0", ] [[package]] name = "anstyle-wincon" version = "3.0.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "5bf74e1b6e971609db8ca7a9ce79fd5768ab6ae46441c572e46cf596f59e57f8" dependencies = [ "anstyle", "windows-sys 0.52.0", ] [[package]] name = "arbitrary" version = "1.3.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "7d5a26814d8dcb93b0e5a0ff3c6d80a8843bafb21b39e8e18a6f05471870e110" dependencies = [ "derive_arbitrary", ] [[package]] name = "arrayvec" version = "0.7.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "7c02d123df017efcdfbd739ef81735b36c5ba83ec3c59c80a9d7ecc718f92e50" [[package]] name = "autocfg" version = "1.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0c4b4d0bd25bd0b74681c0ad21497610ce1b7c91b1022cd21c80c6fbdd9476b0" [[package]] name = "bit-set" version = "0.5.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0700ddab506f33b20a03b13996eccd309a48e5ff77d0d95926aa0210fb4e95f1" dependencies = [ "bit-vec", ] [[package]] name = "bit-vec" version = "0.6.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "349f9b6a179ed607305526ca489b34ad0a41aed5f7980fa90eb03160b69598fb" [[package]] name = "bitflags" version = "2.6.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b048fb63fd8b5923fc5aa7b340d8e156aec7ec02f0c78fa8a6ddc2613f6f71de" [[package]] name = "block-buffer" version = "0.10.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3078c7629b62d3f0439517fa394996acacc5cbc91c5a20d8c658e77abd503a71" dependencies = [ "generic-array", ] [[package]] name = "bstr" version = "1.10.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "40723b8fb387abc38f4f4a37c09073622e41dd12327033091ef8950659e6dc0c" dependencies = [ "memchr", "serde", ] [[package]] name = "bumpalo" version = "3.16.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "79296716171880943b8470b5f8d03aa55eb2e645a4874bdbb28adb49162e012c" [[package]] name = "byteorder" version = "1.5.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1fd0f2584146f6f2ef48085050886acf353beff7305ebd1ae69500e27c67f64b" [[package]] name = "cc" version = "1.1.13" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "72db2f7947ecee9b03b510377e8bb9077afa27176fdbff55c51027e976fdcc48" dependencies = [ "jobserver", "libc", "shlex", ] [[package]] name = "cfg-if" version = "1.0.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "baf1de4339761588bc0619e3cbc0120ee582ebb74b53b4efbf79117bd2da40fd" [[package]] name = "chrono" version = "0.4.38" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a21f936df1771bf62b77f047b726c4625ff2e8aa607c01ec06e5a05bd8463401" dependencies = [ "android-tzdata", "iana-time-zone", "num-traits", "windows-targets 0.52.6", ] [[package]] name = "chrono-tz" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "93698b29de5e97ad0ae26447b344c482a7284c737d9ddc5f9e52b74a336671bb" dependencies = [ "chrono", "chrono-tz-build", "phf", ] [[package]] name = "chrono-tz-build" version = "0.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0c088aee841df9c3041febbb73934cfc39708749bf96dc827e3359cd39ef11b1" dependencies = [ "parse-zoneinfo", "phf", "phf_codegen", ] [[package]] name = "clap" version = "4.5.16" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ed6719fffa43d0d87e5fd8caeab59be1554fb028cd30edc88fc4369b17971019" dependencies = [ "clap_builder", ] [[package]] name = "clap_builder" version = "4.5.15" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "216aec2b177652e3846684cbfe25c9964d18ec45234f0f5da5157b207ed1aab6" dependencies = [ "anstream", "anstyle", "clap_lex", "strsim", "terminal_size", ] [[package]] name = "clap_lex" version = "0.7.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1462739cb27611015575c0c11df5df7601141071f07518d56fcc1be504cbec97" [[package]] name = "colorchoice" version = "1.0.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d3fd119d74b830634cea2a0f58bbd0d54540518a14397557951e79340abc28c0" [[package]] name = "colored" version = "2.1.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cbf2150cce219b664a8a70df7a1f933836724b503f8a413af9365b4dcc4d90b8" dependencies = [ "lazy_static", "windows-sys 0.48.0", ] [[package]] name = "core-foundation-sys" version = "0.8.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "773648b94d0e5d620f64f280777445740e61fe701025087ec8b57f45c791888b" [[package]] name = "cpufeatures" version = "0.2.13" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "51e852e6dc9a5bed1fae92dd2375037bf2b768725bf3be87811edee3249d09ad" dependencies = [ "libc", ] [[package]] name = "crossbeam-channel" version = "0.5.13" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "33480d6946193aa8033910124896ca395333cae7e2d1113d1fef6c3272217df2" dependencies = [ "crossbeam-utils", ] [[package]] name = "crossbeam-deque" version = "0.8.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "613f8cc01fe9cf1a3eb3d7f488fd2fa8388403e97039e2f73692932e291a770d" dependencies = [ "crossbeam-epoch", "crossbeam-utils", ] [[package]] name = "crossbeam-epoch" version = "0.9.18" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "5b82ac4a3c2ca9c3460964f020e1402edd5753411d7737aa39c3714ad1b5420e" dependencies = [ "crossbeam-utils", ] [[package]] name = "crossbeam-utils" version = "0.8.20" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "22ec99545bb0ed0ea7bb9b8e1e9122ea386ff8a48c0922e43f36d45ab09e0e80" [[package]] name = "crypto-common" version = "0.1.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1bfb12502f3fc46cca1bb51ac28df9d618d813cdc3d2f25b9fe775a34af26bb3" dependencies = [ "generic-array", "typenum", ] [[package]] name = "dashmap" version = "6.0.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "804c8821570c3f8b70230c2ba75ffa5c0f9a4189b9a432b6656c536712acae28" dependencies = [ "cfg-if", "crossbeam-utils", "hashbrown", "lock_api", "once_cell", "parking_lot_core", "serde", ] [[package]] name = "derive_arbitrary" version = "1.3.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "67e77553c4162a157adbf834ebae5b415acbecbeafc7a74b0e886657506a7611" dependencies = [ "proc-macro2", "quote", "syn", ] [[package]] name = "deunicode" version = "1.6.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "339544cc9e2c4dc3fc7149fd630c5f22263a4fdf18a98afd0075784968b5cf00" [[package]] name = "digest" version = "0.10.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9ed9a281f7bc9b7576e61468ba615a66a5c8cfdff42420a70aa82701a3b1e292" dependencies = [ "block-buffer", "crypto-common", ] [[package]] name = "either" version = "1.13.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "60b1af1c220855b6ceac025d3f6ecdd2b7c4894bfe9cd9bda4fbb4bc7c0d4cf0" [[package]] name = "encoding_rs" version = "0.8.34" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b45de904aa0b010bce2ab45264d0631681847fa7b6f2eaa7dab7619943bc4f59" dependencies = [ "cfg-if", ] [[package]] name = "encoding_rs_io" version = "0.1.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1cc3c5651fb62ab8aa3103998dade57efdd028544bd300516baa31840c252a83" dependencies = [ "encoding_rs", ] [[package]] name = "env_filter" version = "0.1.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "4f2c92ceda6ceec50f43169f9ee8424fe2db276791afde7b2cd8bc084cb376ab" dependencies = [ "log", "regex", ] [[package]] name = "env_logger" version = "0.11.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e13fa619b91fb2381732789fc5de83b45675e882f66623b7d8cb4f643017018d" dependencies = [ "anstream", "anstyle", "env_filter", "humantime", "log", ] [[package]] name = "equivalent" version = "1.0.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "5443807d6dff69373d433ab9ef5378ad8df50ca6298caf15de6e52e24aaf54d5" [[package]] name = "errno" version = "0.3.9" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "534c5cf6194dfab3db3242765c03bbe257cf92f22b38f6bc0c58d59108a820ba" dependencies = [ "libc", "windows-sys 0.52.0", ] [[package]] name = "etcetera" version = "0.8.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "136d1b5283a1ab77bd9257427ffd09d8667ced0570b6f938942bc7568ed5b943" dependencies = [ "cfg-if", "home", "windows-sys 0.48.0", ] [[package]] name = "fastrand" version = "2.1.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9fc0510504f03c51ada170672ac806f1f105a88aa97a5281117e1ddc3368e51a" [[package]] name = "fnv" version = "1.0.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3f9eec918d3f24069decb9af1554cad7c880e2da24a9afd88aca000531ab82c1" [[package]] name = "form_urlencoded" version = "1.2.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e13624c2627564efccf4934284bdd98cbaa14e79b0b5a141218e507b3a823456" dependencies = [ "percent-encoding", ] [[package]] name = "generic-array" version = "0.14.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "85649ca51fd72272d7821adaf274ad91c288277713d9c18820d8499a7ff69e9a" dependencies = [ "typenum", "version_check", ] [[package]] name = "getrandom" version = "0.2.15" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c4567c8db10ae91089c99af84c68c38da3ec2f087c3f82960bcdbf3656b6f4d7" dependencies = [ "cfg-if", "libc", "wasi", ] [[package]] name = "git2" version = "0.19.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b903b73e45dc0c6c596f2d37eccece7c1c8bb6e4407b001096387c63d0d93724" dependencies = [ "bitflags", "libc", "libgit2-sys", "log", "url", ] [[package]] name = "globset" version = "0.4.14" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "57da3b9b5b85bd66f31093f8c408b90a74431672542466497dcbdfdc02034be1" dependencies = [ "aho-corasick", "bstr", "log", "regex-automata", "regex-syntax", ] [[package]] name = "globwalk" version = "0.9.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0bf760ebf69878d9fd8f110c89703d90ce35095324d1f1edcb595c63945ee757" dependencies = [ "bitflags", "ignore", "walkdir", ] [[package]] name = "grep-matcher" version = "0.1.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "47a3141a10a43acfedc7c98a60a834d7ba00dfe7bec9071cbfc19b55b292ac02" dependencies = [ "memchr", ] [[package]] name = "grep-searcher" version = "0.1.13" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ba536ae4f69bec62d8839584dd3153d3028ef31bb229f04e09fb5a9e5a193c54" dependencies = [ "bstr", "encoding_rs", "encoding_rs_io", "grep-matcher", "log", "memchr", "memmap2", ] [[package]] name = "half" version = "1.8.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1b43ede17f21864e81be2fa654110bf1e793774238d86ef8555c37e6519c0403" [[package]] name = "hashbrown" version = "0.14.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e5274423e17b7c9fc20b6e7e208532f9b19825d82dfd615708b70edd83df41f1" [[package]] name = "heck" version = "0.5.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2304e00983f87ffb38b55b444b5e3b60a884b5d30c0fca7d82fe33449bbe55ea" [[package]] name = "hex" version = "0.4.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "7f24254aa9a54b5c858eaee2f5bccdb46aaf0e486a595ed5fd8f86ba55232a70" [[package]] name = "home" version = "0.5.9" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e3d1354bf6b7235cb4a0576c2619fd4ed18183f689b12b006a0ee7329eeff9a5" dependencies = [ "windows-sys 0.52.0", ] [[package]] name = "humansize" version = "2.1.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "6cb51c9a029ddc91b07a787f1d86b53ccfa49b0e86688c946ebe8d3555685dd7" dependencies = [ "libm", ] [[package]] name = "humantime" version = "2.1.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9a3a5bfb195931eeb336b2a7b4d761daec841b97f947d34394601737a7bba5e4" [[package]] name = "iana-time-zone" version = "0.1.60" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e7ffbb5a1b541ea2561f8c41c087286cc091e21e556a4f09a8f6cbf17b69b141" dependencies = [ "android_system_properties", "core-foundation-sys", "iana-time-zone-haiku", "js-sys", "wasm-bindgen", "windows-core", ] [[package]] name = "iana-time-zone-haiku" version = "0.1.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "f31827a206f56af32e590ba56d5d2d085f558508192593743f16b2306495269f" dependencies = [ "cc", ] [[package]] name = "idna" version = "0.5.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "634d9b1461af396cad843f47fdba5597a4f9e6ddd4bfb6ff5d85028c25cb12f6" dependencies = [ "unicode-bidi", "unicode-normalization", ] [[package]] name = "ignore" version = "0.4.22" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b46810df39e66e925525d6e38ce1e7f6e1d208f72dc39757880fcb66e2c58af1" dependencies = [ "crossbeam-deque", "globset", "log", "memchr", "regex-automata", "same-file", "walkdir", "winapi-util", ] [[package]] name = "indexmap" version = "2.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "93ead53efc7ea8ed3cfb0c79fc8023fbb782a5432b52830b6518941cebe6505c" dependencies = [ "equivalent", "hashbrown", ] [[package]] name = "is_terminal_polyfill" version = "1.70.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "7943c866cc5cd64cbc25b2e01621d07fa8eb2a1a23160ee81ce38704e97b8ecf" [[package]] name = "itertools" version = "0.11.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b1c173a5686ce8bfa551b3563d0c2170bf24ca44da99c7ca4bfdab5418c3fe57" dependencies = [ "either", ] [[package]] name = "itoa" version = "1.0.11" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "49f1f14873335454500d59611f1cf4a4b0f786f9ac11f4312a78e4cf2566695b" [[package]] name = "jobserver" version = "0.1.32" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "48d1dbcbbeb6a7fec7e059840aa538bd62aaccf972c7346c4d9d2059312853d0" dependencies = [ "libc", ] [[package]] name = "js-sys" version = "0.3.70" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1868808506b929d7b0cfa8f75951347aa71bb21144b7791bae35d9bccfcfe37a" dependencies = [ "wasm-bindgen", ] [[package]] name = "json5" version = "0.4.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "96b0db21af676c1ce64250b5f40f3ce2cf27e4e47cb91ed91eb6fe9350b430c1" dependencies = [ "pest", "pest_derive", "serde", ] [[package]] name = "lazy_static" version = "1.5.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "bbd2bcb4c963f2ddae06a2efc7e9f3591312473c50c6685e1f298068316e66fe" [[package]] name = "libc" version = "0.2.156" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a5f43f184355eefb8d17fc948dbecf6c13be3c141f20d834ae842193a448c72a" [[package]] name = "libgit2-sys" version = "0.17.0+1.8.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "10472326a8a6477c3c20a64547b0059e4b0d086869eee31e6d7da728a8eb7224" dependencies = [ "cc", "libc", "libz-sys", "pkg-config", ] [[package]] name = "libm" version = "0.2.8" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "4ec2a862134d2a7d32d7983ddcdd1c4923530833c9f2ea1a44fc5fa473989058" [[package]] name = "libz-sys" version = "1.1.19" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "fdc53a7799a7496ebc9fd29f31f7df80e83c9bda5299768af5f9e59eeea74647" dependencies = [ "cc", "libc", "pkg-config", "vcpkg", ] [[package]] name = "linux-raw-sys" version = "0.4.14" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "78b3ae25bc7c8c38cec158d1f2757ee79e9b3740fbc7ccf0e59e4b08d793fa89" [[package]] name = "lock_api" version = "0.4.12" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "07af8b9cdd281b7915f413fa73f29ebd5d55d0d3f0155584dade1ff18cea1b17" dependencies = [ "autocfg", "scopeguard", ] [[package]] name = "log" version = "0.4.22" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a7a70ba024b9dc04c27ea2f0c0548feb474ec5c54bba33a7f72f873a39d07b24" [[package]] name = "memchr" version = "2.7.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "78ca9ab1a0babb1e7d5695e3530886289c18cf2f87ec19a575a0abdce112e3a3" [[package]] name = "memmap2" version = "0.9.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "fe751422e4a8caa417e13c3ea66452215d7d63e19e604f4980461212f3ae1322" dependencies = [ "libc", ] [[package]] name = "num-format" version = "0.4.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a652d9771a63711fd3c3deb670acfbe5c30a4072e664d7a3bf5a9e1056ac72c3" dependencies = [ "arrayvec", "itoa", ] [[package]] name = "num-traits" version = "0.2.19" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "071dfc062690e90b734c0b2273ce72ad0ffa95f0c74596bc250dcfd960262841" dependencies = [ "autocfg", "libm", ] [[package]] name = "once_cell" version = "1.19.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3fdb12b2476b595f9358c5161aa467c2438859caa136dec86c26fdd2efe17b92" [[package]] name = "parking_lot" version = "0.12.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "f1bf18183cf54e8d6059647fc3063646a1801cf30896933ec2311622cc4b9a27" dependencies = [ "lock_api", "parking_lot_core", ] [[package]] name = "parking_lot_core" version = "0.9.10" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1e401f977ab385c9e4e3ab30627d6f26d00e2c73eef317493c4ec6d468726cf8" dependencies = [ "cfg-if", "libc", "redox_syscall", "smallvec", "windows-targets 0.52.6", ] [[package]] name = "parse-zoneinfo" version = "0.3.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1f2a05b18d44e2957b88f96ba460715e295bc1d7510468a2f3d3b44535d26c24" dependencies = [ "regex", ] [[package]] name = "percent-encoding" version = "2.3.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e3148f5046208a5d56bcfc03053e3ca6334e51da8dfb19b6cdc8b306fae3283e" [[package]] name = "pest" version = "2.7.11" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cd53dff83f26735fdc1ca837098ccf133605d794cdae66acfc2bfac3ec809d95" dependencies = [ "memchr", "thiserror", "ucd-trie", ] [[package]] name = "pest_derive" version = "2.7.11" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2a548d2beca6773b1c244554d36fcf8548a8a58e74156968211567250e48e49a" dependencies = [ "pest", "pest_generator", ] [[package]] name = "pest_generator" version = "2.7.11" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3c93a82e8d145725dcbaf44e5ea887c8a869efdcc28706df2d08c69e17077183" dependencies = [ "pest", "pest_meta", "proc-macro2", "quote", "syn", ] [[package]] name = "pest_meta" version = "2.7.11" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a941429fea7e08bedec25e4f6785b6ffaacc6b755da98df5ef3e7dcf4a124c4f" dependencies = [ "once_cell", "pest", "sha2", ] [[package]] name = "phf" version = "0.11.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ade2d8b8f33c7333b51bcf0428d37e217e9f32192ae4772156f65063b8ce03dc" dependencies = [ "phf_shared", ] [[package]] name = "phf_codegen" version = "0.11.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e8d39688d359e6b34654d328e262234662d16cc0f60ec8dcbe5e718709342a5a" dependencies = [ "phf_generator", "phf_shared", ] [[package]] name = "phf_generator" version = "0.11.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "48e4cc64c2ad9ebe670cb8fd69dd50ae301650392e81c05f9bfcb2d5bdbc24b0" dependencies = [ "phf_shared", "rand", ] [[package]] name = "phf_shared" version = "0.11.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "90fcb95eef784c2ac79119d1dd819e162b5da872ce6f3c3abe1e8ca1c082f72b" dependencies = [ "siphasher", ] [[package]] name = "pkg-config" version = "0.3.30" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d231b230927b5e4ad203db57bbcbee2802f6bce620b1e4a9024a07d94e2907ec" [[package]] name = "ppv-lite86" version = "0.2.20" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "77957b295656769bb8ad2b6a6b09d897d94f05c41b069aede1fcdaa675eaea04" dependencies = [ "zerocopy", ] [[package]] name = "proc-macro2" version = "1.0.86" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "5e719e8df665df0d1c8fbfd238015744736151d4445ec0836b8e628aae103b77" dependencies = [ "unicode-ident", ] [[package]] name = "proptest" version = "1.5.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b4c2511913b88df1637da85cc8d96ec8e43a3f8bb8ccb71ee1ac240d6f3df58d" dependencies = [ "bit-set", "bit-vec", "bitflags", "lazy_static", "num-traits", "rand", "rand_chacha", "rand_xorshift", "regex-syntax", "rusty-fork", "tempfile", "unarray", ] [[package]] name = "quick-error" version = "1.2.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a1d01941d82fa2ab50be1e79e6714289dd7cde78eba4c074bc5a4374f650dfe0" [[package]] name = "quote" version = "1.0.36" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0fa76aaf39101c457836aec0ce2316dbdc3ab723cdda1c6bd4e6ad4208acaca7" dependencies = [ "proc-macro2", ] [[package]] name = "rand" version = "0.8.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "34af8d1a0e25924bc5b7c43c079c942339d8f0a8b57c39049bef581b46327404" dependencies = [ "libc", "rand_chacha", "rand_core", ] [[package]] name = "rand_chacha" version = "0.3.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e6c10a63a0fa32252be49d21e7709d4d4baf8d231c2dbce1eaa8141b9b127d88" dependencies = [ "ppv-lite86", "rand_core", ] [[package]] name = "rand_core" version = "0.6.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ec0be4795e2f6a28069bec0b5ff3e2ac9bafc99e6a9a7dc3547996c5c816922c" dependencies = [ "getrandom", ] [[package]] name = "rand_xorshift" version = "0.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d25bf25ec5ae4a3f1b92f929810509a2f53d7dca2f50b794ff57e3face536c8f" dependencies = [ "rand_core", ] [[package]] name = "rayon" version = "1.10.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b418a60154510ca1a002a752ca9714984e21e4241e804d32555251faf8b78ffa" dependencies = [ "either", "rayon-core", ] [[package]] name = "rayon-core" version = "1.12.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1465873a3dfdaa8ae7cb14b4383657caab0b3e8a0aa9ae8e04b044854c8dfce2" dependencies = [ "crossbeam-deque", "crossbeam-utils", ] [[package]] name = "redox_syscall" version = "0.5.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2a908a6e00f1fdd0dfd9c0eb08ce85126f6d8bbda50017e74bc4a4b7d4a926a4" dependencies = [ "bitflags", ] [[package]] name = "regex" version = "1.10.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "4219d74c6b67a3654a9fbebc4b419e22126d13d2f3c4a07ee0cb61ff79a79619" dependencies = [ "aho-corasick", "memchr", "regex-automata", "regex-syntax", ] [[package]] name = "regex-automata" version = "0.4.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "38caf58cc5ef2fed281f89292ef23f6365465ed9a41b7a7754eb4e26496c92df" dependencies = [ "aho-corasick", "memchr", "regex-syntax", ] [[package]] name = "regex-syntax" version = "0.8.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "7a66a03ae7c801facd77a29370b4faec201768915ac14a721ba36f20bc9c209b" [[package]] name = "rustix" version = "0.38.34" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "70dc5ec042f7a43c4a73241207cecc9873a06d45debb38b329f8541d85c2730f" dependencies = [ "bitflags", "errno", "libc", "linux-raw-sys", "windows-sys 0.52.0", ] [[package]] name = "rustversion" version = "1.0.17" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "955d28af4278de8121b7ebeb796b6a45735dc01436d898801014aced2773a3d6" [[package]] name = "rusty-fork" version = "0.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cb3dcc6e454c328bb824492db107ab7c0ae8fcffe4ad210136ef014458c1bc4f" dependencies = [ "fnv", "quick-error", "tempfile", "wait-timeout", ] [[package]] name = "ryu" version = "1.0.18" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "f3cb5ba0dc43242ce17de99c180e96db90b235b8a9fdc9543c96d2209116bd9f" [[package]] name = "same-file" version = "1.0.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "93fc1dc3aaa9bfed95e02e6eadabb4baf7e3078b0bd1b4d7b6b0b68378900502" dependencies = [ "winapi-util", ] [[package]] name = "scopeguard" version = "1.2.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "94143f37725109f92c262ed2cf5e59bce7498c01bcc1502d7b9afe439a4e9f49" [[package]] name = "serde" version = "1.0.208" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cff085d2cb684faa248efb494c39b68e522822ac0de72ccf08109abde717cfb2" dependencies = [ "serde_derive", ] [[package]] name = "serde_cbor" version = "0.11.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2bef2ebfde456fb76bbcf9f59315333decc4fda0b2b44b420243c11e0f5ec1f5" dependencies = [ "half", "serde", ] [[package]] name = "serde_derive" version = "1.0.208" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "24008e81ff7613ed8e5ba0cfaf24e2c2f1e5b8a0495711e44fcd4882fca62bcf" dependencies = [ "proc-macro2", "quote", "syn", ] [[package]] name = "serde_json" version = "1.0.125" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "83c8e735a073ccf5be70aa8066aa984eaf2fa000db6c8d0100ae605b366d31ed" dependencies = [ "itoa", "memchr", "ryu", "serde", ] [[package]] name = "serde_spanned" version = "0.6.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "eb5b1b31579f3811bf615c144393417496f152e12ac8b7663bf664f4a815306d" dependencies = [ "serde", ] [[package]] name = "serde_yaml" version = "0.9.34+deprecated" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "6a8b1a1a2ebf674015cc02edccce75287f1a0130d394307b36743c2f5d504b47" dependencies = [ "indexmap", "itoa", "ryu", "serde", "unsafe-libyaml", ] [[package]] name = "sha2" version = "0.10.8" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "793db75ad2bcafc3ffa7c68b215fee268f537982cd901d132f89c6343f3a3dc8" dependencies = [ "cfg-if", "cpufeatures", "digest", ] [[package]] name = "shlex" version = "1.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0fda2ff0d084019ba4d7c6f371c95d8fd75ce3524c3cb8fb653a3023f6323e64" [[package]] name = "siphasher" version = "0.3.11" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "38b58827f4464d87d377d175e90bf58eb00fd8716ff0a62f80356b5e61555d0d" [[package]] name = "slug" version = "0.1.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "882a80f72ee45de3cc9a5afeb2da0331d58df69e4e7d8eeb5d3c7784ae67e724" dependencies = [ "deunicode", "wasm-bindgen", ] [[package]] name = "smallvec" version = "1.13.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3c5e1a9a646d36c3599cd173a41282daf47c44583ad367b8e6837255952e5c67" [[package]] name = "strsim" version = "0.11.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "7da8b5736845d9f2fcb837ea5d9e2628564b3b043a70948a3f0b778838c5fb4f" [[package]] name = "strum" version = "0.26.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "8fec0f0aef304996cf250b31b5a10dee7980c85da9d759361292b8bca5a18f06" [[package]] name = "strum_macros" version = "0.26.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "4c6bee85a5a24955dc440386795aa378cd9cf82acd5f764469152d2270e581be" dependencies = [ "heck", "proc-macro2", "quote", "rustversion", "syn", ] [[package]] name = "syn" version = "2.0.74" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1fceb41e3d546d0bd83421d3409b1460cc7444cd389341a4c880fe7a042cb3d7" dependencies = [ "proc-macro2", "quote", "unicode-ident", ] [[package]] name = "table_formatter" version = "0.6.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "beef5d3fd5472c911d41286849de6a9aee93327f7fae9fb9148fe9ff0102c17d" dependencies = [ "colored", "itertools", "thiserror", ] [[package]] name = "tempfile" version = "3.12.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "04cbcdd0c794ebb0d4cf35e88edd2f7d2c4c3e9a5a6dab322839b321c6a87a64" dependencies = [ "cfg-if", "fastrand", "once_cell", "rustix", "windows-sys 0.59.0", ] [[package]] name = "tera" version = "1.20.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ab9d851b45e865f178319da0abdbfe6acbc4328759ff18dafc3a41c16b4cd2ee" dependencies = [ "chrono", "chrono-tz", "globwalk", "humansize", "lazy_static", "percent-encoding", "pest", "pest_derive", "rand", "regex", "serde", "serde_json", "slug", "unic-segment", ] [[package]] name = "term_size" version = "0.3.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1e4129646ca0ed8f45d09b929036bafad5377103edd06e50bf574b353d2b08d9" dependencies = [ "libc", "winapi", ] [[package]] name = "terminal_size" version = "0.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "21bebf2b7c9e0a515f6e0f8c51dc0f8e4696391e6f1ff30379559f8365fb0df7" dependencies = [ "rustix", "windows-sys 0.48.0", ] [[package]] name = "thiserror" version = "1.0.63" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c0342370b38b6a11b6cc11d6a805569958d54cfa061a29969c3b5ce2ea405724" dependencies = [ "thiserror-impl", ] [[package]] name = "thiserror-impl" version = "1.0.63" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a4558b58466b9ad7ca0f102865eccc95938dca1a74a856f2b57b6629050da261" dependencies = [ "proc-macro2", "quote", "syn", ] [[package]] name = "tinyvec" version = "1.8.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "445e881f4f6d382d5f27c034e25eb92edd7c784ceab92a0937db7f2e9471b938" dependencies = [ "tinyvec_macros", ] [[package]] name = "tinyvec_macros" version = "0.1.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1f3ccbac311fea05f86f61904b462b55fb3df8837a366dfc601a0161d0532f20" [[package]] name = "tokei" version = "13.0.0-alpha.5" dependencies = [ "aho-corasick", "arbitrary", "clap", "colored", "crossbeam-channel", "dashmap", "encoding_rs_io", "env_logger", "etcetera", "git2", "grep-searcher", "hex", "ignore", "json5", "log", "num-format", "once_cell", "parking_lot", "proptest", "rayon", "regex", "serde", "serde_cbor", "serde_json", "serde_yaml", "strum", "strum_macros", "table_formatter", "tempfile", "tera", "term_size", "toml", ] [[package]] name = "toml" version = "0.8.19" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a1ed1f98e3fdc28d6d910e6737ae6ab1a93bf1985935a1193e68f93eeb68d24e" dependencies = [ "serde", "serde_spanned", "toml_datetime", "toml_edit", ] [[package]] name = "toml_datetime" version = "0.6.8" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0dd7358ecb8fc2f8d014bf86f6f638ce72ba252a2c3a2572f2a795f1d23efb41" dependencies = [ "serde", ] [[package]] name = "toml_edit" version = "0.22.20" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "583c44c02ad26b0c3f3066fe629275e50627026c51ac2e595cca4c230ce1ce1d" dependencies = [ "indexmap", "serde", "serde_spanned", "toml_datetime", "winnow", ] [[package]] name = "typenum" version = "1.17.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "42ff0bf0c66b8238c6f3b578df37d0b7848e55df8577b3f74f92a69acceeb825" [[package]] name = "ucd-trie" version = "0.1.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ed646292ffc8188ef8ea4d1e0e0150fb15a5c2e12ad9b8fc191ae7a8a7f3c4b9" [[package]] name = "unarray" version = "0.1.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "eaea85b334db583fe3274d12b4cd1880032beab409c0d774be044d4480ab9a94" [[package]] name = "unic-char-property" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a8c57a407d9b6fa02b4795eb81c5b6652060a15a7903ea981f3d723e6c0be221" dependencies = [ "unic-char-range", ] [[package]] name = "unic-char-range" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0398022d5f700414f6b899e10b8348231abf9173fa93144cbc1a43b9793c1fbc" [[package]] name = "unic-common" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "80d7ff825a6a654ee85a63e80f92f054f904f21e7d12da4e22f9834a4aaa35bc" [[package]] name = "unic-segment" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e4ed5d26be57f84f176157270c112ef57b86debac9cd21daaabbe56db0f88f23" dependencies = [ "unic-ucd-segment", ] [[package]] name = "unic-ucd-segment" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2079c122a62205b421f499da10f3ee0f7697f012f55b675e002483c73ea34700" dependencies = [ "unic-char-property", "unic-char-range", "unic-ucd-version", ] [[package]] name = "unic-ucd-version" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "96bd2f2237fe450fcd0a1d2f5f4e91711124f7857ba2e964247776ebeeb7b0c4" dependencies = [ "unic-common", ] [[package]] name = "unicode-bidi" version = "0.3.15" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "08f95100a766bf4f8f28f90d77e0a5461bbdb219042e7679bebe79004fed8d75" [[package]] name = "unicode-ident" version = "1.0.12" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3354b9ac3fae1ff6755cb6db53683adb661634f67557942dea4facebec0fee4b" [[package]] name = "unicode-normalization" version = "0.1.23" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a56d1686db2308d901306f92a263857ef59ea39678a5458e7cb17f01415101f5" dependencies = [ "tinyvec", ] [[package]] name = "unsafe-libyaml" version = "0.2.11" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "673aac59facbab8a9007c7f6108d11f63b603f7cabff99fabf650fea5c32b861" [[package]] name = "url" version = "2.5.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "22784dbdf76fdde8af1aeda5622b546b422b6fc585325248a2bf9f5e41e94d6c" dependencies = [ "form_urlencoded", "idna", "percent-encoding", ] [[package]] name = "utf8parse" version = "0.2.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "06abde3611657adf66d383f00b093d7faecc7fa57071cce2578660c9f1010821" [[package]] name = "vcpkg" version = "0.2.15" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "accd4ea62f7bb7a82fe23066fb0957d48ef677f6eeb8215f372f52e48bb32426" [[package]] name = "version_check" version = "0.9.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0b928f33d975fc6ad9f86c8f283853ad26bdd5b10b7f1542aa2fa15e2289105a" [[package]] name = "wait-timeout" version = "0.2.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9f200f5b12eb75f8c1ed65abd4b2db8a6e1b138a20de009dacee265a2498f3f6" dependencies = [ "libc", ] [[package]] name = "walkdir" version = "2.5.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "29790946404f91d9c5d06f9874efddea1dc06c5efe94541a7d6863108e3a5e4b" dependencies = [ "same-file", "winapi-util", ] [[package]] name = "wasi" version = "0.11.0+wasi-snapshot-preview1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9c8d87e72b64a3b4db28d11ce29237c246188f4f51057d65a7eab63b7987e423" [[package]] name = "wasm-bindgen" version = "0.2.93" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a82edfc16a6c469f5f44dc7b571814045d60404b55a0ee849f9bcfa2e63dd9b5" dependencies = [ "cfg-if", "once_cell", "wasm-bindgen-macro", ] [[package]] name = "wasm-bindgen-backend" version = "0.2.93" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9de396da306523044d3302746f1208fa71d7532227f15e347e2d93e4145dd77b" dependencies = [ "bumpalo", "log", "once_cell", "proc-macro2", "quote", "syn", "wasm-bindgen-shared", ] [[package]] name = "wasm-bindgen-macro" version = "0.2.93" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "585c4c91a46b072c92e908d99cb1dcdf95c5218eeb6f3bf1efa991ee7a68cccf" dependencies = [ "quote", "wasm-bindgen-macro-support", ] [[package]] name = "wasm-bindgen-macro-support" version = "0.2.93" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "afc340c74d9005395cf9dd098506f7f44e38f2b4a21c6aaacf9a105ea5e1e836" dependencies = [ "proc-macro2", "quote", "syn", "wasm-bindgen-backend", "wasm-bindgen-shared", ] [[package]] name = "wasm-bindgen-shared" version = "0.2.93" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c62a0a307cb4a311d3a07867860911ca130c3494e8c2719593806c08bc5d0484" [[package]] name = "winapi" version = "0.3.9" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "5c839a674fcd7a98952e593242ea400abe93992746761e38641405d28b00f419" dependencies = [ "winapi-i686-pc-windows-gnu", "winapi-x86_64-pc-windows-gnu", ] [[package]] name = "winapi-i686-pc-windows-gnu" version = "0.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ac3b87c63620426dd9b991e5ce0329eff545bccbbb34f3be09ff6fb6ab51b7b6" [[package]] name = "winapi-util" version = "0.1.9" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cf221c93e13a30d793f7645a0e7762c55d169dbb0a49671918a2319d289b10bb" dependencies = [ "windows-sys 0.59.0", ] [[package]] name = "winapi-x86_64-pc-windows-gnu" version = "0.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f" [[package]] name = "windows-core" version = "0.52.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "33ab640c8d7e35bf8ba19b884ba838ceb4fba93a4e8c65a9059d08afcfc683d9" dependencies = [ "windows-targets 0.52.6", ] [[package]] name = "windows-sys" version = "0.48.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "677d2418bec65e3338edb076e806bc1ec15693c5d0104683f2efe857f61056a9" dependencies = [ "windows-targets 0.48.5", ] [[package]] name = "windows-sys" version = "0.52.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "282be5f36a8ce781fad8c8ae18fa3f9beff57ec1b52cb3de0789201425d9a33d" dependencies = [ "windows-targets 0.52.6", ] [[package]] name = "windows-sys" version = "0.59.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1e38bc4d79ed67fd075bcc251a1c39b32a1776bbe92e5bef1f0bf1f8c531853b" dependencies = [ "windows-targets 0.52.6", ] [[package]] name = "windows-targets" version = "0.48.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9a2fa6e2155d7247be68c096456083145c183cbbbc2764150dda45a87197940c" dependencies = [ "windows_aarch64_gnullvm 0.48.5", "windows_aarch64_msvc 0.48.5", "windows_i686_gnu 0.48.5", "windows_i686_msvc 0.48.5", "windows_x86_64_gnu 0.48.5", "windows_x86_64_gnullvm 0.48.5", "windows_x86_64_msvc 0.48.5", ] [[package]] name = "windows-targets" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9b724f72796e036ab90c1021d4780d4d3d648aca59e491e6b98e725b84e99973" dependencies = [ "windows_aarch64_gnullvm 0.52.6", "windows_aarch64_msvc 0.52.6", "windows_i686_gnu 0.52.6", "windows_i686_gnullvm", "windows_i686_msvc 0.52.6", "windows_x86_64_gnu 0.52.6", "windows_x86_64_gnullvm 0.52.6", "windows_x86_64_msvc 0.52.6", ] [[package]] name = "windows_aarch64_gnullvm" version = "0.48.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2b38e32f0abccf9987a4e3079dfb67dcd799fb61361e53e2882c3cbaf0d905d8" [[package]] name = "windows_aarch64_gnullvm" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "32a4622180e7a0ec044bb555404c800bc9fd9ec262ec147edd5989ccd0c02cd3" [[package]] name = "windows_aarch64_msvc" version = "0.48.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "dc35310971f3b2dbbf3f0690a219f40e2d9afcf64f9ab7cc1be722937c26b4bc" [[package]] name = "windows_aarch64_msvc" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "09ec2a7bb152e2252b53fa7803150007879548bc709c039df7627cabbd05d469" [[package]] name = "windows_i686_gnu" version = "0.48.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a75915e7def60c94dcef72200b9a8e58e5091744960da64ec734a6c6e9b3743e" [[package]] name = "windows_i686_gnu" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "8e9b5ad5ab802e97eb8e295ac6720e509ee4c243f69d781394014ebfe8bbfa0b" [[package]] name = "windows_i686_gnullvm" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0eee52d38c090b3caa76c563b86c3a4bd71ef1a819287c19d586d7334ae8ed66" [[package]] name = "windows_i686_msvc" version = "0.48.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "8f55c233f70c4b27f66c523580f78f1004e8b5a8b659e05a4eb49d4166cca406" [[package]] name = "windows_i686_msvc" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "240948bc05c5e7c6dabba28bf89d89ffce3e303022809e73deaefe4f6ec56c66" [[package]] name = "windows_x86_64_gnu" version = "0.48.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "53d40abd2583d23e4718fddf1ebec84dbff8381c07cae67ff7768bbf19c6718e" [[package]] name = "windows_x86_64_gnu" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "147a5c80aabfbf0c7d901cb5895d1de30ef2907eb21fbbab29ca94c5b08b1a78" [[package]] name = "windows_x86_64_gnullvm" version = "0.48.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0b7b52767868a23d5bab768e390dc5f5c55825b6d30b86c844ff2dc7414044cc" [[package]] name = "windows_x86_64_gnullvm" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "24d5b23dc417412679681396f2b49f3de8c1473deb516bd34410872eff51ed0d" [[package]] name = "windows_x86_64_msvc" version = "0.48.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ed94fce61571a4006852b7389a063ab983c02eb1bb37b47f8272ce92d06d9538" [[package]] name = "windows_x86_64_msvc" version = "0.52.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "589f6da84c646204747d1270a2a5661ea66ed1cced2631d546fdfb155959f9ec" [[package]] name = "winnow" version = "0.6.18" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "68a9bda4691f099d435ad181000724da8e5899daa10713c2d432552b9ccd3a6f" dependencies = [ "memchr", ] [[package]] name = "zerocopy" version = "0.7.35" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1b9b4fd18abc82b8136838da5d50bae7bdea537c574d8dc1a34ed098d6c166f0" dependencies = [ "byteorder", "zerocopy-derive", ] [[package]] name = "zerocopy-derive" version = "0.7.35" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "fa4f8080344d4671fb4e831a13ad1e68092748387dfc4f55e356242fae12ce3e" dependencies = [ "proc-macro2", "quote", "syn", ] 07070100000010000081A400000000000000000000000166C8A4FD00000736000000000000000000000000000000000000002500000000tokei-13.0.0.alpha.5+git0/Cargo.toml[package] authors = ["Erin Power <xampprocky@gmail.com>"] build = "build.rs" categories = ["command-line-utilities", "development-tools", "visualization"] description = "Count your code, quickly." edition = "2018" homepage = "https://tokei.rs" include = [ "Cargo.lock", "Cargo.toml", "LICENCE-APACHE", "LICENCE-MIT", "build.rs", "languages.json", "src/**/*", ] keywords = ["utility", "cli", "cloc", "lines", "statistics"] license = "MIT/Apache-2.0" name = "tokei" readme = "README.md" repository = "https://github.com/XAMPPRocky/tokei.git" version = "13.0.0-alpha.5" [features] all = ["cbor", "yaml"] cbor = ["hex", "serde_cbor"] default = [] yaml = ["serde_yaml"] [profile.release] lto = "thin" panic = "abort" [build-dependencies] tera = "1.20.0" ignore = "0.4.22" serde_json = "1.0.125" json5 = "0.4.1" [dependencies] aho-corasick = "1.1.3" arbitrary = { version = "1.3.2", features = ["derive"] } clap = { version = "4", features = ["cargo", "string", "wrap_help"] } colored = "2.1.0" crossbeam-channel = "0.5.13" encoding_rs_io = "0.1.7" grep-searcher = "0.1.13" ignore = "0.4.22" log = "0.4.22" rayon = "1.10.0" serde = { version = "1.0.208", features = ["derive", "rc"] } term_size = "0.3.2" toml = "0.8.19" parking_lot = "0.12.3" dashmap = { version = "6.0.1", features = ["serde"] } num-format = "0.4.4" once_cell = "1.19.0" regex = "1.10.6" serde_json = "1.0.125" etcetera = "0.8.0" table_formatter = "0.6.1" [dependencies.env_logger] features = [] version = "0.11.5" [dependencies.hex] optional = true version = "0.4.3" [dependencies.serde_cbor] optional = true version = "0.11.2" [dependencies.serde_yaml] optional = true version = "0.9.34" [dev-dependencies] proptest = "1.5.0" strum = "0.26.3" strum_macros = "0.26.4" tempfile = "3.12.0" git2 = { version = "0.19.0", default-features = false, features = [] } 07070100000011000081A400000000000000000000000166C8A4FD000001F0000000000000000000000000000000000000002400000000tokei-13.0.0.alpha.5+git0/EarthfileVERSION 0.6 FROM alpine:3.19 WORKDIR /src build: FROM rust:alpine3.19 RUN apk update \ && apk add \ git \ gcc \ g++ \ pkgconfig COPY . /src WORKDIR /src RUN cargo build --release SAVE ARTIFACT /src/target/release/tokei AS LOCAL ./tokei docker: COPY +build/tokei /usr/local/bin/ WORKDIR /src ENTRYPOINT [ "tokei" ] CMD [ "--help" ] ARG image_name=tokei:latest SAVE IMAGE --push $image_name 07070100000012000081A400000000000000000000000166C8A4FD00000227000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/LICENCE-APACHECopyright 2016 Erin Power Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. 07070100000013000081A400000000000000000000000166C8A4FD00000431000000000000000000000000000000000000002600000000tokei-13.0.0.alpha.5+git0/LICENCE-MITMIT License (MIT) Copyright (c) 2016 Erin Power Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. 07070100000014000081A400000000000000000000000166C8A4FD00003F67000000000000000000000000000000000000002400000000tokei-13.0.0.alpha.5+git0/README.md# Tokei ([時計](https://en.wiktionary.org/wiki/%E6%99%82%E8%A8%88)) [](https://github.com/XAMPPRocky/tokei/actions?query=workflow%3A%22Mean+Bean+CI%22) [](https://github.com/XAMPPRocky/tokei/issues?q=is%3Aissue+is%3Aopen+label%3A%22help+wanted%22) [](https://github.com/XAMPPRocky/tokei) [](https://docs.rs/tokei/)    ) [](https://deps.rs/repo/github/XAMPPRocky/tokei) [](https://repology.org/project/tokei/versions) Tokei is a program that displays statistics about your code. Tokei will show the number of files, total lines within those files and code, comments, and blanks grouped by language. ### Translations - [中文](https://github.com/chinanf-boy/tokei-zh#支持的语言) ## Example ```console ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ Language Files Lines Code Comments Blanks ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ BASH 4 49 30 10 9 JSON 1 1332 1332 0 0 Shell 1 49 38 1 10 TOML 2 77 64 4 9 ─────────────────────────────────────────────────────────────────────────────── Markdown 5 1355 0 1074 281 |- JSON 1 41 41 0 0 |- Rust 2 53 42 6 5 |- Shell 1 22 18 0 4 (Total) 1471 101 1080 290 ─────────────────────────────────────────────────────────────────────────────── Rust 19 3416 2840 116 460 |- Markdown 12 351 5 295 51 (Total) 3767 2845 411 511 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ Total 32 6745 4410 1506 829 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ``` ## [API Documentation](https://docs.rs/tokei) ## Table of Contents - [Features](#features) - [Installation](#installation) - [Package Managers](#package-managers) - [Manual](#manual) - [Configuration](#configuration) - [How to use Tokei](#how-to-use-tokei) - [Options](#options) - [Badges](#badges) - [Supported Languages](#supported-languages) - [Changelog](CHANGELOG.md) - [Common Issues](#common-issues) - [Canonical Source](#canonical-source) - [Copyright and License](#copyright-and-license) ## Features - Tokei is **very fast**, and is able to count millions of lines of code in seconds. Check out the [11.0.0 release](https://github.com/XAMPPRocky/tokei/releases/v11.0.0) to see how Tokei's speed compares to others. - Tokei is **accurate**, Tokei correctly handles multi line comments, nested comments, and not counting comments that are in strings. Providing an accurate code statistics. - Tokei has huge range of languages, supporting over **150** languages, and their various extensions. - Tokei can output in multiple formats(**CBOR**, **JSON**, **YAML**) allowing Tokei's output to be easily stored, and reused. These can also be reused in tokei combining a previous run's statistics with another set. - Tokei is available on **Mac**, **Linux**, and **Windows**. See [installation instructions](#installation) for how to get Tokei on your platform. - Tokei is also a **library** allowing you to easily integrate it with other projects. - Tokei comes with and without color. Set the env variable NO_COLOR to 1, and it'll be black and white. ## Installation ### Package Managers #### Unix ```console # Alpine Linux (since 3.13) apk add tokei # Arch Linux pacman -S tokei # Cargo cargo install tokei # Conda conda install -c conda-forge tokei # Fedora sudo dnf install tokei # FreeBSD pkg install tokei # NetBSD pkgin install tokei # Nix/NixOS nix-env -i tokei # OpenSUSE sudo zypper install tokei # Void Linux sudo xbps-install tokei ``` #### macOS ```console # Homebrew brew install tokei # MacPorts sudo port selfupdate sudo port install tokei ``` #### Windows ```console # Winget winget install XAMPPRocky.tokei # Scoop scoop install tokei ``` ### Manual #### Downloading You can download prebuilt binaries in the [releases section](https://github.com/XAMPPRocky/tokei/releases). #### Building You can also build and install from source (requires the latest stable [Rust] compiler.) ```console cargo install --git https://github.com/XAMPPRocky/tokei.git tokei ``` [rust]: https://www.rust-lang.org ## Configuration Tokei has a [configuration] file that allows you to change default behaviour. The file can be named `tokei.toml` or `.tokeirc`. Currently tokei looks for this file in three different places. The current directory, your home directory, and your configuration directory. ## How to use Tokei #### Basic usage This is the basic way to use tokei. Which will report on the code in `./foo` and all subfolders. ```shell $ tokei ./foo ``` [configuration]: ./tokei.example.toml #### Multiple folders To have tokei report on multiple folders in the same call simply add a comma, or a space followed by another path. ```shell $ tokei ./foo ./bar ./baz ``` ```shell $ tokei ./foo, ./bar, ./baz ``` #### Excluding folders Tokei will respect all `.gitignore` and `.ignore` files, and you can use the `--exclude` option to exclude any additional files. The `--exclude` flag has the same semantics as `.gitignore`. ```shell $ tokei ./foo --exclude *.rs ``` Paths to exclude can also be listed in a `.tokeignore` file, using the same [syntax](https://git-scm.com/docs/gitignore) as .gitignore files. #### Sorting output By default tokei sorts alphabetically by language name, however using `--sort` tokei can also sort by any of the columns. `blanks, code, comments, lines` ```shell $ tokei ./foo --sort code ``` #### Outputting file statistics By default tokei only outputs the total of the languages, and using `--files` flag tokei can also output individual file statistics. ```shell $ tokei ./foo --files ``` #### Outputting into different formats Tokei normally outputs into a nice human readable format designed for terminals. There is also using the `--output` option various other formats that are more useful for bringing the data into another program. **Note:** This version of tokei was compiled without any serialization formats, to enable serialization, reinstall tokei with the features flag. ```shell ALL: cargo install tokei --features all CBOR: cargo install tokei --features cbor YAML: cargo install tokei --features yaml ``` **Currently supported formats** - JSON `--output json` - YAML `--output yaml` - CBOR `--output cbor` ```shell $ tokei ./foo --output json ``` #### Reading in stored formats Tokei can also take in the outputted formats added in the previous results to its current run. Tokei can take either a path to a file, the format passed in as a value to the option, or from stdin. ```shell $ tokei ./foo --input ./stats.json ``` ## Options ``` USAGE: tokei [FLAGS] [OPTIONS] [--] [input]... FLAGS: -f, --files Will print out statistics on individual files. -h, --help Prints help information --hidden Count hidden files. -l, --languages Prints out supported languages and their extensions. --no-ignore Don't respect ignore files (.gitignore, .ignore, etc.). This implies --no-ignore-parent, --no-ignore-dot, and --no-ignore-vcs. --no-ignore-dot Don't respect .ignore and .tokeignore files, including those in parent directories. --no-ignore-parent Don't respect ignore files (.gitignore, .ignore, etc.) in parent directories. --no-ignore-vcs Don't respect VCS ignore files (.gitignore, .hgignore, etc.), including those in parent directories. -V, --version Prints version information -v, --verbose Set log output level: 1: to show unknown file extensions, 2: reserved for future debugging, 3: enable file level trace. Not recommended on multiple files OPTIONS: -c, --columns <columns> Sets a strict column width of the output, only available for terminal output. -e, --exclude <exclude>... Ignore all files & directories matching the pattern. -i, --input <file_input> Gives statistics from a previous tokei run. Can be given a file path, or "stdin" to read from stdin. -o, --output <output> Outputs Tokei in a specific format. Compile with additional features for more format support. [possible values: cbor, json, yaml] -s, --sort <sort> Sort languages based on column [possible values: files, lines, blanks, code, comments] -t, --type <types> Filters output by language type, separated by a comma. i.e. -t=Rust,Markdown ARGS: <input>... The path(s) to the file or directory to be counted. ``` ## Badges Tokei has support for badges. For example [](https://github.com/XAMPPRocky/tokei). ``` [](https://github.com/XAMPPRocky/tokei). ``` Tokei's URL scheme is as follows. ``` https://tokei.rs/b1/{host: values: github|gitlab}/{Repo Owner eg: XAMPPRocky}/{Repo name eg: tokei} ``` By default the badge will show the repo's LoC(_Lines of Code_), you can also specify for it to show a different category, by using the `?category=` query string. It can be either `code`, `blanks`, `files`, `lines`, `comments`, Example show total lines: ``` [](https://github.com/XAMPPRocky/tokei). ``` The server code hosted on tokei.rs is in [XAMPPRocky/tokei_rs](https://github.com/XAMPPRocky/tokei_rs) ## Dockerized version Tokei is available in a small `alpine`-based docker image, buildable through [earthly](https://github.com/earthly/earthly): ```bash earthly +docker ``` Once built, one can run the image with: ```bash docker run --rm -v /path/to/analyze:/src tokei . ``` Or, to simply analyze the current folder (linux): ```bash docker run --rm -v $(pwd):/src tokei . ``` ## Supported Languages If there is a language that you would to add to tokei feel free to make a pull request. Languages are defined in [`languages.json`](./languages.json), and you can read how to add and test your language in our [CONTRIBUTING.md](./CONTRIBUTING.md). ``` Abap ActionScript Ada Agda Alex Alloy Asn1 Asp AspNet Assembly AssemblyGAS ATS Autoconf AutoHotKey Automake AWK Bash Batch Bazel Bean Bicep Bitbake BrightScript C Cabal Cassius Ceylon CHeader Cil Clojure ClojureC ClojureScript CMake Cobol CoffeeScript Cogent ColdFusion ColdFusionScript Coq Cpp CppHeader Crystal CSharp CShell Css Cuda CUE Cython D D2 DAML Dart DeviceTree Dhall Dockerfile DotNetResource DreamMaker Dust Ebuild EdgeDB Edn Elisp Elixir Elm Elvish EmacsDevEnv Emojicode Erlang Factor FEN Fish FlatBuffers ForgeConfig Forth FortranLegacy FortranModern FreeMarker FSharp Fstar GDB GdScript GdShader Gherkin Gleam Glsl Go Graphql Groovy Gwion Hamlet Handlebars Happy Hare Haskell Haxe Hcl Hex hledger Hlsl HolyC Html Hy Idris Ini IntelHex Isabelle Jai Janet Java JavaScript Jq Json Jsx Julia Julius KakouneScript Kotlin Lean Less Lingua Franca LinkerScript Liquid Lisp LLVM Logtalk Lua Lucius Madlang Max Makefile Markdown Mdx Meson Mint Mlatu ModuleDef MonkeyC MoonScript MsBuild Mustache Nim Nix NotQuitePerl NuGetConfig Nushell ObjectiveC ObjectiveCpp OCaml Odin OpenSCAD OpenQASM Org Oz Pascal Perl Perl6 Pest Php Po Poke Polly Pony PostCss PowerShell Processing Prolog Protobuf PRQL PSL PureScript Python Qcl Qml R Racket Rakefile Razor Renpy ReStructuredText RON RPMSpecfile Ruby RubyHtml Rust Sass Scala Scheme Scons Sh ShaderLab Slang Sml Solidity SpecmanE Spice Sql SRecode Stata Stratego Svelte Svg Swift Swig SystemVerilog Tact Tcl Tex Text Thrift Toml Tsx Twig TypeScript UMPL UnrealDeveloperMarkdown UnrealPlugin UnrealProject UnrealScript UnrealShader UnrealShaderHeader UrWeb UrWebProject Vala VB6 VBScript Velocity Verilog VerilogArgsFile Vhdl VimScript VisualBasic VisualStudioProject VisualStudioSolution Vue WebAssembly Wolfram Xaml XcodeConfig Xml XSL Xtend Yaml ZenCode Zig ZoKrates Zsh ``` ## Common issues ### Tokei says I have a lot of D code, but I know there is no D code! This is likely due to `gcc` generating `.d` files. Until the D people decide on a different file extension, you can always exclude `.d` files using the `-e --exclude` flag like so ``` $ tokei . -e *.d ``` ## Canonical Source The canonical source of this repo is hosted on [GitHub](https://github.com/XAMPPRocky/tokei). If you have a GitHub account, please make your issues, and pull requests there. ## Related Tools - [tokei-pie](https://github.com/laixintao/tokei-pie): Render tokei's output to interactive sunburst chart. ## Copyright and License (C) Copyright 2015 by XAMPPRocky and contributors See [the graph](https://github.com/XAMPPRocky/tokei/graphs/contributors) for a full list of contributors. Tokei is distributed under the terms of both the MIT license and the Apache License (Version 2.0). See [LICENCE-APACHE](./LICENCE-APACHE), [LICENCE-MIT](./LICENCE-MIT) for more information. 07070100000015000081ED00000000000000000000000166C8A4FD000003E5000000000000000000000000000000000000002700000000tokei-13.0.0.alpha.5+git0/benchmark.sh#!/usr/bin/env bash set -e if [ "$1" = "--full" ]; then FILE=$2 FULL=true else FILE=$1 FULL=false fi echo 'Tokei Benchmarking Tool' if [ $FULL = true ]; then REQUIRED='cloc, tokei, loc, hyperfine, and scc' else REQUIRED='tokei, and hyperfine' fi echo "The use of this tool requires $REQUIRED to be installed and available in your PATH variable." echo 'Please enter the path you would like to benchmark:' if [ -z ${FILE+x} ]; then read -r input else input=$FILE fi hyperfine --version echo "old tokei: $(tokei --version)" if [ $FULL = true ]; then scc --version loc --version echo "cloc: $(cloc --version)" fi cargo build --release if [ $FULL = true ]; then hyperfine -w 10 --export-csv './results.csv' "target/release/tokei $input" \ "tokei $input" \ "scc $input" \ "loc $input" # \ "cloc $input" else hyperfine -w 5 "target/release/tokei $input" \ "tokei $input" fi 07070100000016000081A400000000000000000000000166C8A4FD000013AA000000000000000000000000000000000000002300000000tokei-13.0.0.alpha.5+git0/build.rsextern crate ignore; extern crate json5; extern crate serde_json; use std::ffi::OsStr; use std::fs; use std::path::Path; use std::{cmp, env, error}; use ignore::Walk; use serde_json::Value; fn main() -> Result<(), Box<dyn error::Error>> { let out_dir = env::var_os("OUT_DIR").expect("No OUT_DIR variable."); generate_languages(&out_dir)?; generate_tests(&out_dir)?; Ok(()) } fn generate_languages(out_dir: &OsStr) -> Result<(), Box<dyn error::Error>> { let mut tera = tera::Tera::default(); let json_string: String = fs::read_to_string("languages.json")?.parse()?; let mut json: Value = json5::from_str(&json_string)?; for (_key, ref mut item) in json .get_mut("languages") .unwrap() .as_object_mut() .unwrap() .iter_mut() { macro_rules! sort_prop { ($prop:expr) => {{ if let Some(ref mut prop) = item.get_mut($prop) { prop.as_array_mut() .unwrap() .sort_unstable_by(compare_json_str_len) } }}; } sort_prop!("quotes"); sort_prop!("verbatim_quotes"); sort_prop!("multi_line"); } let output_path = Path::new(&out_dir).join("language_type.rs"); let rust_code = tera.render_str( &std::fs::read_to_string("src/language/language_type.tera.rs")?, &tera::Context::from_value(json)?, )?; std::fs::write(output_path, rust_code)?; Ok(()) } fn compare_json_str_len(a: &Value, b: &Value) -> cmp::Ordering { let a = a.as_array().expect("a as array"); let b = b.as_array().expect("b as array"); let max_a_size = a.iter().map(|e| e.as_str().unwrap().len()).max().unwrap(); let max_b_size = b.iter().map(|e| e.as_str().unwrap().len()).max().unwrap(); max_b_size.cmp(&max_a_size) } fn generate_tests(out_dir: &OsStr) -> Result<(), Box<dyn error::Error>> { // Length of string literal below by number of languages const INITIAL_BUFFER_SIZE: usize = 989 * 130; let mut string = String::with_capacity(INITIAL_BUFFER_SIZE); generate_tests_batch("./tests/data", None, &mut string)?; generate_tests_batch("./tests/embedding", Some("embedding"), &mut string)?; Ok(fs::write(Path::new(&out_dir).join("tests.rs"), string)?) } fn generate_tests_batch( src_dir: &str, test_module: Option<&str>, string: &mut String, ) -> Result<(), Box<dyn error::Error>> { let walker = Walk::new(src_dir).filter(|p| match p { Ok(ref p) => { if let Ok(ref p) = p.metadata() { p.is_file() } else { false } } _ => false, }); if let Some(test_module) = test_module { string.push_str(&format!( r####" #[cfg(test)] mod {0} {{ use super::*; "####, test_module )); } for path in walker { let path = path?; let path = path.path(); let root = std::path::PathBuf::from(std::env::var("CARGO_MANIFEST_DIR").unwrap()); let name = path.file_stem().unwrap().to_str().unwrap().to_lowercase(); if name == "jupyter" { continue; } string.push_str(&format!( r####" #[test] fn {0}() {{ const _: &str = include_str!(r###"{2}"###); let mut languages = Languages::new(); languages.get_statistics(&["{1}"], &[], &Config::default()); if languages.len() != 1 {{ panic!("wrong languages detected: expected just {0}, found {{:?}}", languages.into_iter().collect::<Vec<_>>()); }} let (name, language) = languages.into_iter().next().unwrap(); let mut language = language.summarise(); let contents = fs::read_to_string("{1}").unwrap(); println!("{{}} {1}", name); assert_eq!(get_digit!(LINES, contents), language.lines()); println!("{{}} LINES MATCH", name); assert_eq!(get_digit!(CODE, contents), language.code); println!("{{}} CODE MATCH", name); assert_eq!(get_digit!(COMMENTS, contents), language.comments); println!("{{}} COMMENTS MATCH", name); assert_eq!(get_digit!(BLANKS, contents), language.blanks); println!("{{}} BLANKS MATCH", name); let report = language.reports.pop().unwrap(); let stats = report.stats.summarise(); assert_eq!(language.lines(), stats.lines()); assert_eq!(language.code, stats.code); assert_eq!(language.comments, stats.comments); assert_eq!(language.blanks, stats.blanks); }} "####, name, path.to_string_lossy().replace('\\', "/"), std::fs::canonicalize(root.join(path)).unwrap().display(), )); } if test_module.is_some() { string.push_str("\n}"); } Ok(()) } 07070100000017000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000001D00000000tokei-13.0.0.alpha.5+git0/ci07070100000018000081ED00000000000000000000000166C8A4FD00000234000000000000000000000000000000000000002800000000tokei-13.0.0.alpha.5+git0/ci/build.bash#!/usr/bin/env bash # Script for building your rust projects. set -e source ci/common.bash # $1 {path} = Path to cross/cargo executable CROSS=$1 # $1 {string} = <Target Triple> TARGET_TRIPLE=$2 # $3 {boolean} = Whether or not building for release or not. RELEASE_BUILD=$3 required_arg "$CROSS" 'CROSS' required_arg "$TARGET_TRIPLE" '<Target Triple>' if [ -z "$RELEASE_BUILD" ]; then $CROSS build --target "$TARGET_TRIPLE" $CROSS build --target "$TARGET_TRIPLE" --all-features else $CROSS build --target "$TARGET_TRIPLE" --all-features --release fi 07070100000019000081A400000000000000000000000166C8A4FD0000006E000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/ci/common.bashrequired_arg() { if [ -z "$1" ]; then echo "Required argument $2 missing" exit 1 fi } 0707010000001A000081ED00000000000000000000000166C8A4FD00000046000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/ci/set_rust_version.bash#!/usr/bin/env bash set -e rustup default "$1" rustup target add "$2" 0707010000001B000081ED00000000000000000000000166C8A4FD00000170000000000000000000000000000000000000002700000000tokei-13.0.0.alpha.5+git0/ci/test.bash#!/usr/bin/env bash # Script for building your rust projects. set -e source ci/common.bash # $1 {path} = Path to cross/cargo executable CROSS=$1 # $1 {string} = <Target Triple> TARGET_TRIPLE=$2 required_arg "$CROSS" 'CROSS' required_arg "$TARGET_TRIPLE" '<Target Triple>' $CROSS test --target "$TARGET_TRIPLE" $CROSS build --target "$TARGET_TRIPLE" --all-features 0707010000001C000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000001F00000000tokei-13.0.0.alpha.5+git0/fuzz0707010000001D000081A400000000000000000000000166C8A4FD00000019000000000000000000000000000000000000002A00000000tokei-13.0.0.alpha.5+git0/fuzz/.gitignore target corpus artifacts 0707010000001E000081A400000000000000000000000166C8A4FD00007181000000000000000000000000000000000000002A00000000tokei-13.0.0.alpha.5+git0/fuzz/Cargo.lock# This file is automatically @generated by Cargo. # It is not intended for manual editing. version = 3 [[package]] name = "aho-corasick" version = "0.7.15" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "7404febffaa47dac81aa44dba71523c9d069b1bdc50a77db41195149e17f68e5" dependencies = [ "memchr", ] [[package]] name = "ansi_term" version = "0.11.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ee49baf6cb617b853aa8d93bf420db2383fab46d314482ca2803b40d5fde979b" dependencies = [ "winapi", ] [[package]] name = "arbitrary" version = "1.0.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "510c76ecefdceada737ea728f4f9a84bd2e1ef29f1ba555e560940fe279954de" dependencies = [ "derive_arbitrary", ] [[package]] name = "arrayvec" version = "0.4.12" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cd9fd44efafa8690358b7408d253adf110036b88f55672a933f01d616ad9b1b9" dependencies = [ "nodrop", ] [[package]] name = "atty" version = "0.2.14" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d9b39be18770d11421cdb1b9947a45dd3f37e93092cbf377614828a319d5fee8" dependencies = [ "hermit-abi", "libc", "winapi", ] [[package]] name = "autocfg" version = "1.0.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cdb031dd78e28731d87d56cc8ffef4a8f36ca26c38fe2de700543e627f8a464a" [[package]] name = "bitflags" version = "1.2.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cf1de2fe8c75bc145a2f577add951f8134889b4795d47466a54a5c846d691693" [[package]] name = "block-buffer" version = "0.7.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c0940dc441f31689269e10ac70eb1002a3a1d3ad1390e030043662eb7fe4688b" dependencies = [ "block-padding", "byte-tools", "byteorder", "generic-array", ] [[package]] name = "block-padding" version = "0.1.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "fa79dedbb091f449f1f39e53edf88d5dbe95f895dae6135a8d7b881fb5af73f5" dependencies = [ "byte-tools", ] [[package]] name = "bstr" version = "0.2.15" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a40b47ad93e1a5404e6c18dec46b628214fee441c70f4ab5d6942142cc268a3d" dependencies = [ "memchr", ] [[package]] name = "byte-tools" version = "0.3.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e3b5ca7a04898ad4bcd41c90c5285445ff5b791899bb1b0abdd2a2aa791211d7" [[package]] name = "bytecount" version = "0.6.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "72feb31ffc86498dacdbd0fcebb56138e7177a8cc5cea4516031d15ae85a742e" [[package]] name = "byteorder" version = "1.4.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ae44d1a3d5a19df61dd0c8beb138458ac2a53a7ac09eba97d55592540004306b" [[package]] name = "cc" version = "1.0.67" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e3c69b077ad434294d3ce9f1f6143a2a4b89a8a2d54ef813d85003a4fd1137fd" [[package]] name = "cfg-if" version = "1.0.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "baf1de4339761588bc0619e3cbc0120ee582ebb74b53b4efbf79117bd2da40fd" [[package]] name = "chrono" version = "0.4.19" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "670ad68c9088c2a963aaa298cb369688cf3f9465ce5e2d4ca10e6e0098a1ce73" dependencies = [ "libc", "num-integer", "num-traits", "time", "winapi", ] [[package]] name = "chrono-tz" version = "0.5.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2554a3155fec064362507487171dcc4edc3df60cb10f3a1fb10ed8094822b120" dependencies = [ "chrono", "parse-zoneinfo", ] [[package]] name = "clap" version = "2.33.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "37e58ac78573c40708d45522f0d80fa2f01cc4f9b4e2bf749807255454312002" dependencies = [ "ansi_term", "atty", "bitflags", "strsim", "term_size", "textwrap", "unicode-width", "vec_map", ] [[package]] name = "colored" version = "2.0.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b3616f750b84d8f0de8a58bda93e08e2a81ad3f523089b05f1dffecab48c6cbd" dependencies = [ "atty", "lazy_static", "winapi", ] [[package]] name = "crossbeam-channel" version = "0.5.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "dca26ee1f8d361640700bde38b2c37d8c22b3ce2d360e1fc1c74ea4b0aa7d775" dependencies = [ "cfg-if", "crossbeam-utils", ] [[package]] name = "crossbeam-deque" version = "0.8.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "94af6efb46fef72616855b036a624cf27ba656ffc9be1b9a3c931cfc7749a9a9" dependencies = [ "cfg-if", "crossbeam-epoch", "crossbeam-utils", ] [[package]] name = "crossbeam-epoch" version = "0.9.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d60ab4a8dba064f2fbb5aa270c28da5cf4bbd0e72dae1140a6b0353a779dbe00" dependencies = [ "cfg-if", "crossbeam-utils", "lazy_static", "loom", "memoffset", "scopeguard", ] [[package]] name = "crossbeam-utils" version = "0.8.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "bae8f328835f8f5a6ceb6a7842a7f2d0c03692adb5c889347235d59194731fe3" dependencies = [ "autocfg", "cfg-if", "lazy_static", "loom", ] [[package]] name = "dashmap" version = "4.0.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e77a43b28d0668df09411cb0bc9a8c2adc40f9a048afe863e05fd43251e8e39c" dependencies = [ "cfg-if", "num_cpus", "serde", ] [[package]] name = "derive_arbitrary" version = "1.0.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "df89dd0d075dea5cc5fdd6d5df6b8a61172a710b3efac1d6bdb9dd8b78f82c1a" dependencies = [ "proc-macro2", "quote", "syn", ] [[package]] name = "deunicode" version = "0.4.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "850878694b7933ca4c9569d30a34b55031b9b139ee1fc7b94a527c4ef960d690" [[package]] name = "digest" version = "0.8.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "f3d0c8c8752312f9713efd397ff63acb9f85585afbf179282e720e7704954dd5" dependencies = [ "generic-array", ] [[package]] name = "dirs-next" version = "2.0.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b98cf8ebf19c3d1b223e151f99a4f9f0690dca41414773390fc824184ac833e1" dependencies = [ "cfg-if", "dirs-sys-next", ] [[package]] name = "dirs-sys-next" version = "0.1.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "4ebda144c4fe02d1f7ea1a7d9641b6fc6b580adcfa024ae48797ecdeb6825b4d" dependencies = [ "libc", "redox_users", "winapi", ] [[package]] name = "either" version = "1.6.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e78d4f1cc4ae33bbfc157ed5d5a5ef3bc29227303d595861deb238fcec4e9457" [[package]] name = "encoding_rs" version = "0.8.28" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "80df024fbc5ac80f87dfef0d9f5209a252f2a497f7f42944cff24d8253cac065" dependencies = [ "cfg-if", ] [[package]] name = "encoding_rs_io" version = "0.1.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1cc3c5651fb62ab8aa3103998dade57efdd028544bd300516baa31840c252a83" dependencies = [ "encoding_rs", ] [[package]] name = "env_logger" version = "0.8.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "17392a012ea30ef05a610aa97dfb49496e71c9f676b27879922ea5bdf60d9d3f" dependencies = [ "atty", "humantime", "log", "regex", "termcolor", ] [[package]] name = "fake-simd" version = "0.1.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e88a8acf291dafb59c2d96e8f59828f3838bb1a70398823ade51a84de6a6deed" [[package]] name = "fnv" version = "1.0.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3f9eec918d3f24069decb9af1554cad7c880e2da24a9afd88aca000531ab82c1" [[package]] name = "generator" version = "0.6.24" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a9fed24fd1e18827652b4d55652899a1e9da8e54d91624dc3437a5bc3a9f9a9c" dependencies = [ "cc", "libc", "log", "rustversion", "winapi", ] [[package]] name = "generic-array" version = "0.12.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c68f0274ae0e023facc3c97b2e00f076be70e254bc851d972503b328db79b2ec" dependencies = [ "typenum", ] [[package]] name = "getrandom" version = "0.2.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c9495705279e7140bf035dde1f6e750c162df8b625267cd52cc44e0b156732c8" dependencies = [ "cfg-if", "libc", "wasi", ] [[package]] name = "globset" version = "0.4.8" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "10463d9ff00a2a068db14231982f5132edebad0d7660cd956a1c30292dbcbfbd" dependencies = [ "aho-corasick", "bstr", "fnv", "log", "regex", ] [[package]] name = "globwalk" version = "0.8.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "93e3af942408868f6934a7b85134a3230832b9977cf66125df2f9edcfce4ddcc" dependencies = [ "bitflags", "ignore", "walkdir", ] [[package]] name = "grep-matcher" version = "0.1.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "6d27563c33062cd33003b166ade2bb4fd82db1fd6a86db764dfdad132d46c1cc" dependencies = [ "memchr", ] [[package]] name = "grep-searcher" version = "0.1.8" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "7fbdbde90ba52adc240d2deef7b6ad1f99f53142d074b771fe9b7bede6c4c23d" dependencies = [ "bstr", "bytecount", "encoding_rs", "encoding_rs_io", "grep-matcher", "log", "memmap2", ] [[package]] name = "hermit-abi" version = "0.1.18" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "322f4de77956e22ed0e5032c359a0f1273f1f7f0d79bfa3b8ffbc730d7fbcc5c" dependencies = [ "libc", ] [[package]] name = "humansize" version = "1.1.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b6cab2627acfc432780848602f3f558f7e9dd427352224b0d9324025796d2a5e" [[package]] name = "humantime" version = "2.1.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9a3a5bfb195931eeb336b2a7b4d761daec841b97f947d34394601737a7bba5e4" [[package]] name = "ignore" version = "0.4.18" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "713f1b139373f96a2e0ce3ac931cd01ee973c3c5dd7c40c0c2efe96ad2b6751d" dependencies = [ "crossbeam-utils", "globset", "lazy_static", "log", "memchr", "regex", "same-file", "thread_local", "walkdir", "winapi-util", ] [[package]] name = "instant" version = "0.1.9" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "61124eeebbd69b8190558df225adf7e4caafce0d743919e5d6b19652314ec5ec" dependencies = [ "cfg-if", ] [[package]] name = "itoa" version = "0.4.7" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "dd25036021b0de88a0aff6b850051563c6516d0bf53f8638938edbb9de732736" [[package]] name = "itoa" version = "1.0.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1aab8fc367588b89dcee83ab0fd66b72b50b72fa1904d7095045ace2b0c81c35" [[package]] name = "lazy_static" version = "1.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e2abad23fbc42b3700f2f279844dc832adb2b2eb069b2df918f455c4e18cc646" [[package]] name = "libc" version = "0.2.86" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b7282d924be3275cec7f6756ff4121987bc6481325397dde6ba3e7802b1a8b1c" [[package]] name = "libfuzzer-sys" version = "0.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "86c975d637bc2a2f99440932b731491fc34c7f785d239e38af3addd3c2fd0e46" dependencies = [ "arbitrary", "cc", ] [[package]] name = "lock_api" version = "0.4.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "dd96ffd135b2fd7b973ac026d28085defbe8983df057ced3eb4f2130b0831312" dependencies = [ "scopeguard", ] [[package]] name = "log" version = "0.4.14" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "51b9bbe6c47d51fc3e1a9b945965946b4c44142ab8792c50835a980d362c2710" dependencies = [ "cfg-if", ] [[package]] name = "loom" version = "0.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d44c73b4636e497b4917eb21c33539efa3816741a2d3ff26c6316f1b529481a4" dependencies = [ "cfg-if", "generator", "scoped-tls", ] [[package]] name = "maplit" version = "1.0.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3e2e65a1a2e43cfcb47a895c4c8b10d1f4a61097f9f254f183aee60cad9c651d" [[package]] name = "memchr" version = "2.3.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0ee1c47aaa256ecabcaea351eae4a9b01ef39ed810004e298d2511ed284b1525" [[package]] name = "memmap2" version = "0.3.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "00b6c2ebff6180198788f5db08d7ce3bc1d0b617176678831a7510825973e357" dependencies = [ "libc", ] [[package]] name = "memoffset" version = "0.6.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "157b4208e3059a8f9e78d559edc658e13df41410cb3ae03979c83130067fdd87" dependencies = [ "autocfg", ] [[package]] name = "nodrop" version = "0.1.14" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "72ef4a56884ca558e5ddb05a1d1e7e1bfd9a68d9ed024c21704cc98872dae1bb" [[package]] name = "num-format" version = "0.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "bafe4179722c2894288ee77a9f044f02811c86af699344c498b0840c698a2465" dependencies = [ "arrayvec", "itoa 0.4.7", ] [[package]] name = "num-integer" version = "0.1.44" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d2cc698a63b549a70bc047073d2949cce27cd1c7b0a4a862d08a8031bc2801db" dependencies = [ "autocfg", "num-traits", ] [[package]] name = "num-traits" version = "0.2.14" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9a64b1ec5cda2586e284722486d802acf1f7dbdc623e2bfc57e65ca1cd099290" dependencies = [ "autocfg", ] [[package]] name = "num_cpus" version = "1.13.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "05499f3756671c15885fee9034446956fff3f243d6077b91e5767df161f766b3" dependencies = [ "hermit-abi", "libc", ] [[package]] name = "once_cell" version = "1.7.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "10acf907b94fc1b1a152d08ef97e7759650268cf986bf127f387e602b02c7e5a" [[package]] name = "opaque-debug" version = "0.2.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2839e79665f131bdb5782e51f2c6c9599c133c6098982a54c794358bf432529c" [[package]] name = "parking_lot" version = "0.11.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "6d7744ac029df22dca6284efe4e898991d28e3085c706c972bcd7da4a27a15eb" dependencies = [ "instant", "lock_api", "parking_lot_core", ] [[package]] name = "parking_lot_core" version = "0.8.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "fa7a782938e745763fe6907fc6ba86946d72f49fe7e21de074e08128a99fb018" dependencies = [ "cfg-if", "instant", "libc", "redox_syscall", "smallvec", "winapi", ] [[package]] name = "parse-zoneinfo" version = "0.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c705f256449c60da65e11ff6626e0c16a0a0b96aaa348de61376b249bc340f41" dependencies = [ "regex", ] [[package]] name = "percent-encoding" version = "2.1.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d4fd5641d01c8f18a23da7b6fe29298ff4b55afcccdf78973b24cf3175fee32e" [[package]] name = "pest" version = "2.1.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "10f4872ae94d7b90ae48754df22fd42ad52ce740b8f370b03da4835417403e53" dependencies = [ "ucd-trie", ] [[package]] name = "pest_derive" version = "2.1.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "833d1ae558dc601e9a60366421196a8d94bc0ac980476d0b67e1d0988d72b2d0" dependencies = [ "pest", "pest_generator", ] [[package]] name = "pest_generator" version = "2.1.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "99b8db626e31e5b81787b9783425769681b347011cc59471e33ea46d2ea0cf55" dependencies = [ "pest", "pest_meta", "proc-macro2", "quote", "syn", ] [[package]] name = "pest_meta" version = "2.1.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "54be6e404f5317079812fc8f9f5279de376d8856929e21c184ecf6bbd692a11d" dependencies = [ "maplit", "pest", "sha-1", ] [[package]] name = "ppv-lite86" version = "0.2.10" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ac74c624d6b2d21f425f752262f42188365d7b8ff1aff74c82e45136510a4857" [[package]] name = "proc-macro2" version = "1.0.24" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1e0704ee1a7e00d7bb417d0770ea303c1bccbabf0ef1667dae92b5967f5f8a71" dependencies = [ "unicode-xid", ] [[package]] name = "quote" version = "1.0.9" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c3d0b9745dc2debf507c8422de05d7226cc1f0644216dfdfead988f9b1ab32a7" dependencies = [ "proc-macro2", ] [[package]] name = "rand" version = "0.8.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0ef9e7e66b4468674bfcb0c81af8b7fa0bb154fa9f28eb840da5c447baeb8d7e" dependencies = [ "libc", "rand_chacha", "rand_core", "rand_hc", ] [[package]] name = "rand_chacha" version = "0.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e12735cf05c9e10bf21534da50a147b924d555dc7a547c42e6bb2d5b6017ae0d" dependencies = [ "ppv-lite86", "rand_core", ] [[package]] name = "rand_core" version = "0.6.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "34cf66eb183df1c5876e2dcf6b13d57340741e8dc255b48e40a26de954d06ae7" dependencies = [ "getrandom", ] [[package]] name = "rand_hc" version = "0.3.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "3190ef7066a446f2e7f42e239d161e905420ccab01eb967c9eb27d21b2322a73" dependencies = [ "rand_core", ] [[package]] name = "rayon" version = "1.5.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "8b0d8e0819fadc20c74ea8373106ead0600e3a67ef1fe8da56e39b9ae7275674" dependencies = [ "autocfg", "crossbeam-deque", "either", "rayon-core", ] [[package]] name = "rayon-core" version = "1.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9ab346ac5921dc62ffa9f89b7a773907511cdfa5490c572ae9be1be33e8afa4a" dependencies = [ "crossbeam-channel", "crossbeam-deque", "crossbeam-utils", "lazy_static", "num_cpus", ] [[package]] name = "redox_syscall" version = "0.2.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "94341e4e44e24f6b591b59e47a8a027df12e008d73fd5672dbea9cc22f4507d9" dependencies = [ "bitflags", ] [[package]] name = "redox_users" version = "0.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "528532f3d801c87aec9def2add9ca802fe569e44a544afe633765267840abe64" dependencies = [ "getrandom", "redox_syscall", ] [[package]] name = "regex" version = "1.4.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2a26af418b574bd56588335b3a3659a65725d4e636eb1016c2f9e3b38c7cc759" dependencies = [ "aho-corasick", "memchr", "regex-syntax", ] [[package]] name = "regex-syntax" version = "0.6.22" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b5eb417147ba9860a96cfe72a0b93bf88fee1744b5636ec99ab20c1aa9376581" [[package]] name = "rustversion" version = "1.0.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "cb5d2a036dc6d2d8fd16fde3498b04306e29bd193bf306a57427019b823d5acd" [[package]] name = "ryu" version = "1.0.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "71d301d4193d031abdd79ff7e3dd721168a9572ef3fe51a1517aba235bd8f86e" [[package]] name = "same-file" version = "1.0.6" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "93fc1dc3aaa9bfed95e02e6eadabb4baf7e3078b0bd1b4d7b6b0b68378900502" dependencies = [ "winapi-util", ] [[package]] name = "scoped-tls" version = "1.0.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ea6a9290e3c9cf0f18145ef7ffa62d68ee0bf5fcd651017e586dc7fd5da448c2" [[package]] name = "scopeguard" version = "1.1.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d29ab0c6d3fc0ee92fe66e2d99f700eab17a8d57d1c1d3b748380fb20baa78cd" [[package]] name = "serde" version = "1.0.132" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "8b9875c23cf305cd1fd7eb77234cbb705f21ea6a72c637a5c6db5fe4b8e7f008" dependencies = [ "serde_derive", ] [[package]] name = "serde_derive" version = "1.0.132" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ecc0db5cb2556c0e558887d9bbdcf6ac4471e83ff66cf696e5419024d1606276" dependencies = [ "proc-macro2", "quote", "syn", ] [[package]] name = "serde_json" version = "1.0.73" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "bcbd0344bc6533bc7ec56df11d42fb70f1b912351c0825ccb7211b59d8af7cf5" dependencies = [ "itoa 1.0.1", "ryu", "serde", ] [[package]] name = "sha-1" version = "0.8.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "f7d94d0bede923b3cea61f3f1ff57ff8cdfd77b400fb8f9998949e0cf04163df" dependencies = [ "block-buffer", "digest", "fake-simd", "opaque-debug", ] [[package]] name = "slug" version = "0.1.4" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "b3bc762e6a4b6c6fcaade73e77f9ebc6991b676f88bb2358bddb56560f073373" dependencies = [ "deunicode", ] [[package]] name = "smallvec" version = "1.6.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "fe0f37c9e8f3c5a4a66ad655a93c74daac4ad00c441533bf5c6e7990bb42604e" [[package]] name = "strsim" version = "0.8.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "8ea5119cdb4c55b55d432abb513a0429384878c15dde60cc77b1c99de1a95a6a" [[package]] name = "syn" version = "1.0.60" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "c700597eca8a5a762beb35753ef6b94df201c81cca676604f547495a0d7f0081" dependencies = [ "proc-macro2", "quote", "unicode-xid", ] [[package]] name = "tera" version = "1.6.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "eac6ab7eacf40937241959d540670f06209c38ceadb62116999db4a950fbf8dc" dependencies = [ "chrono", "chrono-tz", "globwalk", "humansize", "lazy_static", "percent-encoding", "pest", "pest_derive", "rand", "regex", "serde", "serde_json", "slug", "unic-segment", ] [[package]] name = "term_size" version = "0.3.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "1e4129646ca0ed8f45d09b929036bafad5377103edd06e50bf574b353d2b08d9" dependencies = [ "libc", "winapi", ] [[package]] name = "termcolor" version = "1.1.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2dfed899f0eb03f32ee8c6a0aabdb8a7949659e3466561fc0adf54e26d88c5f4" dependencies = [ "winapi-util", ] [[package]] name = "textwrap" version = "0.11.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "d326610f408c7a4eb6f51c37c330e496b08506c9457c9d34287ecc38809fb060" dependencies = [ "term_size", "unicode-width", ] [[package]] name = "thread_local" version = "1.1.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "8018d24e04c95ac8790716a5987d0fec4f8b27249ffa0f7d33f1369bdfb88cbd" dependencies = [ "once_cell", ] [[package]] name = "time" version = "0.1.43" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ca8a50ef2360fbd1eeb0ecd46795a87a19024eb4b53c5dc916ca1fd95fe62438" dependencies = [ "libc", "winapi", ] [[package]] name = "tokei" version = "12.1.2" dependencies = [ "aho-corasick", "arbitrary", "clap", "colored", "crossbeam-channel", "dashmap", "dirs-next", "encoding_rs_io", "env_logger", "grep-searcher", "ignore", "log", "num-format", "once_cell", "parking_lot", "rayon", "regex", "serde", "serde_json", "tera", "term_size", "toml", ] [[package]] name = "tokei-fuzz" version = "0.0.1" dependencies = [ "arbitrary", "libfuzzer-sys", "tokei", ] [[package]] name = "toml" version = "0.5.8" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a31142970826733df8241ef35dc040ef98c679ab14d7c3e54d827099b3acecaa" dependencies = [ "serde", ] [[package]] name = "typenum" version = "1.12.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "373c8a200f9e67a0c95e62a4f52fbf80c23b4381c05a17845531982fa99e6b33" [[package]] name = "ucd-trie" version = "0.1.3" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "56dee185309b50d1f11bfedef0fe6d036842e3fb77413abef29f8f8d1c5d4c1c" [[package]] name = "unic-char-property" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "a8c57a407d9b6fa02b4795eb81c5b6652060a15a7903ea981f3d723e6c0be221" dependencies = [ "unic-char-range", ] [[package]] name = "unic-char-range" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "0398022d5f700414f6b899e10b8348231abf9173fa93144cbc1a43b9793c1fbc" [[package]] name = "unic-common" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "80d7ff825a6a654ee85a63e80f92f054f904f21e7d12da4e22f9834a4aaa35bc" [[package]] name = "unic-segment" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "e4ed5d26be57f84f176157270c112ef57b86debac9cd21daaabbe56db0f88f23" dependencies = [ "unic-ucd-segment", ] [[package]] name = "unic-ucd-segment" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "2079c122a62205b421f499da10f3ee0f7697f012f55b675e002483c73ea34700" dependencies = [ "unic-char-property", "unic-char-range", "unic-ucd-version", ] [[package]] name = "unic-ucd-version" version = "0.9.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "96bd2f2237fe450fcd0a1d2f5f4e91711124f7857ba2e964247776ebeeb7b0c4" dependencies = [ "unic-common", ] [[package]] name = "unicode-width" version = "0.1.8" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "9337591893a19b88d8d87f2cec1e73fad5cdfd10e5a6f349f498ad6ea2ffb1e3" [[package]] name = "unicode-xid" version = "0.2.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "f7fe0bb3479651439c9112f72b6c505038574c9fbb575ed1bf3b797fa39dd564" [[package]] name = "vec_map" version = "0.8.2" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "f1bddf1187be692e79c5ffeab891132dfb0f236ed36a43c7ed39f1165ee20191" [[package]] name = "walkdir" version = "2.3.1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "777182bc735b6424e1a57516d35ed72cb8019d85c8c9bf536dccb3445c1a2f7d" dependencies = [ "same-file", "winapi", "winapi-util", ] [[package]] name = "wasi" version = "0.10.2+wasi-snapshot-preview1" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "fd6fbd9a79829dd1ad0cc20627bf1ed606756a7f77edff7b66b7064f9cb327c6" [[package]] name = "winapi" version = "0.3.9" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "5c839a674fcd7a98952e593242ea400abe93992746761e38641405d28b00f419" dependencies = [ "winapi-i686-pc-windows-gnu", "winapi-x86_64-pc-windows-gnu", ] [[package]] name = "winapi-i686-pc-windows-gnu" version = "0.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "ac3b87c63620426dd9b991e5ce0329eff545bccbbb34f3be09ff6fb6ab51b7b6" [[package]] name = "winapi-util" version = "0.1.5" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "70ec6ce85bb158151cae5e5c87f95a8e97d2c0c4b001223f33a334e3ce5de178" dependencies = [ "winapi", ] [[package]] name = "winapi-x86_64-pc-windows-gnu" version = "0.4.0" source = "registry+https://github.com/rust-lang/crates.io-index" checksum = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f" 0707010000001F000081A400000000000000000000000166C8A4FD00000248000000000000000000000000000000000000002A00000000tokei-13.0.0.alpha.5+git0/fuzz/Cargo.toml [package] name = "tokei-fuzz" version = "0.0.1" authors = ["Michael Macnair"] publish = false edition = "2018" [package.metadata] cargo-fuzz = true [dependencies] libfuzzer-sys = "0.4" arbitrary = { version = "1.0.0", features = ["derive"] } [dependencies.tokei] path = ".." # Prevent this from interfering with workspaces [workspace] members = ["."] [[bin]] name = "parse_from_slice_total" path = "fuzz_targets/parse_from_slice_total.rs" test = false doc = false [[bin]] name = "parse_from_slice_panic" path = "fuzz_targets/parse_from_slice_panic.rs" test = false doc = false 07070100000020000081A400000000000000000000000166C8A4FD00000624000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/fuzz/README.md## Fuzzing Tokei Tokei can be fuzzed using libFuzzer, via [cargo-fuzz](https://github.com/rust-fuzz/cargo-fuzz/). First install cargo-fuzz: `cargo install cargo-fuzz`. To launch a fuzzing job: `cargo +nightly fuzz run <target>` - it will run until you kill it with ctrl-c. To use multiple cores: `cargo +nightly fuzz run <target> --jobs=6` To speed things up (at the expensive of missing bugs that only manifest in larger files): `cargo +nightly fuzz run <target> -- -max_len=200` Available fuzz targets: - `parse_from_slice_panic` - checks that all of the LanguageType instances' `parse_from_slice` function doesn't panic. - `parse_from_slice_total` - checks that the language stats pass a basic test of reporting no more total lines than there are new lines in the file. At the time of writing there are low-hanging bugs here. With the two `parse_from_slice` fuzz targets, it makes sense to share a common corpus directory as they have identical input formats, e.g.: `cargo +nightly fuzz run parse_from_slice_{panic,total} fuzz/corpus/common` Potential improvements: - Build the fuzz harnesses in CI, so they don't rot. - Do some coverage analysis to check if we're missing any code we would benefit from fuzzing (once it's [integrated into cargo-fuzz](https://github.com/rust-fuzz/cargo-fuzz/pull/248)) - Tighten the `parse_from_slice_total` fuzz target to check the total lines exactly matches the number of lines in the file. Only once any bugs found with the current fuzzer are fixed. - Check in a minimized corpus, and run regression over it in CI. 07070100000021000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000002C00000000tokei-13.0.0.alpha.5+git0/fuzz/fuzz_targets07070100000022000081A400000000000000000000000166C8A4FD000006DD000000000000000000000000000000000000004000000000tokei-13.0.0.alpha.5+git0/fuzz/fuzz_targets/parse_from_slice.rsuse arbitrary::Arbitrary; use std::str; use tokei::{Config, LanguageType}; #[derive(Arbitrary, Debug)] pub struct FuzzInput<'a> { lang: LanguageType, treat_doc_strings_as_comments: bool, data: &'a [u8], } // The first byte of data is used to select a language; remaining input is parsed // If check_total is true, asserts that the parsed stats pass a basic sanity test pub fn parse_from_slice(input: FuzzInput, check_total: bool) { let config = &Config { treat_doc_strings_as_comments: Some(input.treat_doc_strings_as_comments), // these options don't impact the behaviour of parse_from_slice: columns: None, hidden: None, no_ignore: None, no_ignore_parent: None, no_ignore_dot: None, no_ignore_vcs: None, sort: None, types: None, for_each_fn: None, }; // check that parsing doesn't panic let stats = input.lang.parse_from_slice(input.data, config); if check_total { // verify that the parsed total lines is not more than the total occurrences of \n and \r\n. // if/when all of the current discrepancies are fixed, we could make this stronger by checking it is equal. if let Ok(s) = str::from_utf8(input.data) { assert!( stats.lines() <= s.lines().count(), "{} got more total lines ({}) than str::lines ({}). Code: {}, Comments: {}, Blanks: {}. treat_doc_strings_as_comments: {}. File contents (as UTF-8):\n{}", input.lang.name(), stats.lines(), s.lines().count(), stats.code, stats.comments, input.treat_doc_strings_as_comments, stats.blanks, s ) }; } } 07070100000023000081A400000000000000000000000166C8A4FD000000C1000000000000000000000000000000000000004600000000tokei-13.0.0.alpha.5+git0/fuzz/fuzz_targets/parse_from_slice_panic.rs#![no_main] use libfuzzer_sys::fuzz_target; mod parse_from_slice; use parse_from_slice::{parse_from_slice, FuzzInput}; fuzz_target!(|data: FuzzInput| { parse_from_slice(data, false); }); 07070100000024000081A400000000000000000000000166C8A4FD000000C0000000000000000000000000000000000000004600000000tokei-13.0.0.alpha.5+git0/fuzz/fuzz_targets/parse_from_slice_total.rs#![no_main] use libfuzzer_sys::fuzz_target; mod parse_from_slice; use parse_from_slice::{parse_from_slice, FuzzInput}; fuzz_target!(|data: FuzzInput| { parse_from_slice(data, true); }); 07070100000025000081A400000000000000000000000166C8A4FD0000CF0D000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/languages.json{ "languages": { "Abap": { "name": "ABAP", "line_comment": ["*", "\\\""], "extensions": ["abap"] }, "ABNF": { "line_comment": [";"], "extensions": ["abnf"] }, "ActionScript": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["as"] }, "Ada": { "line_comment": ["--"], "extensions": ["ada", "adb", "ads", "pad"] }, "Agda": { "nested": true, "line_comment": ["--"], "multi_line_comments": [["{-", "-}"]], "extensions": ["agda"] }, "Alex": { "extensions": ["x"] }, "Alloy": { "line_comment": ["--", "//"], "multi_line_comments": [["/*", "*/"]], "extensions": ["als"] }, "Arduino": { "name": "Arduino C++", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["ino"] }, "Arturo": { "line_comment": [";"], "quotes": [["\\\"", "\\\""]], "extensions": ["art"] }, "AsciiDoc": { "line_comment": ["//"], "multi_line_comments": [["////", "////"]], "extensions": ["adoc", "asciidoc"] }, "Asn1": { "name": "ASN.1", "line_comment": ["--"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "multi_line_comments": [["/*", "*/"]], "extensions": ["asn1"] }, "Asp": { "name": "ASP", "line_comment": ["'", "REM"], "extensions": ["asa", "asp"] }, "AspNet": { "name": "ASP.NET", "multi_line_comments": [["<!--", "-->"], ["<%--", "-->"]], "extensions": [ "asax", "ascx", "asmx", "aspx", "master", "sitemap", "webinfo" ] }, "Assembly": { "line_comment": [";"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["asm"] }, "AssemblyGAS": { "name": "GNU Style Assembly", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["s"] }, "Astro": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"], ["<!--", "-->"]], "extensions": ["astro"] }, "Ats": { "name": "ATS", "line_comment": ["//"], "multi_line_comments": [["(*", "*)"], ["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": [ "dats", "hats", "sats", "atxt" ] }, "Autoconf": { "line_comment": ["#", "dnl"], "extensions": ["in"] }, "Autoit": { "line_comment": [";"], "multi_line_comments": [["#comments-start", "#comments-end"], ["#cs", "#ce"]], "extensions": ["au3"] }, "AutoHotKey": { "line_comment": [";"], "multi_line_comments": [["/*", "*/"]], "extensions": ["ahk"] }, "Automake": { "line_comment": ["#"], "extensions": ["am"] }, "AWK": { "line_comment": ["#"], "shebangs": ["#!/bin/awk -f"], "extensions": ["awk"] }, "Bash": { "name": "BASH", "shebangs": ["#!/bin/bash"], "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["bash"], "extensions": ["bash"] }, "Batch": { "line_comment": ["REM", "::"], "extensions": ["bat", "btm", "cmd"] }, "Bazel": { "line_comment": ["#"], "doc_quotes": [["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["'''", "'''"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["bzl", "bazel", "bzlmod"], "filenames": ["build", "workspace", "module"] }, "Bean": { "line_comment": [";"], "quotes": [["\\\"", "\\\""]], "extensions": ["bean", "beancount"] }, "Bicep" : { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["'", "'"], ["'''", "'''"]], "extensions": ["bicep", "bicepparam"] }, "Bitbake": { "name": "Bitbake", "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["bb", "bbclass", "bbappend", "inc", "conf"] }, "BrightScript": { "quotes": [["\\\"", "\\\""]], "line_comment": ["'", "REM"], "extensions": ["brs"] }, "C": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["c", "ec", "pgc"] }, "Cabal": { "nested": true, "line_comment": ["--"], "multi_line_comments": [["{-", "-}"]], "extensions": ["cabal"] }, "Cangjie": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "nested": true, "quotes": [["\\\"", "\\\""],["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "verbatim_quotes": [["#\\\"", "\\\"#"],["##\\\"", "\\\"##"],["###\\\"", "\\\"###"], ["#'", "'#"],["##'", "'##"],["###'", "'###"]], "extensions": ["cj"] }, "Cassius": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["cassius"] }, "Ceylon": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "extensions": ["ceylon"] }, "Chapel": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["chpl"] }, "CHeader": { "name": "C Header", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["h"] }, "Cil": { "name": "CIL (SELinux)", "line_comment": [";"], "quotes": [["\\\"", "\\\""]], "extensions": ["cil"] }, "Circom": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "extensions": ["circom"] }, "Clojure": { "line_comment": [";"], "quotes": [["\\\"", "\\\""]], "extensions": ["clj"] }, "ClojureC": { "line_comment": [";"], "quotes": [["\\\"", "\\\""]], "extensions": ["cljc"] }, "ClojureScript": { "line_comment": [";"], "quotes": [["\\\"", "\\\""]], "extensions": ["cljs"] }, "CMake": { "line_comment": ["#"], "quotes": [["\\\"", "\\\""]], "extensions": ["cmake"], "filenames": ["cmakelists.txt"] }, "Cobol": { "name": "COBOL", "line_comment": ["*"], "extensions": ["cob", "cbl", "ccp", "cobol", "cpy"] }, "CodeQL": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["ql", "qll"] }, "CoffeeScript": { "line_comment": ["#"], "multi_line_comments": [["###", "###"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["coffee", "cjsx"] }, "Cogent": { "line_comment": ["--"], "extensions": ["cogent"] }, "ColdFusion": { "multi_line_comments": [["<!---", "--->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["cfm"] }, "ColdFusionScript": { "name": "ColdFusion CFScript", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["cfc"] }, "Coq": { "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["(*", "*)"]], "extensions": ["v"] }, "Cpp": { "name": "C++", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "verbatim_quotes": [["R\\\"(", ")\\\""]], "extensions": ["cc", "cpp", "cxx", "c++", "pcc", "tpp"] }, "CppHeader": { "name": "C++ Header", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["hh", "hpp", "hxx", "inl", "ipp"] }, "Crystal": { "line_comment": ["#"], "shebangs": ["#!/usr/bin/crystal"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["crystal"], "extensions": ["cr"] }, "CSharp": { "name": "C#", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "verbatim_quotes": [["@\\\"", "\\\""]], "extensions": ["cs", "csx"] }, "CShell": { "name": "C Shell", "shebangs": ["#!/bin/csh"], "line_comment": ["#"], "env": ["csh"], "extensions": ["csh"] }, "Css": { "name": "CSS", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "mime": ["text/css"], "extensions": ["css"] }, "Cuda": { "name": "CUDA", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["cu"] }, "Cue": { "name": "CUE", "line_comment": ["//"], "quotes": [ ["\\\"", "\\\""], ["'", "'"], ["\\\"\\\"\\\"", "\\\"\\\"\\\""] ], "verbatim_quotes": [["#\\\"", "\\\"#"]], "extensions": ["cue"] }, "Cython": { "line_comment": ["#"], "doc_quotes": [["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["'''", "'''"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["cython"], "extensions": ["pyx", "pxd", "pxi"] }, "D": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "nested_comments": [["/+", "+/"]], "extensions": ["d"] }, "D2": { "line_comment": ["#"], "multi_line_comments": [["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "extensions": ["d2"] }, "Daml": { "name": "DAML", "nested": true, "line_comment": ["-- "], "multi_line_comments": [["{-", "-}"]], "extensions": ["daml"] }, "Dart": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [ ["\\\"", "\\\""], ["'", "'"], ["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["'''", "'''"] ], "extensions": ["dart"] }, "DeviceTree": { "name": "Device Tree", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["dts", "dtsi"] }, "Dhall":{ "nested": true, "line_comment": ["--"], "multi_line_comments": [["{-", "-}"]], "quotes": [["\\\"", "\\\""], ["''", "''"]], "extensions": ["dhall"] }, "Dockerfile": { "line_comment": ["#"], "extensions": ["dockerfile", "dockerignore"], "filenames": ["dockerfile"], "quotes": [["\\\"", "\\\""], ["'", "'"]] }, "DotNetResource": { "name": ".NET Resource", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""]], "extensions": ["resx"] }, "DreamMaker": { "name": "Dream Maker", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "nested": true, "extensions": ["dm", "dme"], "quotes": [["\\\"", "\\\""], ["{\\\"", "\\\"}"], ["'", "'"]] }, "Dust": { "name": "Dust.js", "multi_line_comments": [["{!", "!}"]], "extensions": ["dust"] }, "Ebuild": { "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["ebuild", "eclass"] }, "EdgeQL": { "name": "EdgeQL", "line_comment": ["#"], "quotes": [["'", "'"], ["\\\"", "\\\""], ["$", "$"]], "extensions": ["edgeql"] }, "ESDL": { "name": "EdgeDB Schema Definition", "line_comment": ["#"], "quotes": [["'", "'"], ["\\\"", "\\\""]], "extensions": ["esdl"] }, "Edn": { "line_comment": [";"], "extensions": ["edn"] }, "Elisp": { "name": "Emacs Lisp", "line_comment": [";"], "extensions": ["el"] }, "Elixir": { "line_comment": ["#"], "quotes": [ ["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["\\\"", "\\\""], ["'''", "'''"], ["'", "'"] ], "extensions": ["ex", "exs"] }, "Elm": { "nested": true, "line_comment": ["--"], "multi_line_comments": [["{-", "-}"]], "extensions": ["elm"] }, "Elvish": { "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["elvish"], "extensions": ["elv"] }, "EmacsDevEnv": { "name": "Emacs Dev Env", "line_comment": [";"], "extensions": ["ede"] }, "Emojicode": { "line_comment": ["💭"], "multi_line_comments": [["💭🔜", "🔚💭"], ["📗", "📗"], ["📘", "📘"]], "quotes": [["❌🔤", "❌🔤"]], "extensions": ["emojic", "🍇"] }, "Erlang": { "line_comment": ["%"], "extensions": ["erl", "hrl"] }, "Factor": { "line_comment": ["!", "#!"], "multi_line_comments": [["/*", "*/"]], "extensions": ["factor"] }, "FEN": { "name": "FEN", "blank": true, "extensions": ["fen"] }, "Fennel" : { "line_comment": [";", ";;"], "quotes": [["\\\"", "\\\""]], "extensions": ["fnl"] }, "Fish": { "shebangs": ["#!/bin/fish"], "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["fish"], "extensions": ["fish"] }, "FlatBuffers": { "name": "FlatBuffers Schema", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["fbs"] }, "ForgeConfig": { "name": "Forge Config", "line_comment": ["#", "~"], "extensions": ["cfg"] }, "Forth": { "line_comment": ["\\\\"], "multi_line_comments": [["( ", ")"]], "extensions": [ "4th", "forth", "fr", "frt", "fth", "f83", "fb", "fpm", "e4", "rx", "ft" ] }, "FortranLegacy": { "name": "FORTRAN Legacy", "line_comment": ["c", "C", "!", "*"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["f", "for", "ftn", "f77", "pfo"] }, "FortranModern": { "name": "FORTRAN Modern", "line_comment": ["!"], "quotes": [["\\\"", "\\\""]], "extensions": ["f03", "f08", "f90", "f95", "fpp"] }, "FreeMarker": { "multi_line_comments": [["<#--", "-->"]], "extensions": ["ftl", "ftlh", "ftlx"] }, "FSharp": { "name": "F#", "line_comment": ["//"], "multi_line_comments": [["(*", "*)"]], "quotes": [["\\\"", "\\\""]], "verbatim_quotes": [["@\\\"", "\\\""]], "extensions": ["fs", "fsi", "fsx", "fsscript"] }, "Fstar": { "name": "F*", "quotes": [["\\\"", "\\\""]], "line_comment": ["//"], "multi_line_comments": [["(*", "*)"]], "extensions": ["fst"] }, "Futhark": { "line_comment": ["--"], "extensions": ["fut"] }, "GDB": { "name": "GDB Script", "line_comment": ["#"], "extensions": ["gdb"] }, "GdScript": { "name": "GDScript", "line_comment": ["#"], "quotes": [ ["\\\"", "\\\""], ["'", "'"], ["\\\"\\\"\\\"", "\\\"\\\"\\\""] ], "extensions": ["gd"] }, "Gherkin": { "name": "Gherkin (Cucumber)", "line_comment": ["#"], "extensions": ["feature"] }, "Gleam": { "name": "Gleam", "line_comment": ["//", "///", "////"], "quotes": [["\\\"", "\\\""]], "extensions": ["gleam"] }, "GlimmerJs": { "name": "Glimmer JS", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"], ["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "important_syntax": ["<template", "<style"], "extensions": ["gjs"] }, "GlimmerTs": { "name": "Glimmer TS", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"], ["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "important_syntax": ["<template", "<style"], "extensions": ["gts"] }, "Glsl": { "name": "GLSL", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["vert", "tesc", "tese", "geom", "frag", "comp", "mesh", "task", "rgen", "rint", "rahit", "rchit", "rmiss", "rcall", "glsl"] }, "Gml": { "name": "Gml", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["gml"] }, "Go": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["go"] }, "Gohtml": { "name": "Go HTML", "multi_line_comments": [["<!--", "-->"], ["{{/*", "*/}}"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["gohtml"] }, "Graphql": { "name": "GraphQL", "quotes": [["\\\"", "\\\""], ["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "line_comment": ["#"], "extensions": ["gql", "graphql"] }, "Groovy": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "env": ["groovy"], "extensions": ["groovy", "grt", "gtpl", "gvy"] }, "Gwion": { "line_comment": ["#!"], "quotes": [["\\\"", "\\\""]], "extensions": ["gw"] }, "Haml": { "line_comment": ["-#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["haml"] }, "Hamlet": { "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["hamlet"] }, "Happy": { "extensions": ["y", "ly"] }, "Handlebars": { "multi_line_comments": [["<!--", "-->"], ["{{!", "}}"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["hbs", "handlebars"] }, "Haskell": { "nested": true, "line_comment": ["--"], "multi_line_comments": [["{-", "-}"]], "extensions": ["hs"] }, "Haxe": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["hx"] }, "Hcl": { "name": "HCL", "line_comment": ["#", "//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["hcl", "tf", "tfvars"] }, "Headache": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["ha"] }, "Hex": { "name": "HEX", "blank": true, "extensions": ["hex"] }, "HiCad": { "name": "HICAD", "line_comment": ["REM", "rem"], "extensions": ["MAC", "mac"] }, "Hlsl": { "name": "HLSL", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["hlsl"] }, "HolyC": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["HC", "hc","ZC","zc"] }, "Html": { "name": "HTML", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "kind": "html", "important_syntax": ["<script", "<style"], "mime": ["text/html"], "extensions": ["html", "htm"] }, "Hy": { "line_comment": [";"], "extensions": ["hy"] }, "Idris": { "line_comment": ["--"], "multi_line_comments": [["{-", "-}"]], "quotes": [["\\\"", "\\\""], ["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "extensions": ["idr", "lidr"], "nested": true }, "Ini": { "name": "INI", "line_comment": [";", "#"], "extensions": ["ini"] }, "IntelHex": { "name": "Intel HEX", "blank": true, "extensions": ["ihex"] }, "Isabelle": { "line_comment": ["--"], "multi_line_comments": [ ["{*", "*}"], ["(*", "*)"], ["‹", "›"], ["\\\\<open>", "\\\\<close>"] ], "quotes": [["''", "''"]], "extensions": ["thy"] }, "Jai": { "name": "JAI", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["jai"], "nested": true }, "Janet": { "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "extensions": ["janet"] }, "Java": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["java"] }, "JavaScript": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "mime": [ "application/javascript", "application/ecmascript", "application/x-ecmascript", "application/x-javascript", "text/javascript", "text/ecmascript", "text/javascript1.0", "text/javascript1.1", "text/javascript1.2", "text/javascript1.3", "text/javascript1.4", "text/javascript1.5", "text/jscript", "text/livescript", "text/x-ecmascript", "text/x-javascript" ], "extensions": ["cjs", "js", "mjs"] }, "Jinja2": { "name": "Jinja2", "blank": true, "extensions": ["j2", "jinja"], "multi_line_comments": [["{#", "#}"]] }, "Jq": { "name": "jq", "line_comment": ["#"], "quotes": [["\\\"", "\\\""]], "extensions": ["jq"] }, "JSLT": { "name": "JSLT", "line_comment": ["//"], "quotes": [["\\\"", "\\\""]], "extensions": ["jslt"] }, "Json": { "name": "JSON", "blank": true, "mime": ["application/json", "application/manifest+json"], "extensions": ["json"] }, "Jsonnet": { "line_comment": ["//", "#"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["jsonnet", "libsonnet"] }, "Jsx": { "name": "JSX", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "extensions": ["jsx"] }, "Julia": { "line_comment": ["#"], "multi_line_comments": [["#=", "=#"]], "quotes": [["\\\"", "\\\""], ["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "nested": true, "extensions": ["jl"] }, "Julius": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "extensions": ["julius"] }, "Jupyter": { "name": "Jupyter Notebooks", "extensions": ["ipynb"] }, "K": { "name": "K", "nested": true, "line_comment": ["/"], "quotes": [["\\\"", "\\\""]], "extensions": ["k"] }, "KakouneScript": { "name": "Kakoune script", "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["kak"] }, "Kotlin": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "nested": true, "quotes": [["\\\"", "\\\""], ["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "extensions": ["kt", "kts"] }, "Ksh": { "name": "Korn shell", "shebangs": ["#!/bin/ksh"], "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["ksh"], "extensions": ["ksh"] }, "Lalrpop": { "name": "LALRPOP", "line_comment": ["//"], "extensions": ["lalrpop"], "quotes": [["\\\"", "\\\""], ["#\\\"", "\\\"#"]], "verbatim_quotes": [["r##\\\"", "\\\"##"], ["r#\\\"", "\\\"#"]] }, "KvLanguage": { "name":"KV Language", "line_comment": ["# "], "doc_quotes": [["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["'''", "'''"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["kv"] }, "Lean": { "line_comment": ["--"], "multi_line_comments": [["/-", "-/"]], "nested": true, "extensions": ["lean", "hlean"] }, "Hledger": { "name": "hledger", "line_comment": [";", "#"], "multi_line_comments": [["comment", "end comment"]], "nested": false, "extensions": ["hledger"] }, "Less": { "name": "LESS", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "extensions": ["less"], "quotes": [["\\\"", "\\\""], ["'", "'"]] }, "Lex": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "extensions": ["l", "lex"] }, "Liquid": { "name": "Liquid", "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["liquid"], "multi_line_comments": [["<!--", "-->"], ["{% comment %}", "{% endcomment %}"]] }, "LinguaFranca": { "name": "Lingua Franca", "line_comment": ["//", "#"], "important_syntax": ["{="], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "nested": true, "extensions": ["lf"] }, "LinkerScript": { "name": "LD Script", "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["ld", "lds"] }, "Lisp": { "name": "Common Lisp", "line_comment": [";"], "multi_line_comments": [["#|", "|#"]], "nested": true, "extensions": ["lisp", "lsp", "asd"] }, "LiveScript": { "line_comment": ["#"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["ls"] }, "LLVM": { "line_comment": [";"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["ll"] }, "Logtalk": { "line_comment": ["%"], "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["/*", "*/"]], "extensions": ["lgt", "logtalk"] }, "LolCode": { "name": "LOLCODE", "line_comment": ["BTW"], "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["OBTW", "TLDR"]], "extensions": ["lol"] }, "Lua": { "line_comment": ["--"], "multi_line_comments": [["--[[", "]]"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["lua", "luau"] }, "Lucius": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["lucius"] }, "M4": { "extensions": ["m4"], "line_comment": ["#", "dnl"], "quotes": [["`", "'"]] }, "Madlang": { "extensions": ["mad"], "line_comment": ["#"], "multi_line_comments": [["{#", "#}"]] }, "Makefile": { "line_comment": ["#"], "extensions": ["makefile", "mak", "mk"], "filenames": ["makefile"] }, "Markdown": { "literate": true, "important_syntax": ["```"], "extensions": ["md", "markdown"] }, "Max": { "extensions": ["maxpat"] }, "Mdx": { "name": "MDX", "literate": true, "important_syntax": ["```"], "extensions": ["mdx"] }, "Menhir": { "nested": true, "quotes": [["\\\"", "\\\""]], "line_comment": ["//"], "multi_line_comments": [ ["(*", "*)"], ["/*", "*/"] ], "extensions": ["mll", "mly", "vy"] }, "Meson": { "line_comment": ["#"], "quotes": [["'", "'"], ["'''", "'''"]], "filenames": ["meson.build", "meson_options.txt"] }, "Metal": { "name": "Metal Shading Language", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["metal"] }, "Mint": { "blank": true, "extensions": ["mint"] }, "Mlatu": { "line_comment": ["//"], "quotes": [["\\\"", "\\\""]], "extensions": ["mlt"] }, "Modelica": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["mo", "mos"] }, "ModuleDef": { "name": "Module-Definition", "extensions": ["def"], "line_comment": [";"] }, "MonkeyC": { "name": "Monkey C", "extensions": ["mc"], "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]] }, "MoonBit": { "line_comment": ["//"], "quotes": [["\\\"", "\\\""]], "extensions": ["mbt"] }, "MoonScript": { "line_comment": ["--"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["moon"] }, "MsBuild": { "name": "MSBuild", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["csproj", "vbproj", "fsproj", "props", "targets"] }, "Mustache": { "multi_line_comments": [["{{!", "}}"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["mustache"] }, "Nextflow": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["nextflow", "nf"] }, "Nim": { "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "extensions": ["nim"] }, "Nix": { "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "line_comment": ["#"], "extensions": ["nix"] }, "NotQuitePerl": { "name": "Not Quite Perl", "line_comment": ["#"], "multi_line_comments": [["=begin", "=end"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["nqp"] }, "NuGetConfig": { "name": "NuGet Config", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "filenames": ["nuget.config", "packages.config", "nugetdefaults.config"] }, "Nushell": { "line_comment": ["#"], "quotes": [ ["\\\"", "\\\""], ["'", "'"] ], "extensions": ["nu"] }, "ObjectiveC": { "name": "Objective-C", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["m"] }, "ObjectiveCpp": { "name": "Objective-C++", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["mm"] }, "OCaml": { "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["(*", "*)"]], "extensions": ["ml", "mli", "re", "rei"] }, "Odin": { "extensions": ["odin"], "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]] }, "OpenScad": { "name": "OpenSCAD", "extensions": ["scad"], "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]] }, "OpenPolicyAgent": { "name": "Open Policy Agent", "line_comment": ["#"], "quotes": [["\\\"","\\\""], ["`", "`"]], "extensions": ["rego"] }, "OpenCL": { "name": "OpenCL", "multi_line_comments": [["/*", "*/"]], "extensions": ["cl", "ocl"] }, "OpenQasm": { "name": "OpenQASM", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "extensions": ["qasm"] }, "OpenType": { "name": "OpenType Feature File", "line_comment": ["#"], "extensions": ["fea"] }, "Org": { "line_comment": ["# "], "extensions": ["org"] }, "Oz": { "line_comment": ["%"], "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["/*", "*/"]], "extensions": ["oz"] }, "PacmanMakepkg": { "name": "Pacman's makepkg", "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "filenames": ["pkgbuild"] }, "Pan": { "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["pan", "tpl"] }, "Pascal": { "nested": true, "line_comment": ["//"], "multi_line_comments": [["{", "}"], ["(*", "*)"]], "quotes": [["'", "'"]], "extensions": ["pas"] }, "Perl": { "shebangs": ["#!/usr/bin/perl"], "line_comment": ["#"], "multi_line_comments": [["=pod", "=cut"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["pl", "pm"] }, "Pest": { "line_comment": ["//"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["pest"] }, "Php": { "name": "PHP", "line_comment": ["#", "//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["php"] }, "PlantUml": { "name": "PlantUML", "line_comment": ["'"], "multi_line_comments": [["/'", "'/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["puml"] }, "Po": { "name": "PO File", "line_comment": ["#"], "extensions": ["po", "pot"] }, "Poke": { "multi_line_comments": [["/*", "*/"]], "extensions": ["pk"] }, "Polly": { "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["polly"] }, "Pony": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "doc_quotes": [["\\\"\\\"\\\"", "\\\"\\\"\\\""]], "extensions": ["pony"] }, "PostCss": { "name": "PostCSS", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["pcss", "sss"] }, "PowerShell": { "line_comment": ["#"], "multi_line_comments": [["<#", "#>"]], "quotes": [ ["\\\"", "\\\""], ["'", "'"], ["\\\"@", "@\\\""], ["@'", "'@"] ], "extensions": ["ps1", "psm1", "psd1", "ps1xml", "cdxml", "pssc", "psc1"] }, "Processing": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["pde"] }, "Prolog": { "line_comment": ["%"], "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["/*", "*/"]], "extensions": ["p", "pro"] }, "PSL": { "name": "PSL Assertion", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["psl"] }, "Protobuf": { "name": "Protocol Buffers", "line_comment": ["//"], "extensions": ["proto"] }, "Pug" : { "line_comment": ["//", "//-"], "quotes": [ ["#{\\\"", "\\\"}"], ["#{'", "'}"], ["#{`", "`}"] ], "extensions": ["pug"] }, "Puppet": { "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["pp"] }, "PureScript": { "nested": true, "line_comment": ["--"], "multi_line_comments": [["{-", "-}"]], "extensions": ["purs"] }, "Python": { "line_comment": ["#"], "doc_quotes": [["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["'''", "'''"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["python", "python2", "python3"], "mime": ["text/x-python"], "extensions": ["py", "pyw", "pyi"] }, "PRQL": { "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "mime": ["application/prql"], "extensions": ["prql"] }, "Q": { "name": "Q", "nested": true, "line_comment": ["/"], "quotes": [["\\\"", "\\\""]], "extensions": ["q"] }, "Qcl": { "name": "QCL", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["qcl"] }, "Qml": { "name": "QML", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["qml"] }, "R": { "line_comment": ["#"], "extensions": ["r"] }, "Racket": { "line_comment": [";"], "multi_line_comments": [["#|", "|#"]], "nested": true, "env": ["racket"], "extensions": ["rkt", "scrbl"] }, "Rakefile": { "line_comment": ["#"], "multi_line_comments": [["=begin", "=end"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "filenames": ["rakefile"], "extensions": ["rake"] }, "Raku": { "shebangs": ["#!/usr/bin/raku", "#!/usr/bin/perl6"], "line_comment": ["#"], "multi_line_comments": [ ["#`(", ")"], ["#`[", "]"], ["#`{", "}"], ["#`「", "」"] ], "nested": true, "quotes": [["\\\"", "\\\""] , ["'", "'"]], "verbatim_quotes": [["「", "」"]], "doc_quotes": [ ["#|{", "}"], ["#={", "}"], ["#|(", ")"], ["#=(", ")"], ["#|[", "]"], ["#=[", "]"], ["#|「", "」"], ["#=「", "」"], ["=begin pod", "=end pod"], ["=begin code", "=end code"], ["=begin head", "=end head"], ["=begin item", "=end item"], ["=begin table", "=end table"], ["=begin defn", "=end defn"], ["=begin para", "=end para"], ["=begin comment", "=end comment"], ["=begin data", "=end data"], ["=begin DESCRIPTION", "=end DESCRIPTION"], ["=begin SYNOPSIS", "=end SYNOPSIS"], ["=begin ", "=end "] ], "env": ["raku", "perl6"], "extensions": ["raku", "rakumod", "rakutest", "pm6", "pl6", "p6"] }, "Razor": { "line_comment": ["//"], "multi_line_comments": [["<!--", "-->"], ["@*", "*@"], ["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "verbatim_quotes": [["@\\\"", "\\\""]], "extensions": ["cshtml", "razor"] }, "Redscript": { "name": "Redscript", "line_comment": ["//", "///"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "nested": true, "extensions": ["reds"] }, "Renpy": { "name": "Ren'Py", "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "extensions": ["rpy"] }, "ReScript": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["res", "resi"] }, "ReStructuredText": { "blank": true, "extensions": ["rst"] }, "RON": { "name": "Rusty Object Notation", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "nested": true, "extensions": ["ron"] }, "RPMSpecfile": { "name": "RPM Specfile", "line_comment": ["#"], "extensions": ["spec"] }, "Ruby": { "line_comment": ["#"], "multi_line_comments": [["=begin", "=end"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["ruby"], "extensions": ["rb"] }, "RubyHtml": { "name": "Ruby HTML", "multi_line_comments": [["<!--", "-->"]], "important_syntax": ["<script", "<style"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["rhtml", "erb"] }, "Rust": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "nested": true, "important_syntax": ["///", "//!"], "extensions": ["rs"], "quotes": [["\\\"", "\\\""], ["#\\\"", "\\\"#"]], "verbatim_quotes": [["r##\\\"", "\\\"##"], ["r#\\\"", "\\\"#"]] }, "Sass": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["sass", "scss"] }, "Scala": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["sc", "scala"] }, "Scheme": { "line_comment": [";"], "multi_line_comments": [["#|", "|#"]], "nested": true, "extensions": ["scm", "ss"] }, "Scons": { "line_comment": ["#"], "quotes": [ ["\\\"", "\\\""], ["'", "'"], ["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["'''", "'''"] ], "filenames": ["sconstruct", "sconscript"] }, "Sh": { "name": "Shell", "shebangs": ["#!/bin/sh"], "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "env": ["sh"], "extensions": ["sh"] }, "ShaderLab": { "name": "ShaderLab", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["shader", "cginc"] }, "Slang": { "name": "Slang", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["slang"] }, "Sml": { "name": "Standard ML (SML)", "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["(*", "*)"]], "extensions": ["sml"] }, "Smalltalk": { "name": "Smalltalk", "quotes": [["'", "'"]], "multi_line_comments": [["\\\"", "\\\""]], "extensions": ["cs.st", "pck.st"] }, "Snakemake": { "line_comment": ["#"], "doc_quotes": [["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["'''", "'''"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["smk", "rules"], "filenames": ["snakefile"] }, "Solidity": { "name": "Solidity", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["sol"] }, "SpecmanE": { "name": "Specman e", "line_comment": ["--", "//"], "multi_line_comments": [["'>", "<'"]], "extensions": ["e"] }, "Spice": { "name": "Spice Netlist", "line_comment": ["*"], "extensions": ["ckt"] }, "Sql": { "name": "SQL", "line_comment": ["--"], "multi_line_comments": [["/*", "*/"]], "quotes": [["'", "'"]], "extensions": ["sql"] }, "Sqf": { "name": "SQF", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["sqf"] }, "SRecode": { "name": "SRecode Template", "line_comment": [";;"], "extensions": ["srt"] }, "Stan": { "line_comment": ["//", "#"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["stan"] }, "Stata": { "line_comment": ["//", "*"], "multi_line_comments": [["/*", "*/"]], "extensions": ["do"] }, "Stratego": { "name": "Stratego/XT", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["$[", "]"], ["$<", ">"], ["${", "}"]], "extensions": ["str"] }, "Stylus": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["styl"] }, "Svelte": { "multi_line_comments": [["<!--", "-->"]], "important_syntax": ["<script", "<style"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["svelte"] }, "Svg": { "name": "SVG", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "mime": ["image/svg+xml"], "extensions": ["svg"] }, "Swift": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "nested": true, "extensions": ["swift"] }, "Swig": { "name": "SWIG", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "nested": true, "extensions": ["swg", "i"] }, "SystemVerilog": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["sv", "svh"] }, "Tact": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["tact"] }, "Tcl": { "name": "TCL", "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["tcl"] }, "Tera": { "multi_line_comments": [["<!--", "-->"], ["{#", "#}"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["tera"] }, "Tex": { "name": "TeX", "line_comment": ["%"], "extensions": ["tex", "sty"] }, "Text": { "name": "Plain Text", "literate": true, "mime": ["text/plain"], "extensions": ["text", "txt"] }, "Thrift": { "line_comment": ["#", "//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["thrift"] }, "Toml": { "name": "TOML", "line_comment": ["#"], "quotes": [ ["\\\"", "\\\""], ["'", "'"], ["\\\"\\\"\\\"", "\\\"\\\"\\\""], ["'''", "'''"] ], "extensions": ["toml"] }, "Tsx": { "name": "TSX", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "extensions": ["tsx"] }, "Ttcn": { "name": "TTCN-3", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["ttcn", "ttcn3", "ttcnpp"] }, "Twig": { "name": "Twig", "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["twig"], "multi_line_comments": [["<!--", "-->"], ["{#", "#}"]] }, "TypeScript": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "extensions": ["ts", "mts", "cts"] }, "Typst": { "nested": true, "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["typ"] }, "UMPL": { "line_comment": ["!"], "quotes": [["`", "`"]], "extensions": ["umpl"] }, "Unison": { "nested": true, "line_comment": ["--"], "multi_line_comments": [["{-", "-}"]], "quotes": [["\\\"", "\\\""]], "extensions": ["u"] }, "UnrealDeveloperMarkdown": { "name": "Unreal Markdown", "important_syntax": ["```"], "extensions": ["udn"] }, "UnrealPlugin": { "name": "Unreal Plugin", "blank": true, "extensions": ["uplugin"] }, "UnrealProject": { "name": "Unreal Project", "blank": true, "extensions": ["uproject"] }, "UnrealScript": { "name": "Unreal Script", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["uc", "uci", "upkg"] }, "UnrealShader": { "name": "Unreal Shader", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["usf"] }, "UnrealShaderHeader": { "name": "Unreal Shader Header", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["ush"] }, "UrWeb": { "name": "Ur/Web", "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["(*", "*)"]], "extensions": ["ur", "urs"] }, "UrWebProject": { "name": "Ur/Web Project", "line_comment": ["#"], "extensions": ["urp"] }, "Vala": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["vala"] }, "VB6": { "name": "VB6", "line_comment": ["'"], "extensions": ["frm", "bas", "cls"] }, "VBScript": { "name": "VBScript", "line_comment": ["'", "REM"], "extensions": ["vbs"] }, "Velocity": { "name": "Apache Velocity", "line_comment": ["##"], "multi_line_comments": [["#*", "*#"]], "extensions": ["vm"], "quotes": [["'", "'"], ["\\\"", "\\\""]] }, "Verilog": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""]], "extensions": ["vg", "vh"] }, "VerilogArgsFile": { "name": "Verilog Args File", "extensions": ["irunargs", "xrunargs"] }, "Vhdl": { "name": "VHDL", "line_comment": ["--"], "multi_line_comments": [["/*", "*/"]], "extensions": ["vhd", "vhdl"] }, "VisualBasic": { "name": "Visual Basic", "quotes": [["\\\"", "\\\""]], "line_comment": ["'"], "extensions": ["vb"] }, "VisualStudioProject": { "name": "Visual Studio Project", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["vcproj", "vcxproj"] }, "VisualStudioSolution": { "name": "Visual Studio Solution", "blank": true, "extensions": ["sln"] }, "VimScript": { "name": "Vim Script", "line_comment": ["\\\""], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["vim"] }, "Vue": { "name": "Vue", "line_comment": ["//"], "multi_line_comments": [["<!--", "-->"], ["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["`", "`"]], "important_syntax": ["<script", "<style", "<template"], "extensions": ["vue"] }, "WebAssembly": { "line_comment": [";;"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["wat", "wast"] }, "WenYan":{ "name":"The WenYan Programming Language", "multi_line_comments":[["批曰。","。"],["疏曰。","。"]], "extensions":["wy"] }, "WGSL": { "name": "WebGPU Shader Language", "line_comment": ["//"], "extensions": ["wgsl"] }, "Wolfram": { "quotes": [["\\\"", "\\\""]], "multi_line_comments": [["(*", "*)"]], "extensions": ["nb", "wl"] }, "Xaml": { "name": "XAML", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["xaml"] }, "XcodeConfig": { "name": "Xcode Config", "line_comment": ["//"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["xcconfig"] }, "Xml": { "name": "XML", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["xml"] }, "XSL": { "name": "XSL", "multi_line_comments": [["<!--", "-->"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["xsl", "xslt"] }, "Xtend": { "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"], ["'''", "'''"]], "extensions": ["xtend"] }, "Yaml": { "name": "YAML", "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["yaml", "yml"] }, "ZenCode": { "line_comment": ["//", "#"], "multi_line_comments": [["/*", "*/"]], "quotes": [["\\\"", "\\\""], ["'", "'"]], "verbatim_quotes": [["@\\\"", "\\\""], ["@'", "'"]], "extensions": ["zs"] }, "Zig": { "line_comment": ["//"], "quotes": [["\\\"", "\\\""]], "extensions": ["zig"] }, "Zokrates": { "name": "ZoKrates", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "extensions": ["zok"] }, "Zsh": { "shebangs": ["#!/bin/zsh"], "line_comment": ["#"], "quotes": [["\\\"", "\\\""], ["'", "'"]], "extensions": ["zsh"] }, "GdShader": { "name": "GDShader", "line_comment": ["//"], "multi_line_comments": [["/*", "*/"]], "extensions": ["gdshader"] } } } 07070100000026000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000001E00000000tokei-13.0.0.alpha.5+git0/src07070100000027000081A400000000000000000000000166C8A4FD0000437B000000000000000000000000000000000000002500000000tokei-13.0.0.alpha.5+git0/src/cli.rsuse std::{process, str::FromStr}; use clap::{crate_description, value_parser, Arg, ArgAction, ArgMatches}; use colored::Colorize; use tokei::{Config, LanguageType, Sort}; use crate::{ cli_utils::{crate_version, parse_or_exit, NumberFormatStyle}, consts::{ BLANKS_COLUMN_WIDTH, CODE_COLUMN_WIDTH, COMMENTS_COLUMN_WIDTH, LANGUAGE_COLUMN_WIDTH, LINES_COLUMN_WIDTH, PATH_COLUMN_WIDTH, }, input::Format, }; /// Used for sorting languages. #[derive(Clone, Copy, Debug, Eq, Ord, PartialEq, PartialOrd)] pub enum Streaming { /// simple lines. Simple, /// Json outputs. Json, } impl std::str::FromStr for Streaming { type Err = String; fn from_str(s: &str) -> Result<Self, Self::Err> { Ok(match s.to_lowercase().as_ref() { "simple" => Streaming::Simple, "json" => Streaming::Json, s => return Err(format!("Unsupported streaming option: {}", s)), }) } } #[derive(Debug)] pub struct Cli { matches: ArgMatches, pub columns: Option<usize>, pub files: bool, pub hidden: bool, pub no_ignore: bool, pub no_ignore_parent: bool, pub no_ignore_dot: bool, pub no_ignore_vcs: bool, pub output: Option<Format>, pub streaming: Option<Streaming>, pub print_languages: bool, pub sort: Option<Sort>, pub sort_reverse: bool, pub types: Option<Vec<LanguageType>>, pub compact: bool, pub number_format: num_format::CustomFormat, } impl Cli { pub fn from_args() -> Self { let matches = clap::Command::new("tokei") .version(crate_version()) .author("Erin P. <xampprocky@gmail.com> + Contributors") .about(concat!( crate_description!(), "\n", "Support this project on GitHub Sponsors: https://github.com/sponsors/XAMPPRocky" )) .arg( Arg::new("columns") .long("columns") .short('c') .value_parser(value_parser!(usize)) .conflicts_with("output") .help( "Sets a strict column width of the output, only available for \ terminal output.", ), ) .arg( Arg::new("exclude") .long("exclude") .short('e') .action(ArgAction::Append) .help("Ignore all files & directories matching the pattern."), ) .arg( Arg::new("files") .long("files") .short('f') .action(ArgAction::SetTrue) .help("Will print out statistics on individual files."), ) .arg( Arg::new("file_input") .long("input") .short('i') .help( "Gives statistics from a previous tokei run. Can be given a file path, \ or \"stdin\" to read from stdin.", ), ) .arg( Arg::new("hidden") .long("hidden") .action(ArgAction::SetTrue) .help("Count hidden files."), ) .arg( Arg::new("input") .num_args(1..) .conflicts_with("languages") .help("The path(s) to the file or directory to be counted.(default current directory)"), ) .arg( Arg::new("languages") .long("languages") .short('l') .action(ArgAction::SetTrue) .conflicts_with("input") .help("Prints out supported languages and their extensions."), ) .arg(Arg::new("no_ignore") .long("no-ignore") .action(ArgAction::SetTrue) .help( "\ Don't respect ignore files (.gitignore, .ignore, etc.). This implies \ --no-ignore-parent, --no-ignore-dot, and --no-ignore-vcs.\ ", )) .arg(Arg::new("no_ignore_parent") .long("no-ignore-parent") .action(ArgAction::SetTrue) .help( "\ Don't respect ignore files (.gitignore, .ignore, etc.) in parent \ directories.\ ", )) .arg(Arg::new("no_ignore_dot") .long("no-ignore-dot") .action(ArgAction::SetTrue) .help( "\ Don't respect .ignore and .tokeignore files, including this in \ parent directories.\ ", )) .arg(Arg::new("no_ignore_vcs") .long("no-ignore-vcs") .action(ArgAction::SetTrue) .help( "\ Don't respect VCS ignore files (.gitignore, .hgignore, etc.) including \ those in parent directories.\ ", )) .arg( Arg::new("output") .long("output") .short('o') .value_parser(|x: &str| { if Format::all().contains(&x) { Ok(x.to_string()) } else { Err(format!("Invalid output format: {x:?}")) } }) .help( "Outputs Tokei in a specific format. Compile with additional features for \ more format support.", ), ) .arg( Arg::new("streaming") .long("streaming") .value_parser(["simple", "json"]) .ignore_case(true) .help( "prints the (language, path, lines, blanks, code, comments) records as \ simple lines or as Json for batch processing", ), ) .arg( Arg::new("sort") .long("sort") .short('s') .value_parser(["files", "lines", "blanks", "code", "comments"]) .ignore_case(true) .conflicts_with("rsort") .help("Sort languages based on column"), ) .arg( Arg::new("rsort") .long("rsort") .short('r') .value_parser(["files", "lines", "blanks", "code", "comments"]) .ignore_case(true) .conflicts_with("sort") .help("Reverse sort languages based on column"), ) .arg( Arg::new("types") .long("types") .short('t') .action(ArgAction::Append) .help( "Filters output by language type, separated by a comma. i.e. \ -t=Rust,Markdown", ), ) .arg( Arg::new("compact") .long("compact") .short('C') .action(ArgAction::SetTrue) .help("Do not print statistics about embedded languages."), ) .arg( Arg::new("num_format_style") .long("num-format") .short('n') .value_parser(["commas", "dots", "plain", "underscores"]) .conflicts_with("output") .help( "Format of printed numbers, i.e., plain (1234, default), \ commas (1,234), dots (1.234), or underscores (1_234). Cannot be \ used with --output.", ), ) .arg( Arg::new("verbose") .long("verbose") .short('v') .action(ArgAction::Count) .help( "Set log output level: 1: to show unknown file extensions, 2: reserved for future debugging, 3: enable file level trace. Not recommended on multiple files", ), ) .get_matches(); let columns = matches.get_one::<usize>("columns").cloned(); let files = matches.get_flag("files"); let hidden = matches.get_flag("hidden"); let no_ignore = matches.get_flag("no_ignore"); let no_ignore_parent = matches.get_flag("no_ignore_parent"); let no_ignore_dot = matches.get_flag("no_ignore_dot"); let no_ignore_vcs = matches.get_flag("no_ignore_vcs"); let print_languages = matches.get_flag("languages"); let verbose = matches.get_count("verbose") as u64; let compact = matches.get_flag("compact"); let types = matches.get_many("types").map(|e| { e.flat_map(|x: &String| { x.split(',') .map(str::parse::<LanguageType>) .filter_map(Result::ok) .collect::<Vec<_>>() }) .collect() }); let num_format_style: NumberFormatStyle = matches .get_one::<NumberFormatStyle>("num_format_style") .cloned() .unwrap_or_default(); let number_format = match num_format_style.get_format() { Ok(format) => format, Err(e) => { eprintln!("Error:\n{}", e); process::exit(1); } }; // Sorting category should be restricted by clap but parse before we do // work just in case. let (sort, sort_reverse) = if let Some(sort) = matches.get_one::<String>("sort") { (Some(sort.clone()), false) } else { let sort = matches.get_one::<String>("rsort"); (sort.cloned(), sort.is_some()) }; let sort = sort.map(|x| match Sort::from_str(&x) { Ok(sort) => sort, Err(e) => { eprintln!("Error:\n{}", e); process::exit(1); } }); // Format category is overly accepting by clap (so the user knows what // is supported) but this will fail if support is not compiled in and // give a useful error to the user. let output = matches.get_one("output").cloned(); let streaming = matches .get_one("streaming") .cloned() .map(parse_or_exit::<Streaming>); crate::cli_utils::setup_logger(verbose); let cli = Cli { matches, columns, files, hidden, no_ignore, no_ignore_parent, no_ignore_dot, no_ignore_vcs, output, streaming, print_languages, sort, sort_reverse, types, compact, number_format, }; debug!("CLI Config: {:#?}", cli); cli } pub fn file_input(&self) -> Option<&str> { self.matches.get_one("file_input").cloned() } pub fn ignored_directories(&self) -> Vec<&str> { let mut ignored_directories: Vec<&str> = Vec::new(); if let Some(user_ignored) = self.matches.get_many::<String>("exclude") { ignored_directories.extend(user_ignored.map(|x| x.as_str())); } ignored_directories } pub fn input(&self) -> Vec<&str> { match self.matches.get_many::<String>("input") { Some(vs) => vs.map(|x| x.as_str()).collect(), None => vec!["."], } } pub fn print_supported_languages() -> Result<(), Box<dyn std::error::Error>> { use table_formatter::table::*; use table_formatter::{cell, table}; let term_width = term_size::dimensions().map(|(w, _)| w).unwrap_or(75) - 8; let (lang_w, suffix_w) = if term_width <= 80 { (term_width / 2, term_width / 2) } else { (40, term_width - 40) }; let header = vec![ cell!( "Language", align = Align::Left, padding = Padding::NONE, width = Some(lang_w) ) .with_formatter(vec![table_formatter::table::FormatterFunc::Normal( Colorize::bold, )]), cell!( "Extensions", align = Align::Left, padding = Padding::new(3, 0), width = Some(suffix_w) ) .with_formatter(vec![table_formatter::table::FormatterFunc::Normal( Colorize::bold, )]), ]; let content = LanguageType::list() .iter() .map(|(key, ext)| { vec![ // table::TableCell::new(table::Cell::TextCell(key.name().to_string())) // .with_width(lang_w), cell!(key.name()).with_width(Some(lang_w)), cell!( if matches!(key, LanguageType::Emojicode) { ext.join(", ") + "\u{200b}" } else if ext.is_empty() { "<None>".to_string() } else { ext.join(", ") }, align = Align::Left, padding = Padding::new(3, 0), width = Some(suffix_w) ), ] }) .collect(); let t = table!(header - content with Border::ALL); let mut render_result = Vec::new(); t.render(&mut render_result)?; println!("{}", String::from_utf8(render_result)?); Ok(()) } /// Overrides the shared options (See `tokei::Config` for option /// descriptions) between the CLI and the config files. CLI flags have /// higher precedence than options present in config files. /// /// #### Shared options /// * `hidden` /// * `no_ignore` /// * `no_ignore_parent` /// * `no_ignore_dot` /// * `no_ignore_vcs` /// * `types` pub fn override_config(&mut self, mut config: Config) -> Config { config.hidden = if self.hidden { Some(true) } else { config.hidden }; config.no_ignore = if self.no_ignore { Some(true) } else { config.no_ignore }; config.no_ignore_parent = if self.no_ignore_parent { Some(true) } else { config.no_ignore_parent }; config.no_ignore_dot = if self.no_ignore_dot { Some(true) } else { config.no_ignore_dot }; config.no_ignore_vcs = if self.no_ignore_vcs { Some(true) } else { config.no_ignore_vcs }; config.for_each_fn = match self.streaming { Some(Streaming::Json) => Some(|l: LanguageType, e| { println!("{}", serde_json::json!({"language": l.name(), "stats": e})); }), Some(Streaming::Simple) => Some(|l: LanguageType, e| { println!( "{:>LANGUAGE_COLUMN_WIDTH$} {:<PATH_COLUMN_WIDTH$} {:>LINES_COLUMN_WIDTH$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", l.name(), e.name.to_string_lossy().to_string(), e.stats.lines(), e.stats.code, e.stats.comments, e.stats.blanks ); }), _ => None, }; config.types = self.types.take().or(config.types); config } pub fn print_input_parse_failure(input_filename: &str) { eprintln!("Error:\n Failed to parse input file: {}", input_filename); let not_supported = Format::not_supported(); if !not_supported.is_empty() { eprintln!( " This version of tokei was compiled without serialization support for the following formats: {not_supported} You may want to install any comma separated combination of {all:?}: cargo install tokei --features {all:?} Or use the 'all' feature: cargo install tokei --features all \n", not_supported = not_supported.join(", "), // no space after comma to ease copypaste all = self::Format::all_feature_names().join(",") ); } } } 07070100000028000081A400000000000000000000000166C8A4FD00003E7A000000000000000000000000000000000000002B00000000tokei-13.0.0.alpha.5+git0/src/cli_utils.rsuse std::{ borrow::Cow, fmt, io::{self, Write}, process, str::FromStr, }; use clap::crate_version; use colored::Colorize; use num_format::ToFormattedString; use crate::input::Format; use tokei::{find_char_boundary, CodeStats, Language, LanguageType, Report}; use crate::consts::{ BLANKS_COLUMN_WIDTH, CODE_COLUMN_WIDTH, COMMENTS_COLUMN_WIDTH, FILES_COLUMN_WIDTH, LINES_COLUMN_WIDTH, }; const NO_LANG_HEADER_ROW_LEN: usize = 69; const NO_LANG_ROW_LEN: usize = 63; const NO_LANG_ROW_LEN_NO_SPACES: usize = 56; const IDENT_INACCURATE: &str = "(!)"; pub fn crate_version() -> String { if Format::supported().is_empty() { format!( "{} compiled without serialization formats.", crate_version!() ) } else { format!( "{} compiled with serialization support: {}", crate_version!(), Format::supported().join(", ") ) } } pub fn setup_logger(verbose_option: u64) { use log::LevelFilter; let mut builder = env_logger::Builder::new(); let filter_level = match verbose_option { 1 => LevelFilter::Warn, 2 => LevelFilter::Debug, 3 => LevelFilter::Trace, _ => LevelFilter::Error, }; builder.filter(None, filter_level); builder.init(); } pub fn parse_or_exit<T>(s: &str) -> T where T: FromStr, T::Err: fmt::Display, { T::from_str(s).unwrap_or_else(|e| { eprintln!("Error:\n{}", e); process::exit(1); }) } #[non_exhaustive] #[derive(Debug, Copy, Clone)] pub enum NumberFormatStyle { // 1234 (Default) Plain, // 1,234 Commas, // 1.234 Dots, // 1_234 Underscores, } impl Default for NumberFormatStyle { fn default() -> Self { Self::Plain } } impl FromStr for NumberFormatStyle { type Err = String; fn from_str(s: &str) -> Result<Self, Self::Err> { match s { "plain" => Ok(Self::Plain), "commas" => Ok(Self::Commas), "dots" => Ok(Self::Dots), "underscores" => Ok(Self::Underscores), _ => Err(format!( "Expected 'plain', 'commas', 'underscores', or 'dots' for num-format, but got '{}'", s, )), } } } impl NumberFormatStyle { fn separator(self) -> &'static str { match self { Self::Plain => "", Self::Commas => ",", Self::Dots => ".", Self::Underscores => "_", } } pub fn get_format(self) -> Result<num_format::CustomFormat, num_format::Error> { num_format::CustomFormat::builder() .grouping(num_format::Grouping::Standard) .separator(self.separator()) .build() } } pub struct Printer<W> { writer: W, columns: usize, path_length: usize, row: String, subrow: String, list_files: bool, number_format: num_format::CustomFormat, } impl<W> Printer<W> { pub fn new( columns: usize, list_files: bool, writer: W, number_format: num_format::CustomFormat, ) -> Self { Self { columns, list_files, path_length: columns - NO_LANG_ROW_LEN_NO_SPACES, writer, row: "━".repeat(columns), subrow: "─".repeat(columns), number_format, } } } impl<W: Write> Printer<W> { pub fn print_header(&mut self) -> io::Result<()> { self.print_row()?; let files_column_width: usize = FILES_COLUMN_WIDTH + 6; writeln!( self.writer, " {:<6$} {:>files_column_width$} {:>LINES_COLUMN_WIDTH$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", "Language".bold().blue(), "Files".bold().blue(), "Lines".bold().blue(), "Code".bold().blue(), "Comments".bold().blue(), "Blanks".bold().blue(), self.columns - NO_LANG_HEADER_ROW_LEN )?; self.print_row() } pub fn print_inaccuracy_warning(&mut self) -> io::Result<()> { writeln!( self.writer, "Note: results can be inaccurate for languages marked with '{}'", IDENT_INACCURATE ) } pub fn print_language(&mut self, language: &Language, name: &str) -> io::Result<()> where W: Write, { self.print_language_name(language.inaccurate, name, None)?; write!(self.writer, " ")?; writeln!( self.writer, "{:>FILES_COLUMN_WIDTH$} {:>LINES_COLUMN_WIDTH$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", language .reports .len() .to_formatted_string(&self.number_format), language.lines().to_formatted_string(&self.number_format), language.code.to_formatted_string(&self.number_format), language.comments.to_formatted_string(&self.number_format), language.blanks.to_formatted_string(&self.number_format), ) } fn print_language_in_print_total(&mut self, language: &Language) -> io::Result<()> where W: Write, { self.print_language_name(language.inaccurate, "Total", None)?; write!(self.writer, " ")?; writeln!( self.writer, "{:>FILES_COLUMN_WIDTH$} {:>LINES_COLUMN_WIDTH$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", language .children .values() .map(Vec::len) .sum::<usize>() .to_formatted_string(&self.number_format) .blue(), language .lines() .to_formatted_string(&self.number_format) .blue(), language .code .to_formatted_string(&self.number_format) .blue(), language .comments .to_formatted_string(&self.number_format) .blue(), language .blanks .to_formatted_string(&self.number_format) .blue(), ) } pub fn print_language_name( &mut self, inaccurate: bool, name: &str, prefix: Option<&str>, ) -> io::Result<()> { let mut lang_section_len = self.columns - NO_LANG_ROW_LEN - prefix.map_or(0, str::len); if inaccurate { lang_section_len -= IDENT_INACCURATE.len(); } if let Some(prefix) = prefix { write!(self.writer, "{}", prefix)?; } // truncate and replace the last char with a `|` if the name is too long if lang_section_len < name.len() { write!(self.writer, " {:.len$}", name, len = lang_section_len - 1)?; write!(self.writer, "|")?; } else { write!( self.writer, " {:<len$}", name.bold().magenta(), len = lang_section_len )?; } if inaccurate { write!(self.writer, "{}", IDENT_INACCURATE)?; }; Ok(()) } fn print_code_stats( &mut self, language_type: LanguageType, stats: &[CodeStats], ) -> io::Result<()> { self.print_language_name(false, &language_type.to_string(), Some(" |-"))?; let mut code = 0; let mut comments = 0; let mut blanks = 0; for stats in stats.iter().map(tokei::CodeStats::summarise) { code += stats.code; comments += stats.comments; blanks += stats.blanks; } if stats.is_empty() { Ok(()) } else { writeln!( self.writer, " {:>FILES_COLUMN_WIDTH$} {:>LINES_COLUMN_WIDTH$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", stats.len().to_formatted_string(&self.number_format), (code + comments + blanks).to_formatted_string(&self.number_format), code.to_formatted_string(&self.number_format), comments.to_formatted_string(&self.number_format), blanks.to_formatted_string(&self.number_format), ) } } fn print_language_total(&mut self, parent: &Language) -> io::Result<()> { for (language, reports) in &parent.children { self.print_code_stats( *language, &reports .iter() .map(|r| r.stats.summarise()) .collect::<Vec<_>>(), )?; } let mut subtotal = tokei::Report::new("(Total)".into()); let summary = parent.summarise(); subtotal.stats.code += summary.code; subtotal.stats.comments += summary.comments; subtotal.stats.blanks += summary.blanks; self.print_report_with_name(&subtotal)?; Ok(()) } pub fn print_results<'a, I>( &mut self, languages: I, compact: bool, is_sorted: bool, ) -> io::Result<()> where I: Iterator<Item = (&'a LanguageType, &'a Language)>, { let (a, b): (Vec<_>, Vec<_>) = languages .filter(|(_, v)| !v.is_empty()) .partition(|(_, l)| compact || l.children.is_empty()); let mut first = true; for languages in &[&a, &b] { for &(name, language) in *languages { let has_children = !(compact || language.children.is_empty()); if first { first = false; } else if has_children || self.list_files { self.print_subrow()?; } self.print_language(language, name.name())?; if has_children { self.print_language_total(language)?; } if self.list_files { self.print_subrow()?; let mut reports: Vec<&Report> = language.reports.iter().collect(); if !is_sorted { reports.sort_by(|&a, &b| a.name.cmp(&b.name)); } if compact { for &report in &reports { writeln!(self.writer, "{:1$}", report, self.path_length)?; } } else { let (a, b): (Vec<&Report>, Vec<&Report>) = reports.iter().partition(|&r| r.stats.blobs.is_empty()); for reports in &[&a, &b] { let mut first = true; for report in reports.iter() { if report.stats.blobs.is_empty() { writeln!(self.writer, "{:1$}", report, self.path_length)?; } else { if first && a.is_empty() { writeln!(self.writer, " {}", report.name.display())?; first = false; } else { writeln!( self.writer, "-- {} {}", report.name.display(), "-".repeat( self.columns - 4 - report.name.display().to_string().len() ) )?; } let mut new_report = (*report).clone(); new_report.name = name.to_string().into(); writeln!( self.writer, " |-{:1$}", new_report, self.path_length - 3 )?; self.print_report_total(report, language.inaccurate)?; } } } } } } } Ok(()) } fn print_row(&mut self) -> io::Result<()> { writeln!(self.writer, "{}", self.row) } fn print_subrow(&mut self) -> io::Result<()> { writeln!(self.writer, "{}", self.subrow.dimmed()) } fn print_report( &mut self, language_type: LanguageType, stats: &CodeStats, inaccurate: bool, ) -> io::Result<()> { self.print_language_name(inaccurate, &language_type.to_string(), Some(" |-"))?; writeln!( self.writer, " {:>FILES_COLUMN_WIDTH$} {:>LINES_COLUMN_WIDTH$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", " ", stats.lines().to_formatted_string(&self.number_format), stats.code.to_formatted_string(&self.number_format), stats.comments.to_formatted_string(&self.number_format), stats.blanks.to_formatted_string(&self.number_format), ) } fn print_report_total(&mut self, report: &Report, inaccurate: bool) -> io::Result<()> { if report.stats.blobs.is_empty() { return Ok(()); } let mut subtotal = tokei::Report::new("|- (Total)".into()); subtotal.stats.code += report.stats.code; subtotal.stats.comments += report.stats.comments; subtotal.stats.blanks += report.stats.blanks; for (language_type, stats) in &report.stats.blobs { self.print_report(*language_type, stats, inaccurate)?; subtotal.stats += stats.summarise(); } self.print_report_with_name(report)?; Ok(()) } fn print_report_with_name(&mut self, report: &Report) -> io::Result<()> { let name = report.name.to_string_lossy(); let name_length = name.len(); if name_length > self.path_length { let mut formatted = String::from("|"); // Add 1 to the index to account for the '|' we add to the output string let from = find_char_boundary(&name, name_length + 1 - self.path_length); formatted.push_str(&name[from..]); } self.print_report_total_formatted(name, self.path_length, report)?; Ok(()) } fn print_report_total_formatted( &mut self, name: Cow<'_, str>, max_len: usize, report: &Report, ) -> io::Result<()> { let lines_column_width: usize = FILES_COLUMN_WIDTH + 6; writeln!( self.writer, " {: <max$} {:>lines_column_width$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", name, report .stats .lines() .to_formatted_string(&self.number_format), report.stats.code.to_formatted_string(&self.number_format), report .stats .comments .to_formatted_string(&self.number_format), report.stats.blanks.to_formatted_string(&self.number_format), max = max_len ) } pub fn print_total(&mut self, languages: &tokei::Languages) -> io::Result<()> { let total = languages.total(); self.print_row()?; self.print_language_in_print_total(&total)?; self.print_row() } } 07070100000029000081A400000000000000000000000166C8A4FD00001C51000000000000000000000000000000000000002800000000tokei-13.0.0.alpha.5+git0/src/config.rsuse std::{env, fs, path::PathBuf}; use etcetera::BaseStrategy; use crate::language::LanguageType; use crate::sort::Sort; use crate::stats::Report; /// A configuration struct for how [`Languages::get_statistics`] searches and /// counts languages. /// /// ``` /// use tokei::Config; /// /// let config = Config { /// treat_doc_strings_as_comments: Some(true), /// ..Config::default() /// }; /// ``` /// /// [`Languages::get_statistics`]: struct.Languages.html#method.get_statistics #[derive(Debug, Default, Deserialize)] pub struct Config { /// Width of columns to be printed to the terminal. _This option is ignored /// in the library._ *Default:* Auto detected width of the terminal. pub columns: Option<usize>, /// Count hidden files and directories. *Default:* `false`. pub hidden: Option<bool>, /// Don't respect ignore files (.gitignore, .ignore, etc.). This implies --no-ignore-parent, /// --no-ignore-dot, and --no-ignore-vcs. *Default:* `false`. pub no_ignore: Option<bool>, /// Don't respect ignore files (.gitignore, .ignore, etc.) in parent directories. /// *Default:* `false`. pub no_ignore_parent: Option<bool>, /// Don't respect .ignore and .tokeignore files, including those in parent directories. /// *Default:* `false`. pub no_ignore_dot: Option<bool>, /// Don't respect VCS ignore files (.gitignore, .hgignore, etc.), including those in /// parent directories. *Default:* `false`. pub no_ignore_vcs: Option<bool>, /// Whether to treat doc strings in languages as comments. *Default:* /// `false`. pub treat_doc_strings_as_comments: Option<bool>, /// Sort languages. *Default:* `None`. pub sort: Option<Sort>, /// Filters languages searched to just those provided. E.g. A directory /// containing `C`, `Cpp`, and `Rust` with a `Config.types` of `[Cpp, Rust]` /// will count only `Cpp` and `Rust`. *Default:* `None`. pub types: Option<Vec<LanguageType>>, // /// A map of individual language configuration. // pub languages: Option<HashMap<LanguageType, LanguageConfig>>, /// Whether to output only the paths for downstream batch processing /// *Default:* false #[serde(skip)] /// adds a closure for each function, e.g., print the result pub for_each_fn: Option<fn(LanguageType, Report)>, } impl Config { /// Constructs a new `Config` from either `$base/tokei.toml` or /// `$base/.tokeirc`. `tokei.toml` takes precedence over `.tokeirc` /// as the latter is a hidden file on Unix and not an idiomatic /// filename on Windows. fn get_config(base: PathBuf) -> Option<Self> { fs::read_to_string(base.join("tokei.toml")) .ok() .or_else(|| fs::read_to_string(base.join(".tokeirc")).ok()) .and_then(|s| toml::from_str(&s).ok()) } /// Creates a `Config` from three configuration files if they are available. /// Files can have two different names `tokei.toml` and `.tokeirc`. /// Firstly it will attempt to find a config in the configuration directory /// (see below), secondly from the home directory, `$HOME/`, /// and thirdly from the current directory, `./`. /// The current directory's configuration will take priority over the configuration /// directory. /// /// |Platform | Value | Example | /// | ------- | ------------------------------------- | ------------------------------ | /// | Linux | `$XDG_CONFIG_HOME` or `$HOME`/.config | /home/alice/.config | /// | macOS | `$XDG_CONFIG_HOME` or `$HOME`/.config | /Users/alice/.config | /// | Windows | `{FOLDERID_RoamingAppData}` | C:\Users\Alice\AppData\Roaming | /// /// # Example /// ```toml /// columns = 80 /// types = ["Python"] /// treat_doc_strings_as_comments = true // /// // /// [[languages.Python]] // /// extensions = ["py3"] /// ``` pub fn from_config_files() -> Self { let conf_dir = etcetera::choose_base_strategy() .ok() .map(|basedirs| basedirs.config_dir()) .and_then(Self::get_config) .unwrap_or_default(); let home_dir = etcetera::home_dir() .ok() .and_then(Self::get_config) .unwrap_or_default(); let current_dir = env::current_dir() .ok() .and_then(Self::get_config) .unwrap_or_default(); #[allow(clippy::or_fun_call)] Config { columns: current_dir .columns .or(home_dir.columns.or(conf_dir.columns)), hidden: current_dir.hidden.or(home_dir.hidden.or(conf_dir.hidden)), //languages: current_dir.languages.or(conf_dir.languages), treat_doc_strings_as_comments: current_dir.treat_doc_strings_as_comments.or(home_dir .treat_doc_strings_as_comments .or(conf_dir.treat_doc_strings_as_comments)), sort: current_dir.sort.or(home_dir.sort.or(conf_dir.sort)), types: current_dir.types.or(home_dir.types.or(conf_dir.types)), for_each_fn: current_dir .for_each_fn .or(home_dir.for_each_fn.or(conf_dir.for_each_fn)), no_ignore: current_dir .no_ignore .or(home_dir.no_ignore.or(conf_dir.no_ignore)), no_ignore_parent: current_dir .no_ignore_parent .or(home_dir.no_ignore_parent.or(conf_dir.no_ignore_parent)), no_ignore_dot: current_dir .no_ignore_dot .or(home_dir.no_ignore_dot.or(conf_dir.no_ignore_dot)), no_ignore_vcs: current_dir .no_ignore_vcs .or(home_dir.no_ignore_vcs.or(conf_dir.no_ignore_vcs)), } } } /* /// Configuration for a individual [`LanguageType`]. /// /// ``` /// use std::collections::HashMap; /// use tokei::{Config, LanguageConfig, LanguageType}; /// /// let config = Config { /// languages: { /// let cpp_conf = LanguageConfig { /// extensions: vec![String::from("c")], /// }; /// /// let mut languages_config = HashMap::new(); /// languages_config.insert(LanguageType::Cpp, cpp_conf); /// /// Some(languages_config) /// }, /// /// ..Config::default() /// }; /// /// ``` /// /// [`LanguageType`]: enum.LanguageType.html #[derive(Debug, Default, Deserialize)] pub struct LanguageConfig { /// Additional extensions for a language. Any extensions that overlap with /// already defined extensions from `tokei` will be ignored. pub extensions: Vec<String>, } impl LanguageConfig { /// Creates a new empty configuration. By default this will not change /// anything from the default. pub fn new() -> Self { Self::default() } /// Accepts a `Vec<String>` representing additional extensions for a /// language. Any extensions that overlap with already defined extensions /// from `tokei` will be ignored. pub fn extensions(&mut self, extensions: Vec<String>) { self.extensions = extensions; } } */ 0707010000002A000081A400000000000000000000000166C8A4FD00000262000000000000000000000000000000000000002800000000tokei-13.0.0.alpha.5+git0/src/consts.rs// Set of common pub consts. /// Fallback row length pub const FALLBACK_ROW_LEN: usize = 81; // Column widths used for console printing. /// Language column width pub const LANGUAGE_COLUMN_WIDTH: usize = 10; /// Path column width pub const PATH_COLUMN_WIDTH: usize = 80; /// Files column width pub const FILES_COLUMN_WIDTH: usize = 8; /// Lines column width pub const LINES_COLUMN_WIDTH: usize = 12; /// Code column width pub const CODE_COLUMN_WIDTH: usize = 12; /// Comments column width pub const COMMENTS_COLUMN_WIDTH: usize = 12; /// Blanks column width pub const BLANKS_COLUMN_WIDTH: usize = 12; 0707010000002B000081A400000000000000000000000166C8A4FD00001BDE000000000000000000000000000000000000002700000000tokei-13.0.0.alpha.5+git0/src/input.rsuse serde::{Deserialize, Serialize}; use std::{collections::BTreeMap, error::Error, str::FromStr}; use tokei::{Language, LanguageType, Languages}; type LanguageMap = BTreeMap<LanguageType, Language>; #[derive(Deserialize, Serialize, Debug)] struct Output { #[serde(flatten)] languages: LanguageMap, #[serde(rename = "Total")] totals: Language, } macro_rules! supported_formats { ($( ($name:ident, $feature:expr, $variant:ident [$($krate:ident),+]) => $parse_kode:expr, $print_kode:expr, )+) => ( $( // for each format $( // for each required krate #[cfg(feature = $feature)] extern crate $krate; )+ )+ /// Supported serialization formats. /// /// To enable all formats compile with the `all` feature. #[cfg_attr(test, derive(strum_macros::EnumIter))] #[derive(Debug, Clone)] pub enum Format { Json, $( #[cfg(feature = $feature)] $variant ),+ // TODO: Allow adding format at runtime when used as a lib? } impl Format { pub fn supported() -> &'static [&'static str] { &[ "json", $( #[cfg(feature = $feature)] stringify!($name) ),+ ] } pub fn all() -> &'static [&'static str] { &[ $( stringify!($name) ),+ ] } pub fn all_feature_names() -> &'static [&'static str] { &[ $( $feature ),+ ] } pub fn not_supported() -> &'static [&'static str] { &[ $( #[cfg(not(feature = $feature))] stringify!($name) ),+ ] } pub fn parse(input: &str) -> Option<LanguageMap> { if input.is_empty() { return None } if let Ok(Output { languages, .. }) = serde_json::from_str::<Output>(input) { return Some(languages); } $( // attributes are not yet allowed on `if` expressions #[cfg(feature = $feature)] { let parse = &{ $parse_kode }; if let Ok(Output { languages, .. }) = parse(input) { return Some(languages) } } )+ // Didn't match any of the compiled serialization formats None } pub fn print(&self, languages: &Languages) -> Result<String, Box<dyn Error>> { let output = Output { languages: (*languages).to_owned(), totals: languages.total() }; match *self { Format::Json => Ok(serde_json::to_string(&output)?), $( #[cfg(feature = $feature)] Format::$variant => { let print= &{ $print_kode }; Ok(print(&output)?) } ),+ } } } impl FromStr for Format { type Err = String; fn from_str(format: &str) -> Result<Self, Self::Err> { match format { "json" => Ok(Format::Json), $( stringify!($name) => { #[cfg(feature = $feature)] return Ok(Format::$variant); #[cfg(not(feature = $feature))] return Err(format!( "This version of tokei was compiled without \ any '{format}' serialization support, to enable serialization, \ reinstall tokei with the features flag. cargo install tokei --features {feature} If you want to enable all supported serialization formats, you can use the 'all' feature. cargo install tokei --features all\n", format = stringify!($name), feature = $feature) ); } ),+ format => Err(format!("{:?} is not a supported serialization format", format)), } } } ) } // The ordering of these determines the attempted order when parsing. supported_formats!( (cbor, "cbor", Cbor [serde_cbor, hex]) => |input| { hex::FromHex::from_hex(input) .map_err(|e: hex::FromHexError| <Box<dyn Error>>::from(e)) .and_then(|hex: Vec<_>| Ok(serde_cbor::from_slice(&hex)?)) }, |languages| serde_cbor::to_vec(&languages).map(hex::encode), (json, "json", Json [serde_json]) => serde_json::from_str, serde_json::to_string, (yaml, "yaml", Yaml [serde_yaml]) => serde_yaml::from_str, serde_yaml::to_string, ); pub fn add_input(input: &str, languages: &mut Languages) -> bool { use std::fs::File; use std::io::Read; let map = match File::open(input) { Ok(mut file) => { let contents = { let mut contents = String::new(); file.read_to_string(&mut contents) .expect("Couldn't read file"); contents }; convert_input(&contents) } Err(_) => { if input == "stdin" { let mut stdin = ::std::io::stdin(); let mut buffer = String::new(); let _ = stdin.read_to_string(&mut buffer); convert_input(&buffer) } else { convert_input(input) } } }; if let Some(map) = map { *languages += map; true } else { false } } fn convert_input(contents: &str) -> Option<LanguageMap> { self::Format::parse(contents) } #[cfg(test)] mod tests { use super::*; use strum::IntoEnumIterator; use tokei::Config; use std::path::Path; #[test] fn formatting_print_matches_parse() { // Get language results from sample dir let data_dir = Path::new("tests").join("data"); let mut langs = Languages::new(); langs.get_statistics(&[data_dir], &[], &Config::default()); // Check that the value matches after serializing and deserializing for variant in Format::iter() { let serialized = variant .print(&langs) .unwrap_or_else(|_| panic!("Failed serializing variant: {:?}", variant)); let deserialized = Format::parse(&serialized) .unwrap_or_else(|| panic!("Failed deserializing variant: {:?}", variant)); assert_eq!(*langs, deserialized); } } } 0707010000002C000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000002700000000tokei-13.0.0.alpha.5+git0/src/language0707010000002D000081A400000000000000000000000166C8A4FD00001A4D000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/src/language/embedding.rs#![allow(clippy::trivial_regex)] use crate::LanguageType; use once_cell::sync::Lazy; use regex::bytes::Regex; pub static START_SCRIPT: Lazy<Regex> = Lazy::new(|| Regex::new(r#"<script(?:.*type="(.*)")?.*?>"#).unwrap()); pub static END_SCRIPT: Lazy<Regex> = Lazy::new(|| Regex::new(r#"</script>"#).unwrap()); pub static START_STYLE: Lazy<Regex> = Lazy::new(|| Regex::new(r#"<style(?:.*lang="(.*)")?.*?>"#).unwrap()); pub static END_STYLE: Lazy<Regex> = Lazy::new(|| Regex::new(r#"</style>"#).unwrap()); pub static START_TEMPLATE: Lazy<Regex> = Lazy::new(|| Regex::new(r#"<template(?:.*lang="(.*)")?.*?>"#).unwrap()); pub static END_TEMPLATE: Lazy<Regex> = Lazy::new(|| Regex::new(r#"</template>"#).unwrap()); pub static STARTING_MARKDOWN_REGEX: Lazy<Regex> = Lazy::new(|| Regex::new(r#"```\S+\s"#).unwrap()); pub static ENDING_MARKDOWN_REGEX: Lazy<Regex> = Lazy::new(|| Regex::new(r#"```\s?"#).unwrap()); pub static STARTING_LF_BLOCK_REGEX: Lazy<Regex> = Lazy::new(|| Regex::new(r#"\{="#).unwrap()); pub static ENDING_LF_BLOCK_REGEX: Lazy<Regex> = Lazy::new(|| Regex::new(r#"=}"#).unwrap()); /// A memory of a regex matched. /// The values provided by `Self::start` and `Self::end` are in the same space as the /// start value supplied to `RegexCache::build` pub struct Capture<'a> { start: usize, text: &'a [u8], } impl Capture<'_> { #[inline(always)] fn start(&self) -> usize { self.start } #[inline(always)] pub fn end(&self) -> usize { self.start + self.text.len() } #[inline(always)] pub fn as_bytes(&self) -> &[u8] { self.text } } impl<'a> std::fmt::Debug for Capture<'a> { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { f.debug_struct("Capture") .field("start", &self.start) .field("end", &self.end()) .field("text", &String::from_utf8_lossy(self.text)) .finish() } } pub(crate) struct RegexCache<'a> { inner: Option<RegexFamily<'a>>, } /// Embedding regexes are similar between different sets of languages. /// `RegexFamily` records both which family the language belongs to, /// as well as the actual matches pub(crate) enum RegexFamily<'a> { HtmlLike(HtmlLike<'a>), LinguaFranca(SimpleCapture<'a>), Markdown(SimpleCapture<'a>), Rust, } pub(crate) struct HtmlLike<'a> { start_script: Option<Box<[Capture<'a>]>>, start_style: Option<Box<[Capture<'a>]>>, start_template: Option<Box<[Capture<'a>]>>, } pub(crate) struct SimpleCapture<'a> { starts: Option<Box<[Capture<'a>]>>, } impl<'a> HtmlLike<'a> { pub fn start_script_in_range( &'a self, start: usize, end: usize, ) -> Option<impl Iterator<Item = &'a Capture<'a>>> { filter_range(self.start_script.as_ref()?, start, end) } pub fn start_style_in_range( &'a self, start: usize, end: usize, ) -> Option<impl Iterator<Item = &'a Capture<'a>>> { filter_range(self.start_style.as_ref()?, start, end) } pub fn start_template_in_range( &'a self, start: usize, end: usize, ) -> Option<impl Iterator<Item = &'a Capture<'a>>> { filter_range(self.start_template.as_ref()?, start, end) } } impl<'a> SimpleCapture<'a> { pub fn starts_in_range(&'a self, start: usize, end: usize) -> Option<&Capture<'a>> { filter_range(self.starts.as_ref()?, start, end).and_then(|mut it| it.next()) } fn make_capture( regex: &Regex, lines: &'a [u8], start: usize, end: usize, ) -> Option<SimpleCapture<'a>> { let capture = SimpleCapture { starts: save_captures(regex, lines, start, end), }; if capture.starts.is_some() { Some(capture) } else { None } } } fn filter_range<'a>( dataset: &'a [Capture<'a>], start: usize, end: usize, ) -> Option<impl Iterator<Item = &'a Capture<'a>>> { let pos = dataset .binary_search_by_key(&start, |cap| cap.start()) .ok()?; if pos >= dataset.len() || dataset[pos].end() > end { None } else { Some( dataset[pos..] .iter() .take_while(move |cap| cap.end() <= end), ) } } impl<'a> RegexCache<'a> { /// Returns the language family for which regexes were matched, if any pub(crate) fn family(&self) -> Option<&RegexFamily> { self.inner.as_ref() } /// Tries to memoize any matches of embedding regexes that occur within lines[start..end] /// for the given language. Any `Capture` values eventually recovered will use the same /// zero for their start as the given `start` argument. pub(crate) fn build(lang: LanguageType, lines: &'a [u8], start: usize, end: usize) -> Self { let inner = match lang { LanguageType::Markdown | LanguageType::UnrealDeveloperMarkdown => { SimpleCapture::make_capture(&STARTING_MARKDOWN_REGEX, lines, start, end) .map(RegexFamily::Markdown) } LanguageType::Rust => Some(RegexFamily::Rust), LanguageType::LinguaFranca => { SimpleCapture::make_capture(&STARTING_LF_BLOCK_REGEX, lines, start, end) .map(RegexFamily::LinguaFranca) } LanguageType::Html | LanguageType::RubyHtml | LanguageType::Svelte | LanguageType::Vue | LanguageType::GlimmerJs | LanguageType::GlimmerTs => { let html = HtmlLike { start_script: save_captures(&START_SCRIPT, lines, start, end), start_style: save_captures(&START_STYLE, lines, start, end), start_template: save_captures(&START_TEMPLATE, lines, start, end), }; if html.start_script.is_some() || html.start_style.is_some() || html.start_template.is_some() { Some(RegexFamily::HtmlLike(html)) } else { None } } _ => None, }; Self { inner } } } fn save_captures<'a>( regex: &Regex, lines: &'a [u8], start: usize, end: usize, ) -> Option<Box<[Capture<'a>]>> { let v: Vec<_> = regex .captures(&lines[start..end])? .iter() .flatten() .map(|cap| Capture { start: start + cap.start(), text: cap.as_bytes(), }) .collect(); if v.is_empty() { None } else { Some(v.into()) } } 0707010000002E000081A400000000000000000000000166C8A4FD00003168000000000000000000000000000000000000003800000000tokei-13.0.0.alpha.5+git0/src/language/language_type.rsuse std::{ borrow::Cow, fmt, fs::File, io::{self, Read}, path::{Path, PathBuf}, str::FromStr, }; use crate::{ config::Config, language::syntax::{FileContext, LanguageContext, SyntaxCounter}, stats::{CodeStats, Report}, utils::{ext::SliceExt, fs as fsutils}, }; use encoding_rs_io::DecodeReaderBytesBuilder; use grep_searcher::{LineIter, LineStep}; use once_cell::sync::Lazy; use rayon::prelude::*; use serde::Serialize; use self::LanguageType::*; include!(concat!(env!("OUT_DIR"), "/language_type.rs")); impl Serialize for LanguageType { fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error> where S: serde::Serializer, { serializer.serialize_str(self.name()) } } impl LanguageType { /// Parses a given [`Path`] using the [`LanguageType`]. Returning [`Report`] /// on success and giving back ownership of [`PathBuf`] on error. pub fn parse(self, path: PathBuf, config: &Config) -> Result<Report, (io::Error, PathBuf)> { let text = { let f = match File::open(&path) { Ok(f) => f, Err(e) => return Err((e, path)), }; let mut s = Vec::new(); let mut reader = DecodeReaderBytesBuilder::new().build(f); if let Err(e) = reader.read_to_end(&mut s) { return Err((e, path)); } s }; let mut stats = Report::new(path); stats += self.parse_from_slice(text, config); Ok(stats) } /// Parses the text provided as the given [`LanguageType`]. pub fn parse_from_str<A: AsRef<str>>(self, text: A, config: &Config) -> CodeStats { self.parse_from_slice(text.as_ref().as_bytes(), config) } /// Parses the bytes provided as the given [`LanguageType`]. pub fn parse_from_slice<A: AsRef<[u8]>>(self, text: A, config: &Config) -> CodeStats { let text = text.as_ref(); if self == Jupyter { return self .parse_jupyter(text.as_ref(), config) .unwrap_or_default(); } let syntax = { let mut syntax_mut = SyntaxCounter::new(self); if self == LinguaFranca { syntax_mut.lf_embedded_language = self.find_lf_target_language(text); } syntax_mut }; if let Some(end) = syntax.shared.important_syntax.find(text).and_then(|m| { // Get the position of the last line before the important // syntax. text[..=m.start()] .iter() .rev() .position(|&c| c == b'\n') .filter(|&p| p != 0) .map(|p| m.start() - p) }) { let (skippable_text, rest) = text.split_at(end + 1); let is_fortran = syntax.shared.is_fortran; let is_literate = syntax.shared.is_literate; let comments = syntax.shared.line_comments; trace!( "Using Simple Parse on {:?}", String::from_utf8_lossy(skippable_text) ); let parse_lines = move || self.parse_lines(config, rest, CodeStats::new(), syntax); let simple_parse = move || { LineIter::new(b'\n', skippable_text) .par_bridge() .map(|line| { // FORTRAN has a rule where it only counts as a comment if it's the // first character in the column, so removing starting whitespace // could cause a miscount. let line = if is_fortran { line } else { line.trim() }; if line.trim().is_empty() { (1, 0, 0) } else if is_literate || comments.iter().any(|c| line.starts_with(c.as_bytes())) { (0, 0, 1) } else { (0, 1, 0) } }) .reduce(|| (0, 0, 0), |a, b| (a.0 + b.0, a.1 + b.1, a.2 + b.2)) }; let (mut stats, (blanks, code, comments)) = rayon::join(parse_lines, simple_parse); stats.blanks += blanks; stats.code += code; stats.comments += comments; stats } else { self.parse_lines(config, text, CodeStats::new(), syntax) } } #[inline] fn parse_lines( self, config: &Config, lines: &[u8], mut stats: CodeStats, mut syntax: SyntaxCounter, ) -> CodeStats { let mut stepper = LineStep::new(b'\n', 0, lines.len()); while let Some((start, end)) = stepper.next(lines) { let line = &lines[start..end]; // FORTRAN has a rule where it only counts as a comment if it's the // first character in the column, so removing starting whitespace // could cause a miscount. let line = if syntax.shared.is_fortran { line } else { line.trim() }; trace!("{}", String::from_utf8_lossy(line)); if syntax.try_perform_single_line_analysis(line, &mut stats) { continue; } let started_in_comments = !syntax.stack.is_empty() || (config.treat_doc_strings_as_comments == Some(true) && syntax.quote.is_some() && syntax.quote_is_doc_quote); let ended_with_comments = match syntax.perform_multi_line_analysis(lines, start, end, config) { crate::language::syntax::AnalysisReport::Normal(end) => end, crate::language::syntax::AnalysisReport::ChildLanguage(FileContext { language, end, stats: blob, }) => { match language { LanguageContext::Markdown { balanced, language } => { // Add the lines for the code fences. stats.comments += if balanced { 2 } else { 1 }; // Add the code inside the fence to the stats. *stats.blobs.entry(language).or_default() += blob; } LanguageContext::Rust => { // Add all the markdown blobs. *stats.blobs.entry(LanguageType::Markdown).or_default() += blob; } LanguageContext::LinguaFranca => { let child_lang = syntax.get_lf_target_language(); *stats.blobs.entry(child_lang).or_default() += blob; } LanguageContext::Html { language } => { stats.code += 1; // Add all the markdown blobs. *stats.blobs.entry(language).or_default() += blob; } } // Advance to after the language code and the delimiter.. stepper = LineStep::new(b'\n', end, lines.len()); continue; } }; trace!("{}", String::from_utf8_lossy(line)); if syntax.shared.is_literate || syntax.line_is_comment(line, config, ended_with_comments, started_in_comments) { stats.comments += 1; trace!("Comment No.{}", stats.comments); trace!("Was the Comment stack empty?: {}", !started_in_comments); } else { stats.code += 1; trace!("Code No.{}", stats.code); } } stats } fn parse_jupyter(&self, json: &[u8], config: &Config) -> Option<CodeStats> { #[derive(Deserialize)] struct Jupyter { cells: Vec<JupyterCell>, metadata: JupyterMetadata, } #[derive(Clone, Copy, Deserialize, PartialEq, Eq)] #[serde(rename_all = "lowercase")] enum CellType { Markdown, Code, } #[derive(Deserialize)] struct JupyterCell { cell_type: CellType, source: Vec<String>, } #[derive(Deserialize)] struct JupyterMetadata { kernelspec: serde_json::Value, language_info: serde_json::Value, } let jupyter: Jupyter = serde_json::from_slice(json).ok()?; let mut jupyter_stats = CodeStats::new(); let language = jupyter .metadata .kernelspec .get("language") .and_then(serde_json::Value::as_str) .and_then(|v| LanguageType::from_str(v).ok()) .or_else(|| { jupyter .metadata .language_info .get("file_extension") .and_then(serde_json::Value::as_str) .and_then(LanguageType::from_file_extension) }) .unwrap_or(LanguageType::Python); let iter = jupyter .cells .par_iter() .map(|cell| match cell.cell_type { CellType::Markdown => ( LanguageType::Markdown, LanguageType::Markdown.parse_from_str(cell.source.join(""), config), ), CellType::Code => ( language, language.parse_from_str(cell.source.join(""), config), ), }) .collect::<Vec<_>>(); for (language, stats) in iter { *jupyter_stats.blobs.entry(language).or_default() += &stats; jupyter_stats += &stats; } Some(jupyter_stats) } /// The embedded language in LF is declared in a construct that looks like this: `target C;`, `target Python`. /// This is the first thing in the file (although there may be comments before). fn find_lf_target_language(&self, bytes: &[u8]) -> Option<LanguageType> { use regex::bytes::Regex; static LF_TARGET_REGEX: Lazy<Regex> = Lazy::new(|| Regex::new(r#"(?m)\btarget\s+(\w+)\s*($|;|\{)"#).unwrap()); LF_TARGET_REGEX.captures(bytes).and_then(|captures| { let name = captures.get(1).unwrap().as_bytes(); if name == b"CCpp" { // this is a special alias for the C target in LF Some(C) } else { let name_str = &String::from_utf8_lossy(name); let by_name = LanguageType::from_name(name_str); if by_name.is_none() { trace!("LF target not recognized: {}", name_str); } by_name } }) } } #[cfg(test)] mod tests { use super::*; use std::{fs, path::Path}; #[test] fn rust_allows_nested() { assert!(LanguageType::Rust.allows_nested()); } fn assert_stats(stats: &CodeStats, blanks: usize, code: usize, comments: usize) { assert_eq!(stats.blanks, blanks, "expected {} blank lines", blanks); assert_eq!(stats.code, code, "expected {} code lines", code); assert_eq!( stats.comments, comments, "expected {} comment lines", comments ); } #[test] fn jupyter_notebook_has_correct_totals() { let sample_notebook = fs::read_to_string(Path::new("tests").join("data").join("jupyter.ipynb")).unwrap(); let stats = LanguageType::Jupyter .parse_jupyter(sample_notebook.as_bytes(), &Config::default()) .unwrap(); assert_stats(&stats, 115, 528, 333); } #[test] fn lf_embedded_language_is_counted() { let file_text = fs::read_to_string(Path::new("tests").join("data").join("linguafranca.lf")).unwrap(); let stats = LinguaFranca.parse_from_str(file_text, &Config::default()); assert_stats(&stats, 9, 11, 8); assert_eq!(stats.blobs.len(), 1, "num embedded languages"); let rust_stats = stats.blobs.get(&Rust).expect("should have a Rust entry"); assert_stats(rust_stats, 2, 5, 1); } } 0707010000002F000081A400000000000000000000000166C8A4FD000040B9000000000000000000000000000000000000003D00000000tokei-13.0.0.alpha.5+git0/src/language/language_type.tera.rsuse arbitrary::Arbitrary; /// Represents a individual programming language. Can be used to provide /// information about the language, such as multi line comments, single line /// comments, string literal syntax, whether a given language allows nesting /// comments. #[derive(Deserialize)] #[derive(Arbitrary, Clone, Copy, Debug, Eq, Hash, Ord, PartialEq, PartialOrd)] #[non_exhaustive] #[allow(clippy::upper_case_acronyms)] pub enum LanguageType { {% for key, value in languages -%} #[allow(missing_docs)] {% if value.name is defined %} #[serde(alias = "{{value.name}}")] {% else %} #[serde(alias = "{{key}}")] {% endif %} {{key}}, {% endfor %} } impl LanguageType { /// Returns the display name of a language. /// /// ``` /// # use tokei::*; /// let bash = LanguageType::Bash; /// /// assert_eq!(bash.name(), "BASH"); /// ``` pub fn name(self) -> &'static str { match self { {% for key, value in languages -%} {{key}} => {% if value.name %}"{{value.name}}"{% else %}"{{key}}"{% endif %}, {% endfor %} } } pub(crate) fn _is_blank(self) -> bool { match self { {% for key, v in languages -%} {{key}} => {{ v.blank | default(value=false) }}, {% endfor %} } } pub(crate) fn is_fortran(self) -> bool { self == LanguageType::FortranModern || self == LanguageType::FortranLegacy } /// Returns whether the language is "literate", meaning that it considered /// to primarily be documentation and is counted primarily as comments /// rather than procedural code. pub fn is_literate(self) -> bool { match self { {% for key, v in languages -%} {{key}} => {{ v.literate | default(value=false) }}, {% endfor %} } } /// Provides every variant in a Vec pub fn list() -> &'static [(Self, &'static [&'static str])] { &[{% for key, val in languages -%} ({{key}}, {% if val.extensions %} &[{% for extension in val.extensions %}"{{extension}}", {% endfor %}], {% else %} &[], {% endif %}), {% endfor %}] } /// Returns the single line comments of a language. /// ``` /// use tokei::LanguageType; /// let lang = LanguageType::Rust; /// assert_eq!(lang.line_comments(), &["//"]); /// ``` pub fn line_comments(self) -> &'static [&'static str] { match self { {% for key, value in languages -%} {{key}} => &[{% for item in value.line_comment | default(value=[]) %}"{{item}}",{% endfor %}], {% endfor %} } } /// Returns the single line comments of a language. /// ``` /// use tokei::LanguageType; /// let lang = LanguageType::Rust; /// assert_eq!(lang.multi_line_comments(), &[("/*", "*/")]); /// ``` pub fn multi_line_comments(self) -> &'static [(&'static str, &'static str)] { match self { {% for key, value in languages -%} {{key}} => &[ {%- for items in value.multi_line_comments | default(value=[]) -%} ({% for item in items %}"{{item}}",{% endfor %}), {%- endfor -%} ], {% endfor %} } } /// Returns whether the language allows nested multi line comments. /// ``` /// use tokei::LanguageType; /// let lang = LanguageType::Rust; /// assert!(lang.allows_nested()); /// ``` pub fn allows_nested(self) -> bool { match self { {% for key, v in languages -%} {{key}} => {{ v.nested | default(value=false) }}, {% endfor %} } } /// Returns what nested comments the language has. (Currently only D has /// any of this type.) /// ``` /// use tokei::LanguageType; /// let lang = LanguageType::D; /// assert_eq!(lang.nested_comments(), &[("/+", "+/")]); /// ``` pub fn nested_comments(self) -> &'static [(&'static str, &'static str)] { match self { {% for key, value in languages -%} {{key}} => &[ {%- for items in value.nested_comments | default(value=[]) -%} ({% for item in items %}"{{item}}",{% endfor %}), {%- endfor -%} ], {% endfor %} } } /// Returns the quotes of a language. /// ``` /// use tokei::LanguageType; /// let lang = LanguageType::C; /// assert_eq!(lang.quotes(), &[("\"", "\"")]); /// ``` pub fn quotes(self) -> &'static [(&'static str, &'static str)] { match self { {% for key, value in languages -%} {{key}} => &[ {%- for items in value.quotes | default(value=[]) -%} ({% for item in items %}"{{item}}",{% endfor %}), {%- endfor -%} ], {% endfor %} } } /// Returns the verbatim quotes of a language. /// ``` /// use tokei::LanguageType; /// let lang = LanguageType::CSharp; /// assert_eq!(lang.verbatim_quotes(), &[("@\"", "\"")]); /// ``` pub fn verbatim_quotes(self) -> &'static [(&'static str, &'static str)] { match self { {% for key, value in languages -%} {{key}} => &[ {%- for items in value.verbatim_quotes | default(value=[]) -%} ({% for item in items %}"{{item}}",{% endfor %}), {%- endfor -%} ], {% endfor %} } } /// Returns the doc quotes of a language. /// ``` /// use tokei::LanguageType; /// let lang = LanguageType::Python; /// assert_eq!(lang.doc_quotes(), &[("\"\"\"", "\"\"\""), ("'''", "'''")]); /// ``` pub fn doc_quotes(self) -> &'static [(&'static str, &'static str)] { match self { {% for key, value in languages -%} {{key}} => &[ {% for items in value.doc_quotes | default(value=[])-%} ({% for item in items %}"{{item}}",{% endfor %}), {%- endfor %} ], {%- endfor %} } } /// Returns the shebang of a language. /// ``` /// use tokei::LanguageType; /// let lang = LanguageType::Bash; /// assert_eq!(lang.shebangs(), &["#!/bin/bash"]); /// ``` pub fn shebangs(self) -> &'static [&'static str] { match self { {% for key, lang in languages -%} {{key}} => &[{% for item in lang.shebangs | default(value=[]) %}"{{item}}",{% endfor %}], {% endfor %} } } pub(crate) fn any_multi_line_comments(self) -> &'static [(&'static str, &'static str)] { match self { {% for key, value in languages -%} {{key}} => &[ {%- set starting_multi_line_comments = value.multi_line_comments | default(value=[]) -%} {%- set starting_nested_comments = value.nested_comments | default(value=[]) -%} {%- for item in starting_multi_line_comments | concat(with=starting_nested_comments) -%} ("{{item.0}}", "{{item.1}}"), {%- endfor -%} ], {% endfor %} } } pub(crate) fn any_comments(self) -> &'static [&'static str] { match self { {% for key, value in languages -%} {{key}} => &[ {%- set starting_multi_line_comments = value.multi_line_comments | default(value=[]) -%} {%- set starting_nested_comments = value.nested_comments | default(value=[]) -%} {%- for item in starting_multi_line_comments | concat(with=starting_nested_comments) -%} "{{item.0}}", "{{item.1}}", {%- endfor -%} {%- for item in value.line_comment | default(value=[]) -%} "{{item}}", {%- endfor -%} ], {% endfor %} } } /// Returns the parts of syntax that determines whether tokei can skip large /// parts of analysis. pub fn important_syntax(self) -> &'static [&'static str] { match self { {% for key, value in languages -%} {%- set starting_quotes = value.quotes | default(value=[]) | map(attribute="0") -%} {%- set starting_doc_quotes = value.doc_quotes | default(value=[]) | map(attribute="0") -%} {%- set starting_multi_line_comments = value.multi_line_comments | default(value=[]) | map(attribute="0") -%} {%- set starting_nested_comments = value.nested_comments | default(value=[]) | map(attribute="0") -%} {%- set important_syntax = value.important_syntax | default(value=[]) -%} {{key}} => &[ {%- for item in starting_quotes | concat(with=starting_doc_quotes) | concat(with=starting_multi_line_comments) | concat(with=starting_nested_comments) | concat(with=important_syntax) -%} "{{item}}", {%- endfor -%} {%- for context in value.contexts | default(value=[]) -%} {% if value.kind == "html" %} "<{{context.tag}}", {% endif %} {%- endfor -%} ], {% endfor %} } } /// Get language from a file path. May open and read the file. /// /// ```no_run /// use tokei::{Config, LanguageType}; /// /// let rust = LanguageType::from_path("./main.rs", &Config::default()); /// /// assert_eq!(rust, Some(LanguageType::Rust)); /// ``` pub fn from_path<P: AsRef<Path>>(entry: P, _config: &Config) -> Option<Self> { let entry = entry.as_ref(); if let Some(filename) = fsutils::get_filename(entry) { match &*filename { {% for key, value in languages -%} {%- if value.filenames -%} {%- for item in value.filenames -%} | "{{item}}" {%- endfor -%} => return Some({{key}}), {% endif -%} {%- endfor %} _ => () } } match fsutils::get_extension(entry) { Some(extension) => LanguageType::from_file_extension(extension.as_str()), None => LanguageType::from_shebang(entry), } } /// Get language from a file extension. /// /// ```no_run /// use tokei::LanguageType; /// /// let rust = LanguageType::from_file_extension("rs"); /// /// assert_eq!(rust, Some(LanguageType::Rust)); /// ``` #[must_use] pub fn from_file_extension(extension: &str) -> Option<Self> { match extension { {% for key, value in languages -%} {%- if value.extensions -%} {%- for item in value.extensions %}| "{{item}}" {% endfor %}=> Some({{key}}), {% endif -%} {%- endfor %} extension => { warn!("Unknown extension: {}", extension); None }, } } /// Get language from its name. /// /// ```no_run /// use tokei::LanguageType; /// /// let rust = LanguageType::from_name("Rust"); /// /// assert_eq!(rust, Some(LanguageType::Rust)); /// ``` #[must_use] pub fn from_name(name: &str) -> Option<Self> { match name { {% for key, value in languages -%} {% if value.name and value.name != key -%} | "{{value.name}}" {% endif -%} | "{{key}}" => Some({{key}}), {% endfor %} unknown => { warn!("Unknown language name: {}", unknown); None }, } } /// Get language from its MIME type if available. /// /// ```no_run /// use tokei::LanguageType; /// /// let lang = LanguageType::from_mime("application/javascript"); /// /// assert_eq!(lang, Some(LanguageType::JavaScript)); /// ``` #[must_use] pub fn from_mime(mime: &str) -> Option<Self> { match mime { {% for key, value in languages -%} {%- if value.mime -%} {%- for item in value.mime %}| "{{item}}" {% endfor %}=> Some({{key}}), {% endif -%} {%- endfor %} _ => { warn!("Unknown MIME: {}", mime); None }, } } /// Get language from a shebang. May open and read the file. /// /// ```no_run /// use tokei::LanguageType; /// /// let rust = LanguageType::from_shebang("./main.rs"); /// /// assert_eq!(rust, Some(LanguageType::Rust)); /// ``` pub fn from_shebang<P: AsRef<Path>>(entry: P) -> Option<Self> { // Read at max `READ_LIMIT` bytes from the given file. // A typical shebang line has a length less than 32 characters; // e.g. '#!/bin/bash' - 11B / `#!/usr/bin/env python3` - 22B // It is *very* unlikely the file contains a valid shebang syntax // if we don't find a newline character after searching the first 128B. const READ_LIMIT: usize = 128; let mut file = File::open(entry).ok()?; let mut buf = [0; READ_LIMIT]; let len = file.read(&mut buf).ok()?; let buf = &buf[..len]; let first_line = buf.split(|b| *b == b'\n').next()?; let first_line = std::str::from_utf8(first_line).ok()?; let mut words = first_line.split_whitespace(); match words.next() { {# First match against any shebang paths, and then check if the language matches any found in the environment shebang path. #} {% for key, value in languages -%} {%- if value.shebangs %} {%- for item in value.shebangs %}| Some("{{item}}") {% endfor %}=> Some({{key}}), {% endif -%} {%- endfor %} Some("#!/usr/bin/env") => { if let Some(word) = words.next() { match word { {% for key, value in languages -%} {%- if value.env -%} {%- for item in value.env %} {% if loop.index == 1 %} _ if word.starts_with("{{item}}") {% else %} || word.starts_with("{{item}}") {% endif %} {% endfor %}=> Some({{key}}), {% endif -%} {%- endfor %} env => { warn!("Unknown environment: {:?}", env); None } } } else { None } } _ => None, } } } impl FromStr for LanguageType { type Err = &'static str; fn from_str(from: &str) -> Result<Self, Self::Err> { match &*from.to_lowercase() { {% for key, value in languages %} {% if value.name %}"{{value.name | lower}}"{% else %}"{{key | lower}}"{% endif %} => Ok({{key}}), {% endfor %} _ => Err("Language not found, please use `-l` to see all available\ languages."), } } } impl fmt::Display for LanguageType { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "{}", self.name()) } } impl<'a> From<LanguageType> for Cow<'a, LanguageType> { fn from(from: LanguageType) -> Self { Cow::Owned(from) } } impl<'a> From<&'a LanguageType> for Cow<'a, LanguageType> { fn from(from: &'a LanguageType) -> Self { Cow::Borrowed(from) } } 07070100000030000081A400000000000000000000000166C8A4FD000011D9000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/src/language/languages.rsuse std::{ collections::{btree_map, BTreeMap}, iter::IntoIterator, ops::{AddAssign, Deref, DerefMut}, path::Path, }; use rayon::prelude::*; use crate::{ config::Config, language::{Language, LanguageType}, utils, }; /// A newtype representing a list of languages counted in the provided /// directory. /// ([_List of /// Languages_](https://github.com/XAMPPRocky/tokei#supported-languages)) #[derive(Debug, Default, PartialEq)] pub struct Languages { inner: BTreeMap<LanguageType, Language>, } impl serde::Serialize for Languages { fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error> where S: serde::Serializer, { self.inner.serialize(serializer) } } impl<'de> serde::Deserialize<'de> for Languages { fn deserialize<D>(deserializer: D) -> Result<Self, D::Error> where D: serde::Deserializer<'de>, { let map = <_>::deserialize(deserializer)?; Ok(Self::from_previous(map)) } } impl Languages { fn from_previous(map: BTreeMap<LanguageType, Language>) -> Self { use std::collections::btree_map::Entry; let mut me = Self::new(); for (name, input_language) in map { match me.entry(name) { Entry::Occupied(mut entry) => { *entry.get_mut() += input_language; } Entry::Vacant(entry) => { entry.insert(input_language); } } } me } /// Populates the `Languages` struct with statistics about languages /// provided by [`Language`]. /// /// Takes a `&[&str]` of paths to recursively traverse, paths can be /// relative, absolute or glob paths. a second `&[&str]` of paths to ignore, /// these strings use the `.gitignore` syntax, such as `target` /// or `**/*.bk`. /// /// ```no_run /// use tokei::{Config, Languages}; /// /// let mut languages = Languages::new(); /// languages.get_statistics(&["."], &[".git", "target"], &Config::default()); /// ``` /// /// [`Language`]: struct.Language.html pub fn get_statistics<A: AsRef<Path>>( &mut self, paths: &[A], ignored: &[&str], config: &Config, ) { utils::fs::get_all_files(paths, ignored, &mut self.inner, config); self.inner.par_iter_mut().for_each(|(_, l)| l.total()); } /// Constructs a new, Languages struct. Languages is always empty and does /// not allocate. /// /// ```rust /// # use tokei::*; /// let languages = Languages::new(); /// ``` #[must_use] pub fn new() -> Self { Languages::default() } /// Summary of the Languages struct. #[must_use] pub fn total(self: &Languages) -> Language { let mut total = Language::new(); for (ty, l) in self { let language = l.summarise(); total.comments += language.comments; total.blanks += language.blanks; total.code += language.code; total.inaccurate |= language.inaccurate; total.children.insert(*ty, language.reports.clone()); } total } } impl IntoIterator for Languages { type Item = <BTreeMap<LanguageType, Language> as IntoIterator>::Item; type IntoIter = <BTreeMap<LanguageType, Language> as IntoIterator>::IntoIter; fn into_iter(self) -> Self::IntoIter { self.inner.into_iter() } } impl<'a> IntoIterator for &'a Languages { type Item = (&'a LanguageType, &'a Language); type IntoIter = btree_map::Iter<'a, LanguageType, Language>; fn into_iter(self) -> Self::IntoIter { self.inner.iter() } } impl<'a> IntoIterator for &'a mut Languages { type Item = (&'a LanguageType, &'a mut Language); type IntoIter = btree_map::IterMut<'a, LanguageType, Language>; fn into_iter(self) -> Self::IntoIter { self.inner.iter_mut() } } impl AddAssign<BTreeMap<LanguageType, Language>> for Languages { fn add_assign(&mut self, rhs: BTreeMap<LanguageType, Language>) { for (name, language) in rhs { if let Some(result) = self.inner.get_mut(&name) { *result += language; } } } } impl Deref for Languages { type Target = BTreeMap<LanguageType, Language>; fn deref(&self) -> &Self::Target { &self.inner } } impl DerefMut for Languages { fn deref_mut(&mut self) -> &mut BTreeMap<LanguageType, Language> { &mut self.inner } } 07070100000031000081A400000000000000000000000166C8A4FD000014E4000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/src/language/mod.rsmod embedding; pub mod language_type; pub mod languages; mod syntax; use std::{collections::BTreeMap, mem, ops::AddAssign}; pub use self::{language_type::*, languages::Languages}; use crate::{sort::Sort, stats::Report}; /// A struct representing statistics about a single Language. #[derive(Clone, Debug, Deserialize, Default, PartialEq, Serialize)] pub struct Language { /// The total number of blank lines. pub blanks: usize, /// The total number of lines of code. pub code: usize, /// The total number of comments(both single, and multi-line) pub comments: usize, /// A collection of statistics of individual files. pub reports: Vec<Report>, /// A map of any languages found in the reports. pub children: BTreeMap<LanguageType, Vec<Report>>, /// Whether this language had problems with file parsing pub inaccurate: bool, } impl Language { /// Constructs a new empty Language with the comments provided. /// /// ``` /// # use tokei::*; /// let mut rust = Language::new(); /// ``` #[must_use] pub fn new() -> Self { Self::default() } /// Returns the total number of lines. #[inline] #[must_use] pub fn lines(&self) -> usize { self.blanks + self.code + self.comments } /// Add a `Report` to the Language. This will not update the totals in the /// Language struct. pub fn add_report(&mut self, report: Report) { for (lang, stats) in &report.stats.blobs { let mut new_report = Report::new(report.name.clone()); new_report.stats = stats.clone(); self.children.entry(*lang).or_default().push(new_report); } self.reports.push(report); } /// Marks this language as possibly not reflecting correct stats. #[inline] pub fn mark_inaccurate(&mut self) { self.inaccurate = true; } /// Creates a new `Language` from `self`, which is a summarised version /// of the language that doesn't contain any children. It will count /// non-blank lines in child languages as code unless the child language is /// considered "literate" then it will be counted as comments. #[must_use] pub fn summarise(&self) -> Language { let mut summary = self.clone(); for reports in self.children.values() { for stats in reports.iter().map(|r| r.stats.summarise()) { summary.comments += stats.comments; summary.code += stats.code; summary.blanks += stats.blanks; } } summary } /// Totals up the statistics of the `Stat` structs currently contained in /// the language. /// /// ```no_run /// use std::{collections::BTreeMap, path::PathBuf}; /// use tokei::Language; /// /// let mut language = Language::new(); /// /// // Add stats... /// /// assert_eq!(0, language.lines()); /// /// language.total(); /// /// assert_eq!(10, language.lines()); /// ``` pub fn total(&mut self) { let mut blanks = 0; let mut code = 0; let mut comments = 0; for report in &self.reports { blanks += report.stats.blanks; code += report.stats.code; comments += report.stats.comments; } self.blanks = blanks; self.code = code; self.comments = comments; } /// Checks if the language is empty. Empty meaning it doesn't have any /// statistics. /// /// ``` /// # use tokei::*; /// let rust = Language::new(); /// /// assert!(rust.is_empty()); /// ``` #[must_use] pub fn is_empty(&self) -> bool { self.code == 0 && self.comments == 0 && self.blanks == 0 && self.children.is_empty() } /// Sorts each of the `Report`s contained in the language based /// on what category is provided. /// /// ```no_run /// use std::{collections::BTreeMap, path::PathBuf}; /// use tokei::{Language, Sort}; /// /// let mut language = Language::new(); /// /// // Add stats... /// /// language.sort_by(Sort::Lines); /// assert_eq!(20, language.reports[0].stats.lines()); /// /// language.sort_by(Sort::Code); /// assert_eq!(8, language.reports[0].stats.code); /// ``` pub fn sort_by(&mut self, category: Sort) { match category { Sort::Blanks => self .reports .sort_by(|a, b| b.stats.blanks.cmp(&a.stats.blanks)), Sort::Comments => self .reports .sort_by(|a, b| b.stats.comments.cmp(&a.stats.comments)), Sort::Code => self.reports.sort_by(|a, b| b.stats.code.cmp(&a.stats.code)), Sort::Files => self.reports.sort_by(|a, b| a.name.cmp(&b.name)), Sort::Lines => self .reports .sort_by(|a, b| b.stats.lines().cmp(&a.stats.lines())), } } } impl AddAssign for Language { fn add_assign(&mut self, mut rhs: Self) { self.comments += rhs.comments; self.blanks += rhs.blanks; self.code += rhs.code; self.reports.extend(mem::take(&mut rhs.reports)); self.children.extend(mem::take(&mut rhs.children)); self.inaccurate |= rhs.inaccurate; } } 07070100000032000081A400000000000000000000000166C8A4FD00005EF3000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/src/language/syntax.rsuse std::sync::Arc; use aho_corasick::AhoCorasick; use dashmap::DashMap; use grep_searcher::LineStep; use log::Level::Trace; use once_cell::sync::Lazy; use super::embedding::{ RegexCache, RegexFamily, ENDING_LF_BLOCK_REGEX, ENDING_MARKDOWN_REGEX, END_SCRIPT, END_STYLE, END_TEMPLATE, }; use crate::LanguageType::LinguaFranca; use crate::{stats::CodeStats, utils::ext::SliceExt, Config, LanguageType}; /// Tracks the syntax of the language as well as the current state in the file. /// Current has what could be consider three types of mode. /// - `plain` mode: This is the normal state, blanks are counted as blanks, /// string literals can trigger `string` mode, and comments can trigger /// `comment` mode. /// - `string` mode: This when the state machine is current inside a string /// literal for a given language, comments cannot trigger `comment` mode while /// in `string` mode. /// - `comment` mode: This when the state machine is current inside a comment /// for a given language, strings cannot trigger `string` mode while in /// `comment` mode. #[derive(Clone, Debug)] pub(crate) struct SyntaxCounter { pub(crate) shared: Arc<SharedMatchers>, pub(crate) quote: Option<&'static str>, pub(crate) quote_is_doc_quote: bool, pub(crate) stack: Vec<&'static str>, pub(crate) quote_is_verbatim: bool, pub(crate) lf_embedded_language: Option<LanguageType>, } #[derive(Clone, Debug)] pub(crate) struct FileContext { pub(crate) language: LanguageContext, pub(crate) stats: CodeStats, pub(crate) end: usize, } impl FileContext { pub fn new(language: LanguageContext, end: usize, stats: CodeStats) -> Self { Self { language, stats, end, } } } #[derive(Clone, Debug)] pub(crate) enum LanguageContext { Html { language: LanguageType, }, LinguaFranca, Markdown { balanced: bool, language: LanguageType, }, Rust, } #[derive(Clone, Debug)] pub(crate) struct SharedMatchers { pub language: LanguageType, pub allows_nested: bool, pub doc_quotes: &'static [(&'static str, &'static str)], pub important_syntax: AhoCorasick, #[allow(dead_code)] pub any_comments: &'static [&'static str], pub is_fortran: bool, pub is_literate: bool, pub line_comments: &'static [&'static str], pub any_multi_line_comments: &'static [(&'static str, &'static str)], pub multi_line_comments: &'static [(&'static str, &'static str)], pub nested_comments: &'static [(&'static str, &'static str)], pub string_literals: &'static [(&'static str, &'static str)], pub verbatim_string_literals: &'static [(&'static str, &'static str)], } impl SharedMatchers { pub fn new(language: LanguageType) -> Arc<Self> { static MATCHERS: Lazy<DashMap<LanguageType, Arc<SharedMatchers>>> = Lazy::new(DashMap::new); MATCHERS .entry(language) .or_insert_with(|| Arc::new(Self::init(language))) .value() .clone() } pub fn init(language: LanguageType) -> Self { fn init_corasick(pattern: &[&'static str]) -> AhoCorasick { AhoCorasick::builder() .match_kind(aho_corasick::MatchKind::LeftmostLongest) .start_kind(aho_corasick::StartKind::Unanchored) .prefilter(true) .kind(Some(aho_corasick::AhoCorasickKind::DFA)) .build(pattern) .unwrap() } Self { language, allows_nested: language.allows_nested(), doc_quotes: language.doc_quotes(), is_fortran: language.is_fortran(), is_literate: language.is_literate(), important_syntax: init_corasick(language.important_syntax()), any_comments: language.any_comments(), line_comments: language.line_comments(), multi_line_comments: language.multi_line_comments(), any_multi_line_comments: language.any_multi_line_comments(), nested_comments: language.nested_comments(), string_literals: language.quotes(), verbatim_string_literals: language.verbatim_quotes(), } } } #[derive(Debug)] pub(crate) enum AnalysisReport { /// No child languages were found, contains a boolean representing whether /// the line ended with comments or not. Normal(bool), ChildLanguage(FileContext), } impl SyntaxCounter { pub(crate) fn new(language: LanguageType) -> Self { Self { shared: SharedMatchers::new(language), quote_is_doc_quote: false, quote_is_verbatim: false, stack: Vec::with_capacity(1), lf_embedded_language: None, quote: None, } } /// Returns whether the syntax is currently in plain mode. pub(crate) fn is_plain_mode(&self) -> bool { self.quote.is_none() && self.stack.is_empty() } /// Returns whether the syntax is currently in string mode. pub(crate) fn _is_string_mode(&self) -> bool { self.quote.is_some() } /// Returns whether the syntax is currently in comment mode. pub(crate) fn _is_comment_mode(&self) -> bool { !self.stack.is_empty() } pub(crate) fn get_lf_target_language(&self) -> LanguageType { // in case the target declaration was not found, default it to that language const DEFAULT_LANG: LanguageType = LinguaFranca; self.lf_embedded_language.unwrap_or(DEFAULT_LANG) } #[inline] pub(crate) fn parse_line_comment(&self, window: &[u8]) -> bool { if self.quote.is_some() || !self.stack.is_empty() { false } else if let Some(comment) = self .shared .line_comments .iter() .find(|c| window.starts_with(c.as_bytes())) { trace!("Start {:?}", comment); true } else { false } } /// Try to see if we can determine what a line is from examining the whole /// line at once. Returns `true` if successful. pub(crate) fn try_perform_single_line_analysis( &self, line: &[u8], stats: &mut crate::stats::CodeStats, ) -> bool { if !self.is_plain_mode() { false } else if line.trim().is_empty() { stats.blanks += 1; trace!("Blank No.{}", stats.blanks); true } else if self.shared.important_syntax.is_match(line) { false } else { trace!("^ Skippable"); if self.shared.is_literate || self .shared .line_comments .iter() .any(|c| line.starts_with(c.as_bytes())) { stats.comments += 1; trace!("Comment No.{}", stats.comments); } else { stats.code += 1; trace!("Code No.{}", stats.code); } true } } pub(crate) fn perform_multi_line_analysis( &mut self, lines: &[u8], start: usize, end: usize, config: &Config, ) -> AnalysisReport { let mut ended_with_comments = false; let mut skip = 0; macro_rules! skip { ($skip:expr) => {{ skip = $skip - 1; }}; } let regex_cache = RegexCache::build(self.shared.language, lines, start, end); for i in start..end { if skip != 0 { skip -= 1; continue; } let window = &lines[i..]; if window.trim().is_empty() { break; } ended_with_comments = false; let is_end_of_quote_or_multi_line = self .parse_end_of_quote(window) .or_else(|| self.parse_end_of_multi_line(window)); if let Some(skip_amount) = is_end_of_quote_or_multi_line { ended_with_comments = true; skip!(skip_amount); continue; } else if self.quote.is_some() { continue; } if let Some(child) = self.parse_context(lines, i, end, config, ®ex_cache) { return AnalysisReport::ChildLanguage(child); } let is_quote_or_multi_line = self .parse_quote(window) .or_else(|| self.parse_multi_line_comment(window)); if let Some(skip_amount) = is_quote_or_multi_line { skip!(skip_amount); continue; } if self.parse_line_comment(window) { ended_with_comments = true; break; } } AnalysisReport::Normal(ended_with_comments) } /// Performs a set of heuristics to determine whether a line is a comment or /// not. The procedure is as follows. /// /// - Yes/No: Counted as Comment /// /// 1. Check if we're in string mode /// 1. Check if string literal is a doc string and whether tokei has /// been configured to treat them as comments. /// - Yes: When the line starts with the doc string or when we are /// continuing from a previous line. /// - No: The string is a normal string literal or tokei isn't /// configured to count them as comments. /// 2. If we're not in string mode, check if we left it this on this line. /// - Yes: When we found a doc quote and we started in comments. /// 3. Yes: When the whole line is a comment e.g. `/* hello */` /// 4. Yes: When the previous line started a multi-line comment. /// 5. Yes: When the line starts with a comment. /// 6. No: Any other input. pub(crate) fn line_is_comment( &self, line: &[u8], config: &crate::Config, _ended_with_comments: bool, started_in_comments: bool, ) -> bool { let trimmed = line.trim(); let whole_line_is_comment = || { self.shared .line_comments .iter() .any(|c| trimmed.starts_with(c.as_bytes())) || self .shared .any_multi_line_comments .iter() .any(|(start, end)| { trimmed.starts_with(start.as_bytes()) && trimmed.ends_with(end.as_bytes()) }) }; let starts_with_comment = || { let quote = match self.stack.last() { Some(q) => q, _ => return false, }; self.shared .any_multi_line_comments .iter() .any(|(start, end)| end == quote && trimmed.starts_with(start.as_bytes())) }; // `Some(true)` in order to respect the current configuration. #[allow(clippy::if_same_then_else)] if self.quote.is_some() { if self.quote_is_doc_quote && config.treat_doc_strings_as_comments == Some(true) { self.quote.map_or(false, |q| line.starts_with(q.as_bytes())) || (self.quote.is_some()) } else { false } } else if self .shared .doc_quotes .iter() .any(|(_, e)| line.contains_slice(e.as_bytes())) && started_in_comments { true } else if (whole_line_is_comment)() { true } else if started_in_comments { true } else { (starts_with_comment)() } } #[inline] pub(crate) fn parse_context( &mut self, lines: &[u8], start: usize, end: usize, config: &Config, regex_cache: &RegexCache, ) -> Option<FileContext> { use std::str::FromStr; // static TYPE_REGEX: Lazy<Regex> = Lazy::new(|| Regex::new(r#"type="(.*)".*>"#).unwrap()); if self.quote.is_some() || !self.stack.is_empty() { return None; } match regex_cache.family()? { RegexFamily::Markdown(md) => { if !lines[start..end].contains_slice(b"```") { return None; } let opening_fence = md.starts_in_range(start, end)?; let start_of_code = opening_fence.end(); let closing_fence = ENDING_MARKDOWN_REGEX.find(&lines[start_of_code..]); if let Some(m) = &closing_fence { trace!("{:?}", String::from_utf8_lossy(m.as_bytes())); } let end_of_code = closing_fence .map_or_else(|| lines.len(), |fence| start_of_code + fence.start()); let end_of_code_block = closing_fence.map_or_else(|| lines.len(), |fence| start_of_code + fence.end()); let balanced = closing_fence.is_some(); let identifier = &opening_fence.as_bytes().trim()[3..]; let language = identifier .split(|&b| b == b',') .find_map(|s| LanguageType::from_str(&String::from_utf8_lossy(s)).ok())?; trace!( "{} BLOCK: {:?}", language, String::from_utf8_lossy(&lines[start_of_code..end_of_code]) ); let stats = language.parse_from_slice(lines[start_of_code..end_of_code].trim(), config); Some(FileContext::new( LanguageContext::Markdown { balanced, language }, end_of_code_block, stats, )) } RegexFamily::Rust => { let rest = &lines[start..]; let comment_syntax = if rest.trim_start().starts_with(b"///") { b"///" } else if rest.trim_start().starts_with(b"//!") { b"//!" } else { return None; }; let mut stepper = LineStep::new(b'\n', start, lines.len()); let mut markdown = Vec::new(); let mut end_of_block = lines.len(); while let Some((start, end)) = stepper.next(lines) { if lines[start..].trim().starts_with(comment_syntax) { trace!("{}", String::from_utf8_lossy(&lines[start..end])); let line = lines[start..end].trim_start(); let stripped_line = &line[3.min(line.len())..]; markdown.extend_from_slice(stripped_line); end_of_block = end; } else { end_of_block = start; break; } } trace!("Markdown found: {:?}", String::from_utf8_lossy(&markdown)); let doc_block = LanguageType::Markdown.parse_from_slice(markdown.trim(), config); Some(FileContext::new( LanguageContext::Rust, end_of_block, doc_block, )) } RegexFamily::LinguaFranca(lf) => { let opening_fence = lf.starts_in_range(start, end)?; let start_of_code = opening_fence.end(); let closing_fence = ENDING_LF_BLOCK_REGEX.find(&lines[start_of_code..]); let end_of_code = closing_fence .map_or_else(|| lines.len(), |fence| start_of_code + fence.start()); let block_contents = &lines[start_of_code..end_of_code]; trace!("LF block: {:?}", String::from_utf8_lossy(block_contents)); let stats = self.get_lf_target_language().parse_from_slice( block_contents.trim_first_and_last_line_of_whitespace(), config, ); trace!("-> stats: {:?}", stats); Some(FileContext::new( LanguageContext::LinguaFranca, end_of_code, stats, )) } RegexFamily::HtmlLike(html) => { if let Some(mut captures) = html.start_script_in_range(start, end) { let start_of_code = captures.next().unwrap().end(); let closing_tag = END_SCRIPT.find(&lines[start_of_code..])?; let end_of_code = start_of_code + closing_tag.start(); let language = captures .next() .and_then(|m| { LanguageType::from_mime(&String::from_utf8_lossy(m.as_bytes().trim())) }) .unwrap_or(LanguageType::JavaScript); let script_contents = &lines[start_of_code..end_of_code]; if script_contents.trim().is_empty() { return None; } let stats = language.parse_from_slice( script_contents.trim_first_and_last_line_of_whitespace(), config, ); Some(FileContext::new( LanguageContext::Html { language }, end_of_code, stats, )) } else if let Some(mut captures) = html.start_style_in_range(start, end) { let start_of_code = captures.next().unwrap().end(); let closing_tag = END_STYLE.find(&lines[start_of_code..])?; let end_of_code = start_of_code + closing_tag.start(); let language = captures .next() .and_then(|m| { LanguageType::from_str( &String::from_utf8_lossy(m.as_bytes().trim()).to_lowercase(), ) .ok() }) .unwrap_or(LanguageType::Css); let style_contents = &lines[start_of_code..end_of_code]; if style_contents.trim().is_empty() { return None; } let stats = language.parse_from_slice( style_contents.trim_first_and_last_line_of_whitespace(), config, ); Some(FileContext::new( LanguageContext::Html { language }, end_of_code, stats, )) } else if let Some(mut captures) = html.start_template_in_range(start, end) { let start_of_code = captures.next().unwrap().end(); let closing_tag = END_TEMPLATE.find(&lines[start_of_code..])?; let end_of_code = start_of_code + closing_tag.start(); let language = captures .next() .and_then(|m| { LanguageType::from_str( &String::from_utf8_lossy(m.as_bytes().trim()).to_lowercase(), ) .ok() }) .unwrap_or(LanguageType::Html); let template_contents = &lines[start_of_code..end_of_code]; if template_contents.trim().is_empty() { return None; } let stats = language.parse_from_slice( template_contents.trim_first_and_last_line_of_whitespace(), config, ); Some(FileContext::new( LanguageContext::Html { language }, end_of_code, stats, )) } else { None } } } } #[inline] pub(crate) fn parse_quote(&mut self, window: &[u8]) -> Option<usize> { if !self.stack.is_empty() { return None; } if let Some((start, end)) = self .shared .doc_quotes .iter() .find(|(s, _)| window.starts_with(s.as_bytes())) { trace!("Start Doc {:?}", start); self.quote = Some(end); self.quote_is_verbatim = false; self.quote_is_doc_quote = true; return Some(start.len()); } if let Some((start, end)) = self .shared .verbatim_string_literals .iter() .find(|(s, _)| window.starts_with(s.as_bytes())) { trace!("Start verbatim {:?}", start); self.quote = Some(end); self.quote_is_verbatim = true; self.quote_is_doc_quote = false; return Some(start.len()); } if let Some((start, end)) = self .shared .string_literals .iter() .find(|(s, _)| window.starts_with(s.as_bytes())) { trace!("Start {:?}", start); self.quote = Some(end); self.quote_is_verbatim = false; self.quote_is_doc_quote = false; return Some(start.len()); } None } #[inline] pub(crate) fn parse_end_of_quote(&mut self, window: &[u8]) -> Option<usize> { #[allow(clippy::if_same_then_else)] if self._is_string_mode() && window.starts_with(self.quote?.as_bytes()) { let quote = self.quote.take().unwrap(); trace!("End {:?}", quote); Some(quote.len()) } else if !self.quote_is_verbatim && window.starts_with(br"\\") { Some(2) } else if !self.quote_is_verbatim && window.starts_with(br"\") && self .shared .string_literals .iter() .any(|(start, _)| window[1..].starts_with(start.as_bytes())) { // Tell the state machine to skip the next character because it // has been escaped if the string isn't a verbatim string. Some(2) } else { None } } #[inline] pub(crate) fn parse_multi_line_comment(&mut self, window: &[u8]) -> Option<usize> { if self.quote.is_some() { return None; } let iter = self .shared .multi_line_comments .iter() .chain(self.shared.nested_comments); for &(start, end) in iter { if window.starts_with(start.as_bytes()) { if self.stack.is_empty() || self.shared.allows_nested || self.shared.nested_comments.contains(&(start, end)) { self.stack.push(end); if log_enabled!(Trace) && self.shared.allows_nested { trace!("Start nested {:?}", start); } else { trace!("Start {:?}", start); } } return Some(start.len()); } } None } #[inline] pub(crate) fn parse_end_of_multi_line(&mut self, window: &[u8]) -> Option<usize> { if self .stack .last() .map_or(false, |l| window.starts_with(l.as_bytes())) { let last = self.stack.pop().unwrap(); if log_enabled!(Trace) { if self.stack.is_empty() { trace!("End {:?}", last); } else { trace!("End {:?}. Still in comments.", last); } } Some(last.len()) } else { None } } } 07070100000033000081A400000000000000000000000166C8A4FD0000069D000000000000000000000000000000000000002500000000tokei-13.0.0.alpha.5+git0/src/lib.rs//! # Tokei: Count your code quickly. //! //! A simple, efficient library for counting code in directories. This //! functionality is also provided as a //! [CLI utility](//github.com/XAMPPRocky/tokei). Tokei uses a small state //! machine rather than regular expressions found in other code counters. Tokei //! can accurately count a lot more edge cases such as nested comments, or //! comment syntax inside string literals. //! //! # Examples //! //! Gets the total lines of code from all rust files in current directory, //! and all subdirectories. //! //! ```no_run //! use std::collections::BTreeMap; //! use std::fs::File; //! use std::io::Read; //! //! use tokei::{Config, Languages, LanguageType}; //! //! // The paths to search. Accepts absolute, relative, and glob paths. //! let paths = &["src", "tests"]; //! // Exclude any path that contains any of these strings. //! let excluded = &["target"]; //! // `Config` allows you to configure what is searched and counted. //! let config = Config::default(); //! //! let mut languages = Languages::new(); //! languages.get_statistics(paths, excluded, &config); //! let rust = &languages[&LanguageType::Rust]; //! //! println!("Lines of code: {}", rust.code); //! ``` #![deny( trivial_casts, trivial_numeric_casts, unused_variables, unstable_features, unused_import_braces, missing_docs )] #[macro_use] extern crate log; #[macro_use] extern crate serde; #[macro_use] mod utils; mod config; mod consts; mod language; mod sort; mod stats; pub use self::{ config::Config, consts::*, language::{Language, LanguageType, Languages}, sort::Sort, stats::{find_char_boundary, CodeStats, Report}, }; 07070100000034000081A400000000000000000000000166C8A4FD00000F78000000000000000000000000000000000000002600000000tokei-13.0.0.alpha.5+git0/src/main.rs#[macro_use] extern crate log; mod cli; mod cli_utils; mod consts; mod input; use std::{error::Error, io, process}; use tokei::{Config, Languages, Sort}; use crate::{ cli::Cli, cli_utils::Printer, consts::{ BLANKS_COLUMN_WIDTH, CODE_COLUMN_WIDTH, COMMENTS_COLUMN_WIDTH, FALLBACK_ROW_LEN, LANGUAGE_COLUMN_WIDTH, LINES_COLUMN_WIDTH, PATH_COLUMN_WIDTH, }, input::add_input, }; fn main() -> Result<(), Box<dyn Error>> { let mut cli = Cli::from_args(); if cli.print_languages { Cli::print_supported_languages()?; process::exit(0); } let config = cli.override_config(Config::from_config_files()); let mut languages = Languages::new(); if let Some(input) = cli.file_input() { if !add_input(input, &mut languages) { Cli::print_input_parse_failure(input); process::exit(1); } } let input = cli.input(); for path in &input { if ::std::fs::metadata(path).is_err() { eprintln!("Error: '{}' not found.", path); process::exit(1); } } let columns = cli .columns .or(config.columns) .or_else(|| { if cli.files { term_size::dimensions().map(|(w, _)| w) } else { None } }) .unwrap_or(FALLBACK_ROW_LEN) .max(FALLBACK_ROW_LEN); if cli.streaming == Some(crate::cli::Streaming::Simple) { println!( "#{:^LANGUAGE_COLUMN_WIDTH$} {:^PATH_COLUMN_WIDTH$} {:^LINES_COLUMN_WIDTH$} {:^CODE_COLUMN_WIDTH$} {:^COMMENTS_COLUMN_WIDTH$} {:^BLANKS_COLUMN_WIDTH$}", "language", "path", "lines", "code", "comments", "blanks" ); println!( "{:>LANGUAGE_COLUMN_WIDTH$} {:<PATH_COLUMN_WIDTH$} {:>LINES_COLUMN_WIDTH$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", (0..10).map(|_| "#").collect::<String>(), (0..80).map(|_| "#").collect::<String>(), (0..12).map(|_| "#").collect::<String>(), (0..12).map(|_| "#").collect::<String>(), (0..12).map(|_| "#").collect::<String>(), (0..12).map(|_| "#").collect::<String>() ); } languages.get_statistics(&input, &cli.ignored_directories(), &config); if config.for_each_fn.is_some() { process::exit(0); } if let Some(format) = cli.output { print!("{}", format.print(&languages).unwrap()); process::exit(0); } let mut printer = Printer::new( columns, cli.files, io::BufWriter::new(io::stdout()), cli.number_format, ); if languages.iter().any(|(_, lang)| lang.inaccurate) { printer.print_inaccuracy_warning()?; } printer.print_header()?; let mut is_sorted = false; if let Some(sort_category) = cli.sort.or(config.sort) { for (_, ref mut language) in &mut languages { language.sort_by(sort_category); } let mut languages: Vec<_> = languages.iter().collect(); match sort_category { Sort::Blanks => languages.sort_by(|a, b| b.1.blanks.cmp(&a.1.blanks)), Sort::Comments => languages.sort_by(|a, b| b.1.comments.cmp(&a.1.comments)), Sort::Code => languages.sort_by(|a, b| b.1.code.cmp(&a.1.code)), Sort::Files => languages.sort_by(|a, b| b.1.reports.len().cmp(&a.1.reports.len())), Sort::Lines => languages.sort_by(|a, b| b.1.lines().cmp(&a.1.lines())), } is_sorted = true; if cli.sort_reverse { printer.print_results(languages.into_iter().rev(), cli.compact, is_sorted)?; } else { printer.print_results(languages.into_iter(), cli.compact, is_sorted)?; } } else { printer.print_results(languages.iter(), cli.compact, is_sorted)?; } printer.print_total(&languages)?; Ok(()) } 07070100000035000081A400000000000000000000000166C8A4FD000005EF000000000000000000000000000000000000002600000000tokei-13.0.0.alpha.5+git0/src/sort.rsuse std::{borrow::Cow, str::FromStr}; use serde::de::{self, Deserialize, Deserializer}; /// Used for sorting languages. #[derive(Clone, Copy, Debug, Eq, Ord, PartialEq, PartialOrd)] pub enum Sort { /// Sort by number blank lines. Blanks, /// Sort by number comments lines. Comments, /// Sort by number code lines. Code, /// Sort by number files lines. Files, /// Sort by number of lines. Lines, } impl FromStr for Sort { type Err = String; fn from_str(s: &str) -> Result<Self, Self::Err> { Ok(if s.eq_ignore_ascii_case("blanks") { Sort::Blanks } else if s.eq_ignore_ascii_case("comments") { Sort::Comments } else if s.eq_ignore_ascii_case("code") { Sort::Code } else if s.eq_ignore_ascii_case("files") { Sort::Files } else if s.eq_ignore_ascii_case("lines") { Sort::Lines } else { return Err(format!("Unsupported sorting option: {}", s)); }) } } impl<'de> Deserialize<'de> for Sort { fn deserialize<D>(deserializer: D) -> Result<Self, D::Error> where D: Deserializer<'de>, { String::deserialize(deserializer)? .parse() .map_err(de::Error::custom) } } impl<'a> From<Sort> for Cow<'a, Sort> { fn from(from: Sort) -> Self { Cow::Owned(from) } } impl<'a> From<&'a Sort> for Cow<'a, Sort> { fn from(from: &'a Sort) -> Self { Cow::Borrowed(from) } } 07070100000036000081A400000000000000000000000166C8A4FD00000FC6000000000000000000000000000000000000002700000000tokei-13.0.0.alpha.5+git0/src/stats.rsuse crate::consts::{ BLANKS_COLUMN_WIDTH, CODE_COLUMN_WIDTH, COMMENTS_COLUMN_WIDTH, LINES_COLUMN_WIDTH, }; use crate::LanguageType; use std::{collections::BTreeMap, fmt, ops, path::PathBuf}; /// A struct representing stats about a single blob of code. #[derive(Clone, Debug, Default, PartialEq, serde::Deserialize, serde::Serialize)] #[non_exhaustive] pub struct CodeStats { /// The blank lines in the blob. pub blanks: usize, /// The lines of code in the blob. pub code: usize, /// The lines of comments in the blob. pub comments: usize, /// Language blobs that were contained inside this blob. pub blobs: BTreeMap<LanguageType, CodeStats>, } impl CodeStats { /// Creates a new blank `CodeStats`. #[must_use] pub fn new() -> Self { Self::default() } /// Get the total lines in a blob of code. #[must_use] pub fn lines(&self) -> usize { self.blanks + self.code + self.comments } /// Creates a new `CodeStats` from an existing one with all of the child /// blobs merged. #[must_use] pub fn summarise(&self) -> Self { let mut summary = self.clone(); for (_, stats) in std::mem::take(&mut summary.blobs) { let child_summary = stats.summarise(); summary.blanks += child_summary.blanks; summary.comments += child_summary.comments; summary.code += child_summary.code; } summary } } impl ops::AddAssign for CodeStats { fn add_assign(&mut self, rhs: Self) { self.add_assign(&rhs); } } impl ops::AddAssign<&'_ CodeStats> for CodeStats { fn add_assign(&mut self, rhs: &'_ CodeStats) { self.blanks += rhs.blanks; self.code += rhs.code; self.comments += rhs.comments; for (language, stats) in &rhs.blobs { *self.blobs.entry(*language).or_default() += stats; } } } /// A struct representing the statistics of a file. #[derive(Deserialize, Serialize, Clone, Debug, Default, PartialEq)] #[non_exhaustive] pub struct Report { /// The code statistics found in the file. pub stats: CodeStats, /// File name. pub name: PathBuf, } impl Report { /// Create a new `Report` from a [`PathBuf`]. /// /// [`PathBuf`]: //doc.rust-lang.org/std/path/struct.PathBuf.html #[must_use] pub fn new(name: PathBuf) -> Self { Self { name, ..Self::default() } } } impl ops::AddAssign<CodeStats> for Report { fn add_assign(&mut self, rhs: CodeStats) { self.stats += rhs; } } #[doc(hidden)] #[must_use] pub fn find_char_boundary(s: &str, index: usize) -> usize { for i in 0..4 { if s.is_char_boundary(index + i) { return index + i; } } unreachable!(); } macro_rules! display_stats { ($f:expr, $this:expr, $name:expr, $max:expr) => { write!( $f, " {: <max$} {:>LINES_COLUMN_WIDTH$} {:>CODE_COLUMN_WIDTH$} {:>COMMENTS_COLUMN_WIDTH$} {:>BLANKS_COLUMN_WIDTH$}", $name, $this.stats.lines(), $this.stats.code, $this.stats.comments, $this.stats.blanks, max = $max ) }; } impl fmt::Display for Report { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { let name = self.name.to_string_lossy(); let name_length = name.len(); // Added 2 to max length to cover wider Files column (see https://github.com/XAMPPRocky/tokei/issues/891). let max_len = f.width().unwrap_or(27) + 2; if name_length <= max_len { display_stats!(f, self, name, max_len) } else { let mut formatted = String::from("|"); // Add 1 to the index to account for the '|' we add to the output string let from = find_char_boundary(&name, name_length + 1 - max_len); formatted.push_str(&name[from..]); display_stats!(f, self, formatted, max_len) } } } 07070100000037000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000002400000000tokei-13.0.0.alpha.5+git0/src/utils07070100000038000081A400000000000000000000000166C8A4FD000010EC000000000000000000000000000000000000002B00000000tokei-13.0.0.alpha.5+git0/src/utils/ext.rs//! Various extensions to Rust std types. pub(crate) trait AsciiExt { fn is_whitespace(&self) -> bool; fn is_line_ending_whitespace(&self) -> bool; } impl AsciiExt for u8 { fn is_whitespace(&self) -> bool { *self == b' ' || (b'\x09'..=b'\x0d').contains(self) } fn is_line_ending_whitespace(&self) -> bool { *self == b'\n' } } pub(crate) trait SliceExt { fn trim_first_and_last_line_of_whitespace(&self) -> &Self; fn trim_start(&self) -> &Self; fn trim(&self) -> &Self; fn contains_slice(&self, needle: &Self) -> bool; } impl SliceExt for [u8] { fn trim_first_and_last_line_of_whitespace(&self) -> &Self { let start = self .iter() .position(|c| c.is_line_ending_whitespace() || !c.is_whitespace()) .map_or(0, |i| (i + 1).min(self.len().saturating_sub(1))); let end = self .iter() .rposition(|c| c.is_line_ending_whitespace() || !c.is_whitespace()) .map_or_else( || self.len().saturating_sub(1), |i| { // Remove the entire `\r\n` in the case that it was the line ending whitespace if self[i.saturating_sub(1)] == b'\r' && self[i] == b'\n' { i - 1 } else { i } }, ); if self[start..].is_empty() { return &[]; } &self[start..=end] } fn trim_start(&self) -> &Self { let length = self.len(); if length == 0 { return self; } let start = match self.iter().position(|c| !c.is_whitespace()) { Some(start) => start, None => return &[], }; &self[start..] } fn trim(&self) -> &Self { let length = self.len(); if length == 0 { return self; } let start = match self.iter().position(|c| !c.is_whitespace()) { Some(start) => start, None => return &[], }; let end = match self.iter().rposition(|c| !c.is_whitespace()) { Some(end) => end.max(start), _ => length, }; &self[start..=end] } fn contains_slice(&self, needle: &Self) -> bool { let self_length = self.len(); let needle_length = needle.len(); if needle_length == 0 || needle_length > self_length { return false; } else if needle_length == self_length { return self == needle; } for window in self.windows(needle_length) { if needle == window { return true; } } false } } #[cfg(test)] mod tests { use super::*; use proptest::prelude::*; #[test] fn is_whitespace() { assert!(b' '.is_whitespace()); assert!(b'\r'.is_whitespace()); assert!(b'\n'.is_whitespace()); } #[test] fn trim() { assert!([b' ', b' ', b' '].trim().is_empty()); assert!([b' ', b'\r', b'\n'].trim().is_empty()); assert!([b'\n'].trim().is_empty()); assert!([].trim().is_empty()); assert_eq!([b'a', b'b'], [b'a', b'b'].trim()); assert_eq!([b'h', b'i'], [b' ', b'h', b'i'].trim()); assert_eq!([b'h', b'i'], [b'h', b'i', b' '].trim()); assert_eq!([b'h', b'i'], [b' ', b'h', b'i', b' '].trim()); } #[test] fn contains() { assert!([1, 2, 3, 4, 5].contains_slice(&[1, 2, 3, 4, 5])); assert!([1, 2, 3, 4, 5].contains_slice(&[1, 2, 3])); assert!([1, 2, 3, 4, 5].contains_slice(&[3, 4, 5])); assert!([1, 2, 3, 4, 5].contains_slice(&[2, 3, 4])); assert!(![1, 2, 3, 4, 5].contains_slice(&[])); } #[test] fn trim_first_and_last_line_of_whitespace_edge_cases() { assert_eq!(b"", b"\ra ".trim_first_and_last_line_of_whitespace()); assert_eq!(b"a", b"\r\na ".trim_first_and_last_line_of_whitespace()); assert_eq!(b" ", b" ".trim_first_and_last_line_of_whitespace()); } proptest! { #[test] fn trim_first_and_last_line_of_whitespace_doesnt_panic(input: Vec<u8>) { let _ = &input.trim_first_and_last_line_of_whitespace(); } } } 07070100000039000081A400000000000000000000000166C8A4FD00003702000000000000000000000000000000000000002A00000000tokei-13.0.0.alpha.5+git0/src/utils/fs.rsuse std::{collections::BTreeMap, path::Path}; use ignore::{overrides::OverrideBuilder, DirEntry, WalkBuilder, WalkState::Continue}; use rayon::prelude::*; use crate::{ config::Config, language::{Language, LanguageType}, }; const IGNORE_FILE: &str = ".tokeignore"; pub fn get_all_files<A: AsRef<Path>>( paths: &[A], ignored_directories: &[&str], languages: &mut BTreeMap<LanguageType, Language>, config: &Config, ) { let languages = parking_lot::Mutex::new(languages); let (tx, rx) = crossbeam_channel::unbounded(); let mut paths = paths.iter(); let mut walker = WalkBuilder::new(paths.next().unwrap()); for path in paths { walker.add(path); } if !ignored_directories.is_empty() { let mut overrides = OverrideBuilder::new("."); for ignored in ignored_directories { rs_error!(overrides.add(&format!("!{}", ignored))); } walker.overrides(overrides.build().expect("Excludes provided were invalid")); } let ignore = config.no_ignore.map(|b| !b).unwrap_or(true); let ignore_dot = ignore && config.no_ignore_dot.map(|b| !b).unwrap_or(true); let ignore_vcs = ignore && config.no_ignore_vcs.map(|b| !b).unwrap_or(true); // Custom ignore files always work even if the `ignore` option is false, // so we only add if that option is not present. if ignore_dot { walker.add_custom_ignore_filename(IGNORE_FILE); } walker .git_exclude(ignore_vcs) .git_global(ignore_vcs) .git_ignore(ignore_vcs) .hidden(config.hidden.map(|b| !b).unwrap_or(true)) .ignore(ignore_dot) .parents(ignore && config.no_ignore_parent.map(|b| !b).unwrap_or(true)); walker.build_parallel().run(move || { let tx = tx.clone(); Box::new(move |entry| { let entry = match entry { Ok(entry) => entry, Err(error) => { use ignore::Error; if let Error::WithDepth { err: ref error, .. } = error { if let Error::WithPath { ref path, err: ref error, } = **error { error!("{} reading {}", error, path.display()); return Continue; } } error!("{}", error); return Continue; } }; if entry.file_type().map_or(false, |ft| ft.is_file()) { tx.send(entry).unwrap(); } Continue }) }); let rx_iter = rx .into_iter() .par_bridge() .filter_map(|e| LanguageType::from_path(e.path(), config).map(|l| (e, l))); let process = |(entry, language): (DirEntry, LanguageType)| { let result = language.parse(entry.into_path(), config); let mut lock = languages.lock(); let entry = lock.entry(language).or_insert_with(Language::new); match result { Ok(stats) => { let func = config.for_each_fn; if let Some(f) = func { f(language, stats.clone()) }; entry.add_report(stats) } Err((error, path)) => { entry.mark_inaccurate(); error!("Error reading {}:\n{}", path.display(), error); } } }; if let Some(types) = config.types.as_deref() { rx_iter.filter(|(_, l)| types.contains(l)).for_each(process) } else { rx_iter.for_each(process) } } pub(crate) fn get_extension(path: &Path) -> Option<String> { path.extension().map(|e| e.to_string_lossy().to_lowercase()) } pub(crate) fn get_filename(path: &Path) -> Option<String> { path.file_name().map(|e| e.to_string_lossy().to_lowercase()) } #[cfg(test)] mod tests { use std::fs; use tempfile::TempDir; use super::IGNORE_FILE; use crate::{ config::Config, language::{languages::Languages, LanguageType}, }; const FILE_CONTENTS: &[u8] = b"fn main() {}"; const FILE_NAME: &str = "main.rs"; const IGNORE_PATTERN: &str = "*.rs"; const LANGUAGE: &LanguageType = &LanguageType::Rust; #[test] fn ignore_directory_with_extension() { let mut languages = Languages::new(); let tmp_dir = TempDir::new().expect("Couldn't create temp dir"); let path_name = tmp_dir.path().join("directory.rs"); fs::create_dir(path_name).expect("Couldn't create directory.rs within temp"); super::get_all_files( &[tmp_dir.into_path().to_str().unwrap()], &[], &mut languages, &Config::default(), ); assert!(languages.get(LANGUAGE).is_none()); } #[test] fn hidden() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); fs::write(dir.path().join(".hidden.rs"), FILE_CONTENTS).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); config.hidden = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } #[test] fn no_ignore_implies_dot() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); fs::write(dir.path().join(".ignore"), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); config.no_ignore = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } #[test] fn no_ignore_implies_vcs_gitignore() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); git2::Repository::init(dir.path()).expect("Couldn't create git repo."); fs::write(dir.path().join(".gitignore"), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); config.no_ignore = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } #[test] fn no_ignore_parent() { let parent_dir = TempDir::new().expect("Couldn't create temp dir."); let child_dir = parent_dir.path().join("child/"); let mut config = Config::default(); let mut languages = Languages::new(); fs::create_dir_all(&child_dir) .unwrap_or_else(|_| panic!("Couldn't create {:?}", child_dir)); fs::write(parent_dir.path().join(".ignore"), IGNORE_PATTERN) .expect("Couldn't create .gitignore."); fs::write(child_dir.join(FILE_NAME), FILE_CONTENTS).expect("Couldn't create child.rs"); super::get_all_files( &[child_dir.as_path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); config.no_ignore_parent = Some(true); super::get_all_files( &[child_dir.as_path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } #[test] fn no_ignore_dot() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); fs::write(dir.path().join(".ignore"), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); config.no_ignore_dot = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } #[test] fn no_ignore_dot_still_vcs_gitignore() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); git2::Repository::init(dir.path()).expect("Couldn't create git repo."); fs::write(dir.path().join(".gitignore"), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); config.no_ignore_dot = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); } #[test] fn no_ignore_dot_includes_custom_ignore() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); fs::write(dir.path().join(IGNORE_FILE), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); config.no_ignore_dot = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } #[test] fn no_ignore_vcs_gitignore() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); git2::Repository::init(dir.path()).expect("Couldn't create git repo."); fs::write(dir.path().join(".gitignore"), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); config.no_ignore_vcs = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } #[test] fn no_ignore_vcs_gitignore_still_dot() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); fs::write(dir.path().join(".ignore"), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); config.no_ignore_vcs = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); } #[test] fn no_ignore_vcs_gitexclude() { let dir = TempDir::new().expect("Couldn't create temp dir."); let mut config = Config::default(); let mut languages = Languages::new(); git2::Repository::init(dir.path()).expect("Couldn't create git repo."); fs::write(dir.path().join(".git/info/exclude"), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); config.no_ignore_vcs = Some(true); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } #[test] fn custom_ignore() { let dir = TempDir::new().expect("Couldn't create temp dir."); let config = Config::default(); let mut languages = Languages::new(); git2::Repository::init(dir.path()).expect("Couldn't create git repo."); fs::write(dir.path().join(IGNORE_FILE), IGNORE_PATTERN).unwrap(); fs::write(dir.path().join(FILE_NAME), FILE_CONTENTS).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_none()); fs::remove_file(dir.path().join(IGNORE_FILE)).unwrap(); super::get_all_files( &[dir.path().to_str().unwrap()], &[], &mut languages, &config, ); assert!(languages.get(LANGUAGE).is_some()); } } 0707010000003A000081A400000000000000000000000166C8A4FD0000085A000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/src/utils/macros.rs#![allow(unused_macros)] macro_rules! opt_warn { ($option:expr, $message:expr) => { match $option { Some(result) => result, None => { warn!($message); continue; } } }; } macro_rules! rs_warn { ($result:expr, $message: expr) => { match $result { Ok(result) => result, Err(error) => { warn!("{}", error); continue; } } }; } macro_rules! opt_error { ($option:expr, $message:expr) => { match $option { Some(result) => result, None => { error!($message); continue; } } }; } macro_rules! rs_error { ($result:expr) => { match $result { Ok(result) => result, Err(error) => { error!("{}", error); continue; } } }; } macro_rules! opt_ret_warn { ($option:expr, $message:expr) => { match $option { Some(result) => result, None => { warn!($message); return None; } } }; } macro_rules! rs_ret_warn { ($result:expr, $message: expr) => { match $result { Ok(result) => result, Err(error) => { warn!("{}", error); return None; } } }; } macro_rules! opt_ret_error { ($option:expr, $message:expr) => { match $option { Some(result) => result, None => { error!($message); return None; } } }; } macro_rules! rs_ret_error { ($result:expr) => { match $result { Ok(result) => result, Err(error) => { error!("{}", error); return None; } } }; } macro_rules! debug { ($fmt:expr) => (if cfg!(debug_assertions) {println!($fmt)}); ($fmt:expr, $($arg:tt)*) => (if cfg!(debug_assertions) {println!($fmt, $($arg)*)}); } 0707010000003B000081A400000000000000000000000166C8A4FD00000039000000000000000000000000000000000000002B00000000tokei-13.0.0.alpha.5+git0/src/utils/mod.rs#[macro_use] mod macros; pub(crate) mod ext; pub mod fs; 0707010000003C000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000002000000000tokei-13.0.0.alpha.5+git0/tests0707010000003D000081A400000000000000000000000166C8A4FD000009B6000000000000000000000000000000000000002C00000000tokei-13.0.0.alpha.5+git0/tests/accuracy.rsextern crate ignore; extern crate regex; extern crate tokei; use std::fs; use once_cell::sync::Lazy; use regex::Regex; use tokei::{Config, Languages}; static LINES: Lazy<Regex> = Lazy::new(|| Regex::new(r"\d+ lines").unwrap()); static CODE: Lazy<Regex> = Lazy::new(|| Regex::new(r"\d+ code").unwrap()); static COMMENTS: Lazy<Regex> = Lazy::new(|| Regex::new(r"\d+ comments").unwrap()); static BLANKS: Lazy<Regex> = Lazy::new(|| Regex::new(r"\d+ blanks").unwrap()); macro_rules! get_digit { ($regex:expr, $text:expr) => {{ let matched = $regex.find(&$text).expect("Couldn't find category"); matched .as_str() .split_whitespace() .next() .unwrap() .parse::<usize>() .unwrap() }}; } mod config { use tokei::*; /* #[test] fn extension_change() { use std::collections::HashMap; let mut languages = Languages::new(); let config = Config { languages: { let mut map = HashMap::new(); let mut config = LanguageConfig::new(); config.extensions(vec![String::from("cpp")]); map.insert(LanguageType::C, config); Some(map) }, ..Config::default() }; languages.get_statistics(&["tests/data/cpp.cpp"], &[], &config); if languages.len() != 1 { panic!("wrong languages detected: expected just C, found {:?}", languages.into_iter().collect::<Vec<_>>()); } let (name, _) = languages.into_iter().next().unwrap(); assert_eq!(LanguageType::C, name); } */ #[test] fn treating_comments_as_code() { let mut languages = Languages::new(); let config = Config { treat_doc_strings_as_comments: Some(true), ..Config::default() }; languages.get_statistics(&["tests/data/python.py"], &[], &config); if languages.len() != 1 { panic!( "wrong languages detected: expected just Python, found {:?}", languages.into_iter().collect::<Vec<_>>() ); } let (_, language) = languages.into_iter().next().unwrap(); assert_eq!(language.lines(), 15); assert_eq!(language.blanks, 3); assert_eq!(language.comments, 7); assert_eq!(language.code, 5); } } include!(concat!(env!("OUT_DIR"), "/tests.rs")); 0707010000003E000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000002500000000tokei-13.0.0.alpha.5+git0/tests/data0707010000003F000081A400000000000000000000000166C8A4FD00000462000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/Daml.daml-- ! 42 lines 24 code 9 comments 9 blanks {- This code is derived from https://github.com/digital-asset/ex-secure-daml-infra/blob/master/daml/BobTrigger.daml -- Haskell/DAML support nested comments {- including nested block comments -} -} module BobTrigger where -- import DA.Action import DA.Foldable import DA.Next.Map (Map) import Daml.Trigger import Main (--$) :: a -> b -> String a --$ b = "Not a comment" rejectTrigger : Trigger () = Trigger with initialize = \_ -> () updateState = \_ _ () -> () rule = rejectRule registeredTemplates = AllInDar heartbeat = None testNotAComment = 1 --$ 2 == "Not a comment" rejectRule : Party -> ACS -> Time -> Map CommandId [Command] -> () -> TriggerA () rejectRule p acs _ _ _ = do let assets = getContracts @Asset acs let bobAssets = filter (\(_,a) -> a.owner == p) assets let configs = getContracts @DonorConfig acs let Some (_,bobConfig) = find (\(_,c) -> c.owner == p) configs forA_ bobAssets $ \(_cid, c) -> do debug "Ran rejectRule" emitCommands [exerciseCmd _cid Give with newOwner = bobConfig.donateTo] [toAnyContractId _cid] 07070100000040000081A400000000000000000000000166C8A4FD0000014B000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/Dockerfile# 17 lines 7 code 3 comments 7 blanks FROM netbsd:7.0.2 MAINTAINER Somebody version: 2.2 RUN curl -sSf https://static.rust-lang.org/rustup.sh | sh -s -- -y # this part is important VOLUME ["/project"] WORKDIR "/project" RUN sh -c 'echo "Hello World" > /dev/null' RUN cargo install tokei # not counted # now you do your part 07070100000041000081A400000000000000000000000166C8A4FD00000164000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/tests/data/MSBuild.csproj<!-- 12 lines 10 code 1 comments 1 blanks --> <Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp2.0</TargetFramework> <LangVersion>Latest</LangVersion> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.CodeAnalysis" Version="2.3.2" /> </ItemGroup> </Project> 07070100000042000081A400000000000000000000000166C8A4FD00000176000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/Makefile# 24 lines 11 code 5 comments 8 blanks ## ## ## IMPORTANT COMMENT ## ## ## all: hello hello: main.o factorial.o hello.o g++ main.o factorial.o hello.o -o hello # main.o is my favorite main.o: main.cpp g++ -c main.cpp factorial.o: factorial.cpp g++ -c factorial.cpp hello.o: hello.cpp g++ -c hello.cpp clean: rm *o hello #not counted 07070100000043000081A400000000000000000000000166C8A4FD00000182000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/Modelica.mo// 21 lines 13 code 5 comments 3 blanks block Add "Output the sum of the two inputs" extends Interfaces.SI2SO; /* parameter section */ parameter Real k1=+1 "Gain of input signal 1"; parameter Real k2=+1 "Gain of input signal 2"; // equation section equation y = k1*u1 + k2*u2; annotation ( Documentation(info="<html> <p> Some documentation. </p> </html>")); end Add; 07070100000044000081A400000000000000000000000166C8A4FD0000049D000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/NuGet.Config<!-- 24 lines 13 code 8 comments 3 blanks --> <?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- defaultPushSource key works like the 'defaultPushSource' key of NuGet.Config files. --> <!-- This can be used by administrators to prevent accidental publishing of packages to nuget.org. --> <config> <add key="defaultPushSource" value="https://contoso.com/packages/" /> </config> <!-- Default Package Sources; works like the 'packageSources' section of NuGet.Config files. --> <!-- This collection cannot be deleted or modified but can be disabled/enabled by users. --> <packageSources> <add key="Contoso Package Source" value="https://contoso.com/packages/" /> <add key="nuget.org" value="https://api.nuget.org/v3/index.json" /> </packageSources> <!-- Default Package Sources that are disabled by default. --> <!-- Works like the 'disabledPackageSources' section of NuGet.Config files. --> <!-- Sources cannot be modified or deleted either but can be enabled/disabled by users. --> <disabledPackageSources> <add key="nuget.org" value="true" /> </disabledPackageSources> </configuration> 07070100000045000081A400000000000000000000000166C8A4FD00000322000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/PKGBUILD# 24 lines 19 code 3 comments 2 blanks # Maintainer: Andy 'Blocktronics' Herbert <blocktronics.org> # Aur Maintainer: Wanesty <github.com/Wanesty/aurpkg> pkgname=moebius-bin pkgver=1.0.29 pkgrel=1 epoch=1 pkgdesc="Modern ANSI & ASCII Art Editor" arch=('x86_64') url="https://github.com/blocktronics/moebius" license=('Apache') depends=('gtk3' 'libnotify' 'libxss' 'libxtst' 'xdg-utils' 'libappindicator-gtk3') makedepends=('libarchive') conflicts=('moebius') source=("https://github.com/blocktronics/moebius/releases/download/$pkgver/Moebius.rpm") sha256sums=(69aaa1e42e287ed78c8e73971dae3df23ae4fa00e3416ea0fc262b7d147fefec) noextract=("Moebius.rpm") package() { bsdtar -C "${pkgdir}" -xvf "$srcdir/Moebius.rpm" mkdir "$pkgdir/usr/bin" ln -s "/opt/Moebius/moebius" "$pkgdir/usr/bin/moebius" }07070100000046000081A400000000000000000000000166C8A4FD00000090000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/Rakefile# 10 lines 4 code 2 comments 4 blanks # this is a rakefile task default: %w[test] task :test do # not counted ruby "test/unittest.rb" end 07070100000047000081A400000000000000000000000166C8A4FD000000B5000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/SConstruct#!python # 10 lines 3 code 3 comments 4 blanks # this is a comment Program('cpp.cpp') # this is a line-ending comment env = Environment(CCFLAGS='-O3') env.Append(CCFLAGS='-O3') 07070100000048000081A400000000000000000000000166C8A4FD00000559000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/Snakefile# 67 lines 50 code 4 comments 13 blanks """ A sample Snakefile for testing line counting """ SAMPLES = ["A", "B"] # This is a # multiline # comment rule all: input: "plots/quals.svg" '''Sometimes even some comments in single quote fences.''' rule bwa_map: input: "data/genome.fa", # Inline comments are also supported "data/samples/{sample}.fastq" output: "mapped_reads/{sample}.bam" shell: "bwa mem {input} | samtools view -Sb - > {output}" rule samtools_sort: input: "mapped_reads/{sample}.bam" output: "sorted_reads/{sample}.bam" shell: "samtools sort -T sorted_reads/{wildcards.sample} " "-O bam {input} > {output}" rule samtools_index: input: "sorted_reads/{sample}.bam" output: "sorted_reads/{sample}.bam.bai" shell: "samtools index {input}" rule bcftools_call: input: fa="data/genome.fa", bam=expand("sorted_reads/{sample}.bam", sample=SAMPLES), bai=expand("sorted_reads/{sample}.bam.bai", sample=SAMPLES) output: "calls/all.vcf" shell: "bcftools mpileup -f {input.fa} {input.bam} | " "bcftools call -mv - > {output}" rule plot_quals: input: "calls/all.vcf" output: "plots/quals.svg" script: "scripts/plot-quals.py" 07070100000049000081A400000000000000000000000166C8A4FD000003B2000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/Tera.tera{# 42 lines 26 code 11 comments 5 blanks #} <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width" /> <title></title> link <style> body { background-color: pink; } </style>{# #} {# comment #} </head> <body> body </body> <!-- Normal Comment--> <nav class="navbar navbar-default navbar-fixed-top navbar-custom"> <div id="modalSearch" class="modal fade" role="dialog"> </div> </nav> <!-- document.write("Multi-line and Code comment!");{# comment #} //--> <!--[if IE 8]> IE Special comment <![endif]--> <script> let x = 5; </script> {# multi-line-comment #} {% if error %} <div class="flash {{ error.category }}">{{ error.content }}</div>{# comment #} {% endif %} </html> 0707010000004A000081A400000000000000000000000166C8A4FD0000010C000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/abnf.abnf; 11 lines 3 code 5 comments 3 blanks ; comment line 0 ; comment line 1 ALPHA = %x41-5A / %x61-7A ; A-Z / a-z BIT = "0" / "1" CHAR = %x01-7F ; any 7-bit US-ASCII character, ; excluding NUL 0707010000004B000081A400000000000000000000000166C8A4FD0000012E000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/alloy.als// 18 lines 10 code 3 comments 5 blanks sig Node { edge: set Node } ------------------------------------------------------------------------ pred self_loop[n: Node] { n in n.edge } pred all_self_loop { all n: Node | self_loop[n] } /* Comments started by /* don't nest */ run all_self_loop 0707010000004C000081A400000000000000000000000166C8A4FD0000016C000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/arduino.ino// 23 lines 13 code 6 comments 4 blanks int led = 13; void setup() { // setup println() Serial.begin(155200); // Init LED pin pinMode(led, OUTPUT); } /** * Blink the LED */ void loop() { Serial.println("LED ON!"); digitalWrite(led, HIGH); delay(1000); Serial.println("LED OFF!"); digitalWrite(led, LOW); delay(1000); } 0707010000004D000081A400000000000000000000000166C8A4FD0000008A000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/arturo.art; 8 lines 3 code 3 comments 2 blanks ; this is a comment ; this is another comment a1: 2 a2: 3.14 ; pi a3: 213213 ; another number 0707010000004E000081A400000000000000000000000166C8A4FD000000EA000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/asciidoc.adoc// 20 lines 5 code 8 comments 7 blanks = AsciiDoc title A simple paragraph. // single line comment That should end before a paragraph. //// multi = Line comment //// == Nested title Nested titles and paragraphs are fine, too. 0707010000004F000081A400000000000000000000000166C8A4FD00000313000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/asn1.asn1-- 34 lines 16 code 11 comments 7 blanks PKCS-12 { iso(1) member-body(2) us(840) rsadsi(113549) pkcs(1) pkcs-12(12) modules(0) pkcs-12(1) } -- PKCS #12 v1.1 ASN.1 Module -- Revised October 27, 2012 -- This module has been checked for conformance with the ASN.1 standard -- by the OSS ASN.1 Tools DEFINITIONS IMPLICIT TAGS ::= BEGIN PFX ::= SEQUENCE { version INTEGER {v3(3)}(v3,...), authSafe OCTET STRING, macData MacData /* " " */ OPTIONAL } /* * Multi line * */ MacData ::= SEQUENCE { mac OBJECT IDENTIFIER, macSalt OCTET STRING, iterations INTEGER DEFAULT 1 -- Note: The default is for historical reasons and its use is -- deprecated. } END 07070100000050000081A400000000000000000000000166C8A4FD000003AE000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/ats.dats//! 42 lines 25 code 9 comments 8 blanks (************* Reference: https://github.com/ats-lang/ats-lang.github.io/blob/master/DOCUMENT/ATS2TUTORIAL/CODE/chap_stream_vt.dats **************) #include "share/atspre_staload.hats" /* Lazy-evaluated integer iterator */ fun from (n: int): stream_vt(int) = $ldelay(stream_vt_cons(n, from(n + 1))) // Lazy-evaluated prime finder fun sieve (ns: stream_vt(int)) : stream_vt(int) = $ldelay( let val ns_con = !ns val- @stream_vt_cons(n0, ns1) = ns_con val n0_val = n0 val ns1_val = ns1 val () = (ns1 := sieve(stream_vt_filter_cloptr<int>(ns1_val, lam x => x mod n0_val > 0))) prval () = fold@(ns_con) in ns_con end , ~ns ) // Test run for finding the 1000-th prime number val thePrimes = sieve(from(2)) val p1000 = (steam_vt_drop_exn(thePrimes, 1000)).head() val () = println!("p1000 = ", p1000) implement main0 () = {} (* End of file *) 07070100000051000081A400000000000000000000000166C8A4FD00000055000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/awk.awk#!/bin/awk -f # 5 lines 1 code 3 comments 1 blanks # This is a comment { print $0 } 07070100000052000081A400000000000000000000000166C8A4FD00000143000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/bazel.bzl# 18 lines 13 code 3 comments 2 blanks # build hello-greet cc_library( name = "hello-greet", srcs = ["hello-greet.cc"], hdrs = ["hello-greet.h"], ) # build hello-world cc_binary( name = "hello-world", srcs = ["hello-world.cc"], deps = [ ":hello-greet", "//lib:hello-time", ], )07070100000053000081A400000000000000000000000166C8A4FD00000272000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/bean.bean; 27 lines 13 code 6 comments 8 blanks option "operating_currency" "EUR" 2002-01-01 commodity EUR name: "Euro" asset-class: "cash" ; open accounts initially 2020-09-01 open Equity:Opening-Balances 2020-09-01 open Assets:Cash EUR 2020-09-01 open Expenses:Food EUR ; put initial money on account 2020-09-01 pad Assets:Cash Equity:Opening-Balances ; verifying starting balance 2020-09-02 balance Assets:Cash 81.7 EUR ; transferring money 2020-09-03 * "transfer of money" Assets:Cash -17.7 EUR Expenses:Food ; validating changed balance 2020-09-04 balance Assets:Cash 64 EUR 07070100000054000081A400000000000000000000000166C8A4FD0000053B000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/bicep.bicep//! 50 lines 35 code 8 comments 7 blanks /* Bicep is a declarative language, which means the elements can appear in any order. Unlike imperative languages, the order of elements doesn't affect how deployment is processed. This means you can define resources, variables, and parameters in any order you like. */ metadata description = 'Creates a storage account and a web app' @description('The prefix to use for the storage account name.') @minLength(3) @maxLength(11) param storagePrefix string param storageSKU string = 'Standard_LRS' param location string = resourceGroup().location var uniqueStorageName = '${storagePrefix}${uniqueString(resourceGroup().id)}' var objectExmaple = { name: 'John' age: 30 address: ''' 1 Microsoft Way Redmond, WA 98052 ''' } // Create a storage account resource stg 'Microsoft.Storage/storageAccounts@2022-09-01' = { name: uniqueStorageName location: location sku: { name: storageSKU } kind: 'StorageV2' properties: { supportsHttpsTrafficOnly: true } } // Use a module to deploy a web app // Modules are a way to encapsulate and reuse resources in Bicep module webModule './webApp.bicep' = { name: 'webDeploy' params: { skuName: 'S1' location: location personalInfo: objectExmaple } } 07070100000055000081A400000000000000000000000166C8A4FD0000020C000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/bitbake.bb# 23 lines 13 code 5 comments 5 blanks # # This file was derived from the 'Hello World!' example recipe in the # Yocto Project Development Manual. # SUMMARY = "Simple helloworld application" SECTION = "examples" LICENSE = "MIT" LIC_FILES_CHKSUM = "file://${COMMON_LICENSE_DIR}/MIT;md5=0835ade698e0bcf8506ecda2f7b4f302" SRC_URI = "file://helloworld.c" S = "${WORKDIR}" do_compile() { ${CC} helloworld.c -o helloworld } do_install() { install -d ${D}${bindir} install -m 0755 helloworld ${D}${bindir} } 07070100000056000081A400000000000000000000000166C8A4FD0000023F000000000000000000000000000000000000003600000000tokei-13.0.0.alpha.5+git0/tests/data/brightscript.brs' 26 lines 10 code 13 comments 3 blanks ' /** ' * @member difference ' * @memberof module:rodash ' * @instance ' * @description Return a new array of items from the first which are not in the second. ' * @param {Array} first ' * @param {Array} second ' * @example REM * difference = _.difference([1,2], [2]) REM * ' => [1] REM * REM */ Function rodash_difference_(first, second) result = [] for each f in first result.push(f) 'Push array for each s in second if m.equal(s,f) then result.pop() end for end for return result End Function07070100000057000081A400000000000000000000000166C8A4FD00000369000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/tests/data/c.c// 50 lines 33 code 8 comments 9 blanks /* /* we can't nest block comments in c, but we can start one */ int main(void) { char *start = "/*"; int x = 1; x += 2; // end of line comment */ } void foo() { char *esc = "\"/*escaped quotes in a string and block comment*/\""; func1(); func2(); char *next_line = "*/ /*string on new line\ continued to another line\ bar();\ */"; char *next_line2 = "line1\ // not a real comment\ line3*/"; /* Block comment // line comment in a block comment end block comment*/ char *late_start = // " "wow\ that's pretty neat"; char *late_start2 = /* " */ "*/ still just a string"; // but this is a line comment } void foobar() { int a = 4; // /* int b = 5; int c = 6; // */ } /*\ / comment \*/ struct Point { int x; int y; int z; }; 07070100000058000081A400000000000000000000000166C8A4FD000003C5000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/cangjie.cj/* 50 lines 34 code 8 comments 8 blanks */ /* /* we can nest block*/ comments in cangjie */ main(): Unit { let start: String = "/*" var x: Int64 = 1 x += 2 // end of line comment */ } func foo(): Unit { let esc: String = "\"/*escaped quotes in a string and block comment*/\""; let next_line: String = """ */ /*string on new line continued to another line bar(); */" """ /* Block comment // line comment in a block comment end block comment*/ let late_start: String = // " ##"wow\ that's pretty neat"## let late_start2: String = /* " */ "*/ still just a string" // but this is a line comment } func foobar(): Unit { let a: Int64 = 4 // /* let b: Int64 = 5 let c: Int64 = 6 // */ } /* \ / comment \*/ struct Point { let x: Int64 let y: Int64 let z: Int64 public init(x: Int64, y: Int64, z: Int64) { this.x = x this.y = y this.z = z } } 07070100000059000081A400000000000000000000000166C8A4FD0000019A000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/chapel.chpl// chapel 24 lines 9 code 9 comments 6 blanks // Tidy line comment /* Tidy block comment. */ // Cheeky line comments /* // */ /* Cheeky // block comments */ // Caculate a factorial proc factorial(n: int): int { var x = 1; // this will eventually be returned for i in 1..n { x *= i; } return x; } writeln("// this isn't a comment"); writeln('/* this is also not a comment */'); 0707010000005A000081A400000000000000000000000166C8A4FD0000037A000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/cil.cil; 20 lines 15 code 3 comments 2 blanks ;============= etcd_t ============== (allow etcd_t proc_sysctl_t (dir (search))) (allow etcd_t proc_sysctl_t (file (read open))) (allow etcd_t procfs_t (dir (search getattr))) (allow etcd_t procfs_t (lnk_file (read))) (allow etcd_t self (dir (read open search))) (allow etcd_t self (fifo_file (write read))) ;============= kernel_t ============== (allow kernel_t bin_t (dir (search))) (allow kernel_t bin_t (file (read execute_no_trans open map execute))) (allow kernel_t debugfs_t (dir (search))) (allow kernel_t device_t (blk_file (create setattr))) (allow kernel_t device_t (chr_file (write create setattr))) (allow kernel_t self (capability (dac_override mknod))) (allow kernel_t self (dir (write add_name search))) (allow kernel_t self (file (write create open))) (filecon "/.extra(/.*)?" any (system_u object_r extra_t (systemLow systemLow))) 0707010000005B000081A400000000000000000000000166C8A4FD000002A1000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/circom.circom// 34 lines 23 code 7 comments 4 blanks pragma circom 2.0.8; /* * Sum an array of non-zero values. */ function sum(values, size) { var sum = 0; for (var i = 0; i < size; i++) { assert(values[i] != 0); sum += values[i]; } log("sum = ", sum); return sum; } /* * Ensure x is a solution to x^5 - 2x^4 + 5x - 4 = 0. */ template Polynomial() { signal input x; signal x2; signal x4; signal x5; signal output y; x2 <== x * x; x4 <== x2 * x2; x5 <== x4 * x; y <== x5 - 2 * x4 + 5 * x - 4; // y = x^5 - 2 * x^4 + 5x - 4. y === 0; // Ensure that y = 0. } component main = Polynomial(); 0707010000005C000081A400000000000000000000000166C8A4FD0000011F000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/clojure.clj; 19 lines 13 code 3 comments 3 blanks (ns clojure) ; Below is a function (defn a-fn "Docstring with a column ;" [a b] (+ 1 1)) (defn a-fn2 ;"Not a doc" "Doc doc again" [a b] ; a and b right? (let [multiline "I'm a multline ; string "] (str multline a b))) 0707010000005D000081A400000000000000000000000166C8A4FD0000011F000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/clojurec.cljc; 19 lines 13 code 3 comments 3 blanks (ns clojure) ; Below is a function (defn a-fn "Docstring with a column ;" [a b] (+ 1 1)) (defn a-fn2 ;"Not a doc" "Doc doc again" [a b] ; a and b right? (let [multiline "I'm a multline ; string "] (str multline a b))) 0707010000005E000081A400000000000000000000000166C8A4FD0000011F000000000000000000000000000000000000003800000000tokei-13.0.0.alpha.5+git0/tests/data/clojurescript.cljs; 19 lines 13 code 3 comments 3 blanks (ns clojure) ; Below is a function (defn a-fn "Docstring with a column ;" [a b] (+ 1 1)) (defn a-fn2 ;"Not a doc" "Doc doc again" [a b] ; a and b right? (let [multiline "I'm a multline ; string "] (str multline a b))) 0707010000005F000081A400000000000000000000000166C8A4FD000003A5000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/cmake.cmake# 25 lines 16 code 3 comments 6 blanks SET(_POSSIBLE_XYZ_INCLUDE include include/xyz) SET(_POSSIBLE_XYZ_EXECUTABLE xyz) SET(_POSSIBLE_XYZ_LIBRARY XYZ) # this is a comment IF(XYZ_FIND_VERSION_MAJOR AND XYZ_FIND_VERSION_MINOR) SET(_POSSIBLE_SUFFIXES "${XYZ_FIND_VERSION_MAJOR}${XYZ_FIND_VERSION_MINOR}" "${XYZ_FIND_VERSION_MAJOR}.${XYZ_FIND_VERSION_MINOR}" "-${XYZ_FIND_VERSION_MAJOR}.${XYZ_FIND_VERSION_MINOR}") # not counted ELSE(XYZ_FIND_VERSION_MAJOR AND XYZ_FIND_VERSION_MINOR) SET(_POSSIBLE_SUFFIXES "67" "92" "352.9" "0.0.8z") ENDIF(XYZ_FIND_VERSION_MAJOR AND XYZ_FIND_VERSION_MINOR) FOREACH(_SUFFIX ${_POSSIBLE_SUFFIXES}) LIST(APPEND _POSSIBLE_XYZ_INCLUDE "include/XYZ${_SUFFIX}") LIST(APPEND _POSSIBLE_XYZ_EXECUTABLE "XYZ${_SUFFIX}") LIST(APPEND _POSSIBLE_XYZ_LIBRARY "XYZ${_SUFFIX}") ENDFOREACH(_SUFFIX) # not counted FIND_PROGRAM(XYZ_EXECUTABLE NAMES ${_POSSIBLE_XYZ_EXECUTABLE} ) # this is also a comment 07070100000060000081A400000000000000000000000166C8A4FD000002F2000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/codeql.ql//! 40 lines 17 code 15 comments 8 blanks /** * @name fu * @description bar * * Rerum similique consequatur non dolor sit. Autem doloribus sed in sint * ratione sit voluptates at. Nihil ut fugiat ab ut aliquid consequatur sunt * ullam. Adipisci voluptatem hic dicta. */ // asdf import cpp private import test.foo.bar.baz /** * Another comment. */ class C extends Expr { C () { // single comment not this.test() and not this.what() } private predicate what() { /* TODO */ this.isAbstract() } predicate test() { this = "what" } } from Function f where f.getName() = "function" and /* inline comment */ f.getArgument(0).asExpr() instanceof FooBar select f, "function" 07070100000061000081A400000000000000000000000166C8A4FD00000057000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/cogent.cogent-- 7 lines 2 code 2 comments 3 blanks type A -- uncounted comment -- comment type B 07070100000062000081A400000000000000000000000166C8A4FD000002C7000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/cpp.cpp/* 46 lines 37 code 3 comments 6 blanks */ #include <stdio.h> // bubble_sort_function void bubble_sort(int a[10], int n) { int t; int j = n; int s = 1; while (s > 0) { s = 0; int i = 1; while (i < j) { if (a[i] < a[i - 1]) { t = a[i]; a[i] = a[i - 1]; a[i - 1] = t; s = 1; } i++; } j--; } } int main() { int a[] = {4, 65, 2, -31, 0, 99, 2, 83, 782, 1}; int n = 10; int i = 0; printf(R"(Before sorting:\n\n" )"); // Single line comment while (i < n) { printf("%d ", a[i]); i++; } bubble_sort(a, n); printf("\n\nAfter sorting:\n\n"); i = 0; while (i < n) { printf("%d ", a[i]); i++; } } 07070100000063000081A400000000000000000000000166C8A4FD000000D9000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/crystal.cr# 20 lines 14 code 2 comments 4 blanks x = 3 if x < 2 p = "Smaller" else p = "Bigger" end multiline_string = "first line second line" heredoc = <<-SOME hello SOME # testing. while x > 2 && x < 10 x += 1 end 07070100000064000081A400000000000000000000000166C8A4FD00000170000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/csharp.cs// 26 lines 14 code 9 comments 3 blanks namespace Ns { /* multi-line comment */ public class Cls { private const string BasePath = @"a:\"; [Fact] public void MyTest() { // Arrange. Foo(); // Act. Bar(); // Assert. Baz(); } } } 07070100000065000081A400000000000000000000000166C8A4FD000000A3000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/cuda.cu/* 7 lines 4 code 2 comments 1 blanks */ // add vector __host__ void add(const int* a, const int* b, int* c) { int i = threadIdx.x; c[i] = a[i] + b[i]; } 07070100000066000081A400000000000000000000000166C8A4FD000000EC000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/cue.cue// 12 lines 8 code 2 comments 2 blanks // A documentation comment map: { normal: "normal string" // inline comment (not counted) content: """ Multi-line string """ raw: #"A newline is \#n written as "\n"."# byte: '\U0001F604' } 07070100000067000081A400000000000000000000000166C8A4FD000001C3000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/cython.pyx# 29 lines, 21 code, 3 comments, 5 blanks def add(x, y): ''' Hello World # Real Second line Second line ''' string = "Hello World #\ " y += len(string) # Add the two numbers. x + y cdef add2(x, y): """ Hello World # Real Second line Second line Note that docstring lines are counted as code """ string = "Hello World" y += len(string) # Add the two numbers. x + y 07070100000068000081A400000000000000000000000166C8A4FD00000098000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/tests/data/d.d/* 8 lines 5 code 1 comments 2 blanks */ void main() { auto x = 5; /+ a /+ nested +/ comment /* +/ writefln("hello"); auto y = 4; // */ } 07070100000069000081A400000000000000000000000166C8A4FD000000D2000000000000000000000000000000000000002B00000000tokei-13.0.0.alpha.5+git0/tests/data/d2.d2# 15 lines 4 code 6 comments 5 blanks # Comments start with a hash character and continue until the next newline or EOF. x -> y x -> y # I am at the end '#x' -> "#y" """ This is a block comment """ y -> z 0707010000006A000081A400000000000000000000000166C8A4FD000000E6000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/dhall.dhall-- 16 lines 9 code 5 comments 2 blanks {- A comment within the interior of a multi-line literal counts as part of the literal -} '' -- Hello {- world -} '' { some = "thing" , keys = ["can" , "have", -- wait for it "lists"] } 0707010000006B000081A400000000000000000000000166C8A4FD00000149000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/dreammaker.dm// 17 lines 7 code 6 comments 4 blanks /* * /* Hello! */ */ /mob // I can rely on this file to exist on disk. var/some_file = './/dreammaker.dm' /mob/Login() // Not counted. /* */ world << "// Say hello to [src]!" src << browse({" /*<a href="https://google.com">Link</a>*/ "}, "window=google") 0707010000006C000081A400000000000000000000000166C8A4FD0000015A000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/dust.dust{! 10 lines 2 code 5 comments 3 blanks !} {! All Dust comments are multiline comments. And there's no quoting comment openers and closers. Instead there are escape sequences for producing literal brackets in template output: {~lb} outputs a left-bracket.!} <h1>Hello world!</h1>{! More comments !} <h2>~{lb}Goodbye, world~{rb}</h2> 0707010000006D000081A400000000000000000000000166C8A4FD000000D7000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/ebuild.ebuild# 16 lines 9 code 2 comments 5 blanks # test comment EAPI=8 DESCRIPTION="ebuild file" HOMEPAGE="https://foo.example.org/" SRC_URI="ftp://foo.example.org/${P}.tar.gz" LICENSE="MIT" SLOT="0" src_compile() { : } 0707010000006E000081A400000000000000000000000166C8A4FD00000208000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/edgeql.edgeql# 28 lines 21 code 3 comments 4 blanks select User { name, friends: { name }, has_i := .friends.name ilike '%i%', has_o := .friends.name ilike '%o%', } filter .has_i or .has_o; select <User>{} ?? User {name}; # update the user with the name 'Alice Smith' with module example update User filter .name = 'Alice Smith' set { name := 'Alice J. Smith' }; # update all users whose name is 'Bob' with module example update User filter .name like 'Bob%' set { name := User.name ++ '*' }; 0707010000006F000081A400000000000000000000000166C8A4FD0000009D000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/edn.edn; 11 lines 6 code 2 comments 3 blanks ; Just some random data {:a [ 1] :b 1 ; this doesn't count as a comment :c {1 1 2 2} :d [1 2 3]} 07070100000070000081A400000000000000000000000166C8A4FD000000F0000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/elvish.elv# 16 lines, 9 code, 5 blanks, 2 comments echo "This is a multiline string # with a hash in it." echo 'This is a single-quoted string.' # This is a comment. use re edit:after-readline = [ [line]{ print "\e]2;"$line"\a" > /dev/tty } ] 07070100000071000081A400000000000000000000000166C8A4FD0000011D000000000000000000000000000000000000003700000000tokei-13.0.0.alpha.5+git0/tests/data/emacs_dev_env.ede;; 16 lines 6 code 7 comments 3 blanks ;; This is an EDE Project file ;; Object ede-proj-project ;; EDE project file. (ede-proj-project "ede-proj-project" :name "my-proj" :version "1.0.0" :file "Project.ede" :targets (list )) ;; Local Variables: ;; mode: emacs-lisp ;; End: 07070100000072000081A400000000000000000000000166C8A4FD000001FC000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/emacs_lisp.el;; 21 lines 11 code 6 comments 4 blanks ; This is a comment line ;; This too! ;;; This 3! ;;;; This 4! (setq some-global-var nil) ;Comment ;;;###autoload (defun some-fn () "Some function." (interactive) (message "I am some function")) (defun fundamental-mode () "Major mode not specialized for anything in particular. Other major modes are defined by comparison with this one." (interactive) (kill-all-local-variables) (run-mode-hooks)) 07070100000073000081A400000000000000000000000166C8A4FD00000198000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/tests/data/emojicode.🍇💭 24 lines 10 code 10 comments 4 blanks 📘 This package is neat. 📘 💭🔜 Comment! 💭🔜 nested? 🔚💭 📗 Simple docstring with a quote 🔤 📗 🐇👨🚀🍇 💭 More quotes! 🔤 🐇❗👋 name🔡 🍇 😀 🍪 🔤Hello there, 🔤 name 🔤! ❌🔤 💭 no comment here🔤 🍪❗ 🍉 🍉 🏁 🍇 👋🐇👨🚀 🔤Karen🔤❗ 🍉 07070100000074000081A400000000000000000000000166C8A4FD000001EF000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/esdl.esdl# 20 lines 13 code 4 comments 3 blanks # no module block type default::Movie { required property title -> str; # the year of release property year -> int64; required link director -> default::Person; required multi link actors -> default::Person; } type default::Person { required property first_name -> str; required property last_name -> str; } abstract link friends_base { # declare a specific title for the link annotation title := 'Close contacts'; } 07070100000075000081A400000000000000000000000166C8A4FD00000D0B000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/example.umpl! 68 lines 58 code 2 comments 8 blanks create yum with 5 create num with ((plus 7 6 6 yum))> (num)> ((plus 1 num))> ! prints 17, the greater than signifies that this should be the printed, the bang symbol signifies a comment, numbers must be in hexadecimal but will be printed in decimal potato 😂3 ⧼ ! to create a function we use the potato keyword, functions must be nameed with a single emoji, we put the number of args and then ⧼⧽ is where the code goes loop ⧼ (` `)> if {$3} ⧼ break ⧽ else ⧼ continue ⧽ ⧽ potato 😂 1 ⧼ ((minus 1 10))> ! prints -15 ⧽ create final with ((add $1 $2))< ! ! we use the create keyword to create a variable and the with keyword to assign a value to the variable, to refrence the args from a function use $1 for the first arg and so on ! adds both arg1 and arg2, the less than signifies that this should not be the printed and sets it to the final variable return: ! we use (:) colon whe returning nothing ⧽ ((new 😂 10 1 0x1A))> ! we use the new keyword to call a function followed by function names, prints 32, when the first digit of number is a letre prefix with 0x list it with [((not true))> 0] ! creates a list with the values 1,2 (in hex), list can only have two elements and you cant declare recursive lists like: [0 [1 1]], but if you have an identiifer (d) that points to a list you can do: [9 d] ((set-with it.first 2))<! sets the first element of the it list to 2, we can also use something like addwith mulitply with which will add or multiple by the variable to/by the value ((set-with it.second 4))< ! sets the second element of the it list to 4 and print its create bool with true create other-bool with ((not bool))< ! creates a variable called bool and sets it to true, then creates a variable called other-bool and sets it to the opposite of bool, when we call a function in a variable defenition we must use an expression to call the function (other-bool)> ! prints false ((set-with other-bool true))< ! we set other-bool to true if {other-bool} ⧼ ! the {} must evalte to a boolean, we can also use eq, ne lt, le etc (`hello`)> ! the bactick (`) is used to encapsulate a string ⧽ else ⧼ (`by`)> ⧽ if {true} ⧼ ! there is now else, use nested if elses, condotins must be in {} and we can use nested () within the ((minus 1 10))> ! prints -15 ⧽ else ⧼ ((plus 1 10))> ! prints 17 ⧽ loop ⧼ potato 😂 1 ⧼ ((minus 1 10))> ! prints -15 ⧽ create inputs with ((input `continue?`))< if {((eq inputs `y`))<} ⧼ ! there is now else, use nested if elses, condotins must be in {} and we can use nested () within the potato 😂 1 ⧼ ((minus 1 10))> ! prints -15 ⧽ continue ⧽ else ⧼ potato 😂 1 ⧼ ((minus 1 10))> ! prints -15 ⧽ break ! what the if/esle do can be nothing if you dont pu anything in the parenthesis ⧽ ((inputs `continue?`))< ⧽ ((new 😂 10 190 0x1A))> ! we use the new keyword to call a function followed by function names, prints 32, when the first digit of number is a letre prefix with 0x ((set-with bool (input `ads`)))> create inputs with ((input `continue?`))< 07070100000076000081A400000000000000000000000166C8A4FD00000120000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/factor.factor! 14 lines, 5 code, 6 comments, 3 blanks /* we can use some dependencies */ USING: math multiline sequences ; ! this is a vocabulary IN: my-vocab ! this comment describes this function : add ( x y -- z ) "Hello World !\ " length /* Add the three numbers. */ + + ; 07070100000077000081A400000000000000000000000166C8A4FD000001DA000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/fennel.fnl;; 18 lines 8 code 5 comments 5 blanks ; this is a ; single comment ;;;; this is also a single comment ;;;;;; ; "this is a comment too!" (local variable "I ;am a ;variable!") ; (print "\"I am commented out!\"") (print "\"Hello world!\"") ; this is an ; end of line comment (print "This is not a comment: ;") (print "This is a multiline string") (fn somefn [x] (print "I am some function.") (print "My parameter is " (string.format "\"%s\"" x))) 07070100000078000081A400000000000000000000000166C8A4FD0000024C000000000000000000000000000000000000003500000000tokei-13.0.0.alpha.5+git0/tests/data/flatbuffers.fbs// 34 lines 21 code 6 comments 7 blanks include "another_schema.fbs"; namespace Example; // one line comment enum PhoneType: byte { MOBILE, HOME, WORK } /* block comment another line end */ table PhoneNumber { number: string; type: PhoneType; } /// documentation comment table Person { name: string; id: int32; email: string; phones: [PhoneNumber]; // a stray quote " } table AddressBook { people: /* a block comment inside code */ [Person]; } root_type AddressBook; /* block /* comments cannot be nested (except the start comment) */ 07070100000079000081A400000000000000000000000166C8A4FD00000BAE000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/forgecfg.cfg# 79 lines 20 code 40 comments 19 blanks # Configuration file ~CONFIG_VERSION: 0.4.0 ########################################################################################################## # advanced #--------------------------------------------------------------------------------------------------------# # Advanced config options to change the way JEI functions. ########################################################################################################## advanced { # Move the JEI search bar to the bottom center of the screen. [default: false] B:centerSearchBarEnabled=true B:debugModeEnabled=false # Choose if JEI should give ingredients direct to the inventory (inventory) or pick them up with the mouse (mouse_pickup). # [Default: mouse_pickup] # [Valid: [inventory, mouse_pickup]] S:giveMode=inventory # The maximum width of the ingredient list. [range: 4 ~ 100, default: 100] I:maxColumns=100 # The maximum height of the recipe GUI. [range: 175 ~ 5000, default: 350] I:maxRecipeGuiHeight=350 # How the mod name should be formatted in the tooltip for JEI GUIs. Leave blank to disable. [Default: blue italic] [Valid: [black, dark_blue, dark_green, dark_aqua, dark_red, dark_purple, gold, gray, dark_gray, blue, green, aqua, red, light_purple, yellow, white, obfuscated, bold, strikethrough, underline, italic]] S:modNameFormat=blue italic # Enable JEI memory usage optimizations. [default: true] B:optimizeMemoryUsage=true } ########################################################################################################## # search #--------------------------------------------------------------------------------------------------------# # Options relating to the search bar. ########################################################################################################## search { # Search mode for Colors (prefix: ^) # [Default: disabled] # [Valid: [enabled, require_prefix, disabled]] S:colorSearchMode=DISABLED # Search mode for Creative Tab Names (prefix: %) # [Default: disabled] # [Valid: [enabled, require_prefix, disabled]] S:creativeTabSearchMode=DISABLED # Search mode for Mod Names (prefix: @) # [Default: require_prefix] # [Valid: [enabled, require_prefix, disabled]] S:modNameSearchMode=require_prefix # Search mode for Ore Dictionary Names (prefix: $) # [Default: disabled] # [Valid: [enabled, require_prefix, disabled]] S:oreDictSearchMode=require_prefix # Search mode for resources ids (prefix: &) # [Default: disabled] # [Valid: [enabled, require_prefix, disabled]] S:resourceIdSearchMode=enabled # Search mode for Tooltips (prefix: #) # [Default: enabled] # [Valid: [enabled, require_prefix, disabled]] S:tooltipSearchMode=enabled } searchadvancedtooltips { # config.jei.searchAdvancedTooltips.search.comment [default: false] B:search=false } 0707010000007A000081A400000000000000000000000166C8A4FD0000008E000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/fsharp.fs(* 15 lines 6 code 5 comments 4 blanks *) // Comment let foo = (* Comment *) 5 let bar = "(* Code *)" let baz = @"a:\" // Comment 0707010000007B000081A400000000000000000000000166C8A4FD000000D2000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/fstar.fst(* 11 lines 3 code 5 comments 3 blanks *) module Hello (* multi line comment *) open FStar.IO // uncounted comment // single line comment let main = print_string "Hello, F*!\n" (* uncounted comment *) 0707010000007C000081A400000000000000000000000166C8A4FD000000CC000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/ftl.ftl<#-- 10 lines 5 code 3 comments 2 blanks --> <#ftl output_format="plainText"/> <#-- Define the print macro --> <#macro print text> ${text} </#macro> <#-- Print "Hello world" --> <@print "Hello world"/> 0707010000007D000081A400000000000000000000000166C8A4FD0000007D000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/futhark.fut-- 8 lines 2 code 3 comments 3 blanks -- this is a test file -- add two let f (x: i32) = x + 2 let main = f -- eta expand 0707010000007E000081A400000000000000000000000166C8A4FD000004D0000000000000000000000000000000000000002B00000000tokei-13.0.0.alpha.5+git0/tests/data/gas.S// 67 lines 46 code 10 comments 11 blanks #include "config.h" /* BIG FAT WARNING GOES HERE */ #define dbg(char) \ mov \char, %ax ;\ out %ax, $0xe9 ;\ #endif .align 16 .code16 .section .resettext, "xa", @progbits reset_vector: cli jmp switch_modes .section .text switch_modes: /* * The developer manual builds up the GDT, but since it should get * cached by the CPU, we can just have it in the flash. */ mov %cs, %ax mov %ax, %ds /* Enable protected mode (PE) */ mov %cr0, %eax or $1, %al mov %eax, %cr0 ljmpl $0x8,$protected_mode .code32 protected_mode: mov $0x10, %ax mov %ax, %ds mov %ax, %es mov %ax, %fs mov %ax, %gs mov %ax, %ss gdt_desc: .word egdt - gdt - 1 .long gdt .align 8 gdt: // 0 segment .long 0, 0 // code (0x8) .word 0xffff // limit 15:0 .word 0x0 // base 15:0 .byte 0x0 // base 23:16 .byte 0x9b // present, ring 0, executable, !conforming, readable, accessed .byte 0xcf // granularity size, limit[19:16] = f .byte 0x0 // base 31:24 // data (0x10) .word 0xffff // limit 15:0 .word 0x0 // base 15:0 .byte 0x0 // base 23:16 .byte 0x93 // present, priv=0, !executable, stack down, writable, accessed .byte 0xcf // granularity=1 size=1, limit 19:16 = f .byte 0x0 // base 31:24 egdt: 0707010000007F000081A400000000000000000000000166C8A4FD0000011C000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/gdb.gdb# 15 lines 7 code 5 comments 3 blanks # # This is a comment line. We don't have multi-comment lines # macro define offsetof(_type, _memb) ((long)(&((_type *)0)->_memb)) break foo continue # Let's have something print when a breakpoint is hit. commands 2 p i continue end 07070100000080000081A400000000000000000000000166C8A4FD0000010D000000000000000000000000000000000000003700000000tokei-13.0.0.alpha.5+git0/tests/data/gdshader.gdshader// 24 lines 6 code 13 comments 5 blanks /* test test test */ /* /** */ void fragment() { // there is not any string in gdshader int x, b, c; float p, q, r; if(b == c) { } /** //sdsadasdasdasd /* **/ /* // odpwopdw // */ } 07070100000081000081A400000000000000000000000166C8A4FD000001BE000000000000000000000000000000000000003500000000tokei-13.0.0.alpha.5+git0/tests/data/gherkin.feature# 13 lines 8 code 3 comments 2 blanks Feature: Guess the word # The first example has two steps Scenario: Maker starts a game When the Maker starts a game Then the Maker waits for a Breaker to join # The second example has three steps Scenario: Breaker joins a game Given the Maker has started a game with the word "silky" When the Breaker joins the Maker's game Then the Breaker must guess a word with 5 characters 07070100000082000081A400000000000000000000000166C8A4FD00000242000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/gleam.gleam//// 34 lines 24 code 4 comments 6 blanks import gleam/option.{Option, None} import gleam/io pub type LoadedBool { Yup AlsoYup } pub external type Person pub opaque type Cat { Cat( name: String, age: Int, is_cute: LoadedBool, owner: Some(Person), ) } pub fn main() { let jane = // Here is a quote " new_kitten(called: "Jane") let kira = new_kitten(called: "Kira") io.println("Two kitties!") } /// A new baby kitten /// fn new_kitten(called name: String) -> Cat { // No owner yet! Cat(name: name, age: 0, is_cute: Yup, owner: None) } 07070100000083000081A400000000000000000000000166C8A4FD00000273000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/tests/data/glimmer_js.gjs// 27 lines, 18 code, 6 comments, 3 blanks import { helper } from '@ember/component/helper'; import { modifier } from 'ember-modifier'; // A single-line comment const plusOne = helper(([num]) => num + 1); /** * A multi-line comment */ const setScrollPosition = modifier((element, [position]) => { element.scrollTop = position }); <template> <!-- A HTML-like comment --> <div class="scroll-container" {{setScrollPosition @scrollPos}}> {{#each @items as |item index|}} Item #{{plusOne index}}: {{item}} {{/each}} </div> <style> div { background-color: #E04E39; } </style> </template> 07070100000084000081A400000000000000000000000166C8A4FD000001A2000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/tests/data/glimmer_ts.gts// 18 lines, 10 code, 6 comments, 2 blanks import type { TemplateOnlyComponent } from '@glimmer/component'; // A single-line comment const localVariable = 'foo'; /** * A multi-line comment */ const Greet: TemplateOnlyComponent<{ name: string }> = <template> <!-- A HTML-like comment --> <p>Hello, {{@name}}! {{localVariable}}</p> <style> p { background-color: #E04E39; } </style> </template> 07070100000085000081A400000000000000000000000166C8A4FD000000D7000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/gml.gml/* 17 lines 5 code 9 comments 3 blanks */ /* here's a comment */ /* this is also ...a comment! */ var a = 0; // @function b(c) // hi! function b(c) { d = 5; // how are you? } e = "good how r u";07070100000086000081A400000000000000000000000166C8A4FD000001E5000000000000000000000000000000000000002B00000000tokei-13.0.0.alpha.5+git0/tests/data/go.go// 37 lines 24 code 6 comments 7 blanks // Package main is a test file. package main import ( "errors" ) /* /**/ func main() { start := "/*" for { if len(start) >= 2 && start[1] == '*' && start[0] == '/' { // found the */ break } } if err := Foo(42, start); err != nil { panic(err) } } // Foo is a function. /* nested comment */ func Foo( // first a int, s string, /* second */ ) (err error) { m := `a multiline string` return errors.New(m) } // end of file 07070100000087000081A400000000000000000000000166C8A4FD00000316000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/gohtml.gohtml<!-- 41 lines 20 code 14 comments 7 blanks --> <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width" /> <title>{{ .title }}</title> </head> <body> <nav class="navbar navbar-default navbar-fixed-top navbar-custom"> {{/* GoHTML comment */}} <div id="modalSearch" class="modal fade" role="dialog"> </div> </nav> <!-- HTML single line Comment--> <main> <article> <h1>{{ .title }}</h1> <p>{{ .text }}</p> </article> </main> {{ template "footer" . }} </body> {{/* GoHTML multi line comment */}} <!-- document.write("Multi-line and Code comment!"); //--> <!--[if IE 8]> IE Special comment <![endif]--> </html> 07070100000088000081A400000000000000000000000166C8A4FD00000593000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/graphql.gql# 89 lines 71 code 3 comments 15 blanks """ A simple GraphQL schema which is well described. This is not a comment. See: https://facebook.github.io/graphql/June2018/#sec-Descriptions """ type Query { """ Translates a string from a given language into a different language. """ translate( "The original language that `text` is provided in." fromLanguage: Language "The translated language to be returned." toLanguage: Language "The text to be translated." text: String ): String } """ The set of languages supported by `translate`. """ enum Language { "English" EN "French" FR "Chinese" CH } # Comment the query and use "quotes" inside the comment query withFragments($expandedInfo: Boolean) { user(id: "3bd5a1cbed10e") { id # Insignificant comment ... @include(if: $expandedInfo) { firstName lastName birthday } friends(first: 10) { ...friendFields } profiles( handles: [ "zuck", "cocacola", "#hashed#hash#inside" ] ) { handle ... on User { friends { count } } ... on Page { likers { count } } } } } fragment friendFields on User { id firstName profilePic(size: 50) } # A simple GraphQL type definition type User { id: ID firstName: String lastName: String birthday: Date } 07070100000089000081A400000000000000000000000166C8A4FD000000A1000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/gwion.gw#! 10 lines 8 code 1 comments 1 blanks class C { var int i; var float f; var Object o; operator void @dtor () { <<< "dtor" >>>; } } var C c; <<< c >>>; 0707010000008A000081A400000000000000000000000166C8A4FD00000131000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/haml.haml-# 18 lines 11 code 2 comments 5 blanks %section.container - @posts.each do |post| -# Ruby comment %h1= post.title %h2= post.subtitle .content = post.content / HTML comment. Not detected as of now. %div %span This is all wrapped in a comment 0707010000008B000081A400000000000000000000000166C8A4FD00000107000000000000000000000000000000000000002C00000000tokei-13.0.0.alpha.5+git0/tests/data/hcl.tf# 22 lines 11 code 7 comments 4 blanks variable "foo" "bar" { default = "yes" } /* We like multiple lines */ locals { // this this = "that" # list more = ["foo", "bar"] /* map */ map = { yep = "nope" # bad comment nope = "yep" } } 0707010000008C000081A400000000000000000000000166C8A4FD00000152000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/headache.ha// 13 lines 9 code 3 comments 1 blanks /* //The Headache cat program */ // Implementation of Unix Cat in Headache void main() { char x; read x; //read from stdin while(x){ @x; //print char x read x; //read again from stdin if(x - (255 as char)){} else x = 0; //necessary for terminal emulation } }0707010000008D000081A400000000000000000000000166C8A4FD00000088000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/hicad.macREM 10 lines 4 code 3 comments 3 blanks START 59 REM Comment on a line %XY:=42 rem This is also a comment IF FOO= "foo" GOTO 10 END 0707010000008E000081A400000000000000000000000166C8A4FD000002EF000000000000000000000000000000000000003500000000tokei-13.0.0.alpha.5+git0/tests/data/hledger.hledger# 18 lines 6 code 10 comments 2 blanks # a comment ; another comment ; ^ a blank line comment account assets ; Declare valid account names and display order. a block comment end comment account assets:savings ; A subaccount. This one represents a bank account. account assets:checking ; Another. Note, 2+ spaces after the account name. account assets:receivable ; Accounting type is inferred from english names, account passifs ; or declared with a "type" tag, type:L account expenses ; type:X ; A follow-on comment line, indented. account expenses:rent ; Expense and revenue categories are also accounts. ; Subaccounts inherit their parent's type. 0707010000008F000081A400000000000000000000000166C8A4FD000000F9000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/hpp.hpp/* 21 lines 11 code 5 comments 5 blanks */ #ifndef TEST_H #define TEST_H #include <iostream> //Some definitions extern int out; void foo(); /* * Templated function */ template<typename T> void print_value(T& t) { std::cout<<t; } #endif 07070100000090000081A400000000000000000000000166C8A4FD00000360000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/html.html<!-- 46 lines 23 code 19 comments 4 blanks --> <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width" /> <title></title> link <style> /* CSS multi-line comment */ body { background-color: pink; } </style> </head> <body> body </body> <!-- Normal Comment--> <nav class="navbar navbar-default navbar-fixed-top navbar-custom"> <div id="modalSearch" class="modal fade" role="dialog"> </div> </nav> <!-- document.write("Multi-line and Code comment!"); //--> <!--[if IE 8]> IE Special comment <![endif]--> <script> /* Javascript multi-line comment */ let x = 5; // Javascript single line comment </script> </html> 07070100000091000081A400000000000000000000000166C8A4FD00000108000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/janet.janet# 17 lines 12 code 3 comments 2 blanks # Below is a function (defn a-fn "Docstring with a hash #" [a b] (+ 1 1)) (defn a-fn2 #"Not a doc" "String" [a b] # a and b right? (let [multiline "I'm a multline # string "] (str multline a b))) 07070100000092000081A400000000000000000000000166C8A4FD000001DE000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/java.java/* 37 lines 23 code 5 comments 9 blanks */ /* * Simple test class */ public class Test { int j = 0; // Not counted public static void main(String[] args) { Foo f = new Foo(); f.bar(); } } class Foo { public void bar() { System.out.println("FooBar"); //Not counted } } // issues/915 public class BackSlash { public void run() { "\\"; // 1 code + 2 blanks "\\"; // 1 code + 3 blanks } } 07070100000093000081A400000000000000000000000166C8A4FD000001B5000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/javascript.js// 33 lines, 14 code, 12 comments, 7 blanks /* * /* Nested comment * // single line comment * */ /* function add(a, b) { return a + b; } */ class Rectangle { constructor(width, height) { this.width = width; this.height = height; } get area() { return this.calcArea(); } calcArea() { return this.width * this.height; } } let rect = new Rectangle(20, 20); console.log(rect.area); // 400 // Comment 07070100000094000081A400000000000000000000000166C8A4FD0000004C000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/jinja2.j2{# 5 lines 1 code 2 comments 2 blanks #} {# test comment #} {{ testvar }} 07070100000095000081A400000000000000000000000166C8A4FD00000115000000000000000000000000000000000000002B00000000tokei-13.0.0.alpha.5+git0/tests/data/jq.jq# 11 lines 3 code 5 comments 3 blanks # A function to perform arithmetic def add_mul(adder; multiplier): # comment chararacter in quotes "# Result: " + ((. + adder) * multiplier | tostring); # and demonstrate it 10 | add_mul(5; 4) # => "# Result: 60" # end of file 07070100000096000081A400000000000000000000000166C8A4FD00000B57000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/jslt.jslt// 126 lines 80 code 20 comments 26 blanks // https://github.com/schibsted/jslt/blob/master/examples/queens.jslt // =========================================================================== // N-Queens problem solution in JSLT // board is n lists of length n // 0 => no queen // 1 => queen // queens(8) produces // [ // [ 1, 0, 0, 0, 0, 0, 0, 0 ], // [ 0, 0, 0, 0, 1, 0, 0, 0 ], // [ 0, 0, 0, 0, 0, 0, 0, 1 ], // [ 0, 0, 0, 0, 0, 1, 0, 0 ], // [ 0, 0, 1, 0, 0, 0, 0, 0 ], // [ 0, 0, 0, 0, 0, 0, 1, 0 ], // [ 0, 1, 0, 0, 0, 0, 0, 0 ], // [ 0, 0, 0, 1, 0, 0, 0, 0 ] // ] def queens(n) solve(0, make-board($n)) def range(length, list) if (size($list) < $length) range($length, $list + [size($list)]) else $list def zeroes(length) [for (range($length, [])) 0] def make-board(n) [for (range($n, [])) zeroes($n)] def solve(row, board) let n = size($board) if ($row == $n) $board else let tries = [for (range($n, [])) let newboard = place-queen($row, ., $board) if (is-ok($newboard)) solve($row + 1, $newboard) else null] filter($tries)[0] def is-ok(board) rows-ok($board) and cols-ok($board) and diagonals-ok($board) def rows-ok(board) all-ok([for ($board) sum(.) <= 1]) def cols-ok(board) // 0, 1, 2, 3, ... let indexes = range(size($board), []) // list of columns instead of list of rows let columns = [for ($indexes) let col = (.) [for ($board) .[$col]] ] rows-ok($columns) def diagonals-ok(board) let n = size($board) let offsets = range($n - 1, [])[1 : ] // starts with 1 let diagonals-right = ( [diagonal-right($board, 0, 0)] + [for ($offsets) diagonal-right($board, 0, .)] + [for ($offsets) diagonal-right($board, ., 0)] ) let diagonals-left = ( [diagonal-left($board, 0, $n - 1)] + [for ($offsets) diagonal-left($board, ., $n - 1)] + [for ($offsets) diagonal-left($board, 0, .)] ) rows-ok($diagonals-right + $diagonals-left) def diagonal-right(board, rowoff, coloff) if ($rowoff >= size($board) or $coloff >= size($board)) [] else [$board[$rowoff][$coloff]] + diagonal-right($board, $rowoff+1, $coloff+1) def diagonal-left(board, rowoff, coloff) if ($rowoff >= size($board) or $coloff < 0) [] else diagonal-left($board, $rowoff + 1, $coloff - 1) + [$board[$rowoff][$coloff]] def sum(numbers) if (not($numbers)) 0 else $numbers[0] + sum($numbers[1 : ]) def all-ok(booleans) if (not($booleans)) true else $booleans[0] and all-ok($booleans[1 : ]) def place-queen(row, col, board) let changerow = $board[$row] let newrow = $changerow[ : $col] + [1] + $changerow[$col + 1 : ] $board[ : $row] + [$newrow] + $board[$row + 1 : ] def filter(array) if (not($array)) [] else if ($array[0]) [$array[0]] + filter($array[1 : ]) else filter($array[1 : ]) queens(8) 07070100000097000081A400000000000000000000000166C8A4FD00000112000000000000000000000000000000000000003500000000tokei-13.0.0.alpha.5+git0/tests/data/jsonnet.jsonnet// 13 lines 7 code 4 comments 2 blanks /* /**/ */ local func(a, b) = { // very useful a: a, b: b, # you forgot about me! c: " /* comment in a string! */ ", e: ' // in another string ', // another after f: ' # in a final string ', # comment after though } 07070100000098000081A400000000000000000000000166C8A4FD0000FE82000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/jupyter.ipynb{ "cells": [ { "cell_type": "markdown", "metadata": {}, "source": [ "# Cheat Sheet: Writing Python 2-3 compatible code" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "- **Copyright (c):** 2013-2015 Python Charmers Pty Ltd, Australia.\n", "- **Author:** Ed Schofield.\n", "- **Licence:** Creative Commons Attribution.\n", "\n", "A PDF version is here: http://python-future.org/compatible_idioms.pdf\n", "\n", "This notebook shows you idioms for writing future-proof code that is compatible with both versions of Python: 2 and 3. It accompanies Ed Schofield's talk at PyCon AU 2014, \"Writing 2/3 compatible code\". (The video is here: <http://www.youtube.com/watch?v=KOqk8j11aAI&t=10m14s>.)\n", "\n", "Minimum versions:\n", "\n", " - Python 2: 2.6+\n", " - Python 3: 3.3+" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Setup" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "The imports below refer to these ``pip``-installable packages on PyPI:\n", "\n", " import future # pip install future\n", " import builtins # pip install future\n", " import past # pip install future\n", " import six # pip install six\n", "\n", "The following scripts are also ``pip``-installable:\n", "\n", " futurize # pip install future\n", " pasteurize # pip install future\n", "\n", "See http://python-future.org and https://pythonhosted.org/six/ for more information." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Essential syntax differences" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### print" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "print 'Hello'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "print('Hello')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "To print multiple strings, import ``print_function`` to prevent Py2 from interpreting it as a tuple:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "print 'Hello', 'Guido'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from __future__ import print_function # (at top of module)\n", "\n", "print('Hello', 'Guido')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "print >> sys.stderr, 'Hello'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from __future__ import print_function\n", "\n", "print('Hello', file=sys.stderr)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "print 'Hello'," ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from __future__ import print_function\n", "\n", "print('Hello', end='')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Raising exceptions" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "raise ValueError, \"dodgy value\"" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "raise ValueError(\"dodgy value\")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Raising exceptions with a traceback:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "traceback = sys.exc_info()[2]\n", "raise ValueError, \"dodgy value\", traceback" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only:\n", "raise ValueError(\"dodgy value\").with_traceback()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "from six import reraise as raise_\n", "# or\n", "from future.utils import raise_\n", "\n", "traceback = sys.exc_info()[2]\n", "raise_(ValueError, \"dodgy value\", traceback)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "from future.utils import raise_with_traceback\n", "\n", "raise_with_traceback(ValueError(\"dodgy value\"))" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Exception chaining (PEP 3134):" ] }, { "cell_type": "code", "execution_count": 3, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Setup:\n", "class DatabaseError(Exception):\n", " pass" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only\n", "class FileDatabase:\n", " def __init__(self, filename):\n", " try:\n", " self.file = open(filename)\n", " except IOError as exc:\n", " raise DatabaseError('failed to open') from exc" ] }, { "cell_type": "code", "execution_count": 16, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from future.utils import raise_from\n", "\n", "class FileDatabase:\n", " def __init__(self, filename):\n", " try:\n", " self.file = open(filename)\n", " except IOError as exc:\n", " raise_from(DatabaseError('failed to open'), exc)" ] }, { "cell_type": "code", "execution_count": 17, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Testing the above:\n", "try:\n", " fd = FileDatabase('non_existent_file.txt')\n", "except Exception as e:\n", " assert isinstance(e.__cause__, IOError) # FileNotFoundError on Py3.3+ inherits from IOError" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Catching exceptions" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "try:\n", " ...\n", "except ValueError, e:\n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "try:\n", " ...\n", "except ValueError as e:\n", " ..." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Division" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Integer division (rounding down):" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "assert 2 / 3 == 0" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "assert 2 // 3 == 0" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "\"True division\" (float division):" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only:\n", "assert 3 / 2 == 1.5" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from __future__ import division # (at top of module)\n", "\n", "assert 3 / 2 == 1.5" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "\"Old division\" (i.e. compatible with Py2 behaviour):" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "a = b / c # with any types" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from past.utils import old_div\n", "\n", "a = old_div(b, c) # always same as / on Py2" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Long integers" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Short integers are gone in Python 3 and ``long`` has become ``int`` (without the trailing ``L`` in the ``repr``)." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "k = 9223372036854775808L\n", "\n", "# Python 2 and 3:\n", "k = 9223372036854775808" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "bigint = 1L\n", "\n", "# Python 2 and 3\n", "from builtins import int\n", "bigint = int(1)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "To test whether a value is an integer (of any kind):" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "if isinstance(x, (int, long)):\n", " ...\n", "\n", "# Python 3 only:\n", "if isinstance(x, int):\n", " ...\n", "\n", "# Python 2 and 3: option 1\n", "from builtins import int # subclass of long on Py2\n", "\n", "if isinstance(x, int): # matches both int and long on Py2\n", " ...\n", "\n", "# Python 2 and 3: option 2\n", "from past.builtins import long\n", "\n", "if isinstance(x, (int, long)):\n", " ..." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Octal constants" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "0644 # Python 2 only" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "0o644 # Python 2 and 3" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Backtick repr" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "`x` # Python 2 only" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "repr(x) # Python 2 and 3" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Metaclasses" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "class BaseForm(object):\n", " pass\n", "\n", "class FormType(type):\n", " pass" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "class Form(BaseForm):\n", " __metaclass__ = FormType\n", " pass" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only:\n", "class Form(BaseForm, metaclass=FormType):\n", " pass" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from six import with_metaclass\n", "# or\n", "from future.utils import with_metaclass\n", "\n", "class Form(with_metaclass(FormType, BaseForm)):\n", " pass" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Strings and bytes" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Unicode (text) string literals" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "If you are upgrading an existing Python 2 codebase, it may be preferable to mark up all string literals as unicode explicitly with ``u`` prefixes:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "s1 = 'The Zen of Python'\n", "s2 = u'きたないのよりきれいな方がいい\\n'\n", "\n", "# Python 2 and 3\n", "s1 = u'The Zen of Python'\n", "s2 = u'きたないのよりきれいな方がいい\\n'" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "The ``futurize`` and ``python-modernize`` tools do not currently offer an option to do this automatically." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "If you are writing code for a new project or new codebase, you can use this idiom to make all string literals in a module unicode strings:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3\n", "from __future__ import unicode_literals # at top of module\n", "\n", "s1 = 'The Zen of Python'\n", "s2 = 'きたないのよりきれいな方がいい\\n'" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "See http://python-future.org/unicode_literals.html for more discussion on which style to use." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Byte-string literals" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "s = 'This must be a byte-string'\n", "\n", "# Python 2 and 3\n", "s = b'This must be a byte-string'" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "To loop over a byte-string with possible high-bit characters, obtaining each character as a byte-string of length 1:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "for bytechar in 'byte-string with high-bit chars like \\xf9':\n", " ...\n", "\n", "# Python 3 only:\n", "for myint in b'byte-string with high-bit chars like \\xf9':\n", " bytechar = bytes([myint])\n", "\n", "# Python 2 and 3:\n", "from builtins import bytes\n", "for myint in bytes(b'byte-string with high-bit chars like \\xf9'):\n", " bytechar = bytes([myint])" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "As an alternative, ``chr()`` and ``.encode('latin-1')`` can be used to convert an int into a 1-char byte string:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only:\n", "for myint in b'byte-string with high-bit chars like \\xf9':\n", " char = chr(myint) # returns a unicode string\n", " bytechar = char.encode('latin-1')\n", "\n", "# Python 2 and 3:\n", "from builtins import bytes, chr\n", "for myint in bytes(b'byte-string with high-bit chars like \\xf9'):\n", " char = chr(myint) # returns a unicode string\n", " bytechar = char.encode('latin-1') # forces returning a byte str" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### basestring" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "a = u'abc'\n", "b = 'def'\n", "assert (isinstance(a, basestring) and isinstance(b, basestring))\n", "\n", "# Python 2 and 3: alternative 1\n", "from past.builtins import basestring # pip install future\n", "\n", "a = u'abc'\n", "b = b'def'\n", "assert (isinstance(a, basestring) and isinstance(b, basestring))" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 2: refactor the code to avoid considering\n", "# byte-strings as strings.\n", "\n", "from builtins import str\n", "a = u'abc'\n", "b = b'def'\n", "c = b.decode()\n", "assert isinstance(a, str) and isinstance(c, str)\n", "# ..." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### unicode" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "templates = [u\"blog/blog_post_detail_%s.html\" % unicode(slug)]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 1\n", "from builtins import str\n", "templates = [u\"blog/blog_post_detail_%s.html\" % str(slug)]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 2\n", "from builtins import str as text\n", "templates = [u\"blog/blog_post_detail_%s.html\" % text(slug)]" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### StringIO" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from StringIO import StringIO\n", "# or:\n", "from cStringIO import StringIO\n", "\n", "# Python 2 and 3:\n", "from io import BytesIO # for handling byte strings\n", "from io import StringIO # for handling unicode strings" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Imports relative to a package" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Suppose the package is:\n", "\n", " mypackage/\n", " __init__.py\n", " submodule1.py\n", " submodule2.py\n", " \n", "and the code below is in ``submodule1.py``:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only: \n", "import submodule2" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from . import submodule2" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "# To make Py2 code safer (more like Py3) by preventing\n", "# implicit relative imports, you can also add this to the top:\n", "from __future__ import absolute_import" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Dictionaries" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "heights = {'Fred': 175, 'Anne': 166, 'Joe': 192}" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Iterating through ``dict`` keys/values/items" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Iterable dict keys:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "for key in heights.iterkeys():\n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "for key in heights:\n", " ..." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Iterable dict values:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "for value in heights.itervalues():\n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Idiomatic Python 3\n", "for value in heights.values(): # extra memory overhead on Py2\n", " ..." ] }, { "cell_type": "code", "execution_count": 8, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "from builtins import dict\n", "\n", "heights = dict(Fred=175, Anne=166, Joe=192)\n", "for key in heights.values(): # efficient on Py2 and Py3\n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "from builtins import itervalues\n", "# or\n", "from six import itervalues\n", "\n", "for key in itervalues(heights):\n", " ..." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Iterable dict items:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "for (key, value) in heights.iteritems():\n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "for (key, value) in heights.items(): # inefficient on Py2 \n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "from future.utils import viewitems\n", "\n", "for (key, value) in viewitems(heights): # also behaves like a set\n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 3\n", "from future.utils import iteritems\n", "# or\n", "from six import iteritems\n", "\n", "for (key, value) in iteritems(heights):\n", " ..." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### dict keys/values/items as a list" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "dict keys as a list:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "keylist = heights.keys()\n", "assert isinstance(keylist, list)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "keylist = list(heights)\n", "assert isinstance(keylist, list)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "dict values as a list:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "heights = {'Fred': 175, 'Anne': 166, 'Joe': 192}\n", "valuelist = heights.values()\n", "assert isinstance(valuelist, list)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "valuelist = list(heights.values()) # inefficient on Py2" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "from builtins import dict\n", "\n", "heights = dict(Fred=175, Anne=166, Joe=192)\n", "valuelist = list(heights.values())" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 3\n", "from future.utils import listvalues\n", "\n", "valuelist = listvalues(heights)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 4\n", "from future.utils import itervalues\n", "# or\n", "from six import itervalues\n", "\n", "valuelist = list(itervalues(heights))" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "dict items as a list:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "itemlist = list(heights.items()) # inefficient on Py2" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "from future.utils import listitems\n", "\n", "itemlist = listitems(heights)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 3\n", "from future.utils import iteritems\n", "# or\n", "from six import iteritems\n", "\n", "itemlist = list(iteritems(heights))" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Custom class behaviour" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Custom iterators" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "class Upper(object):\n", " def __init__(self, iterable):\n", " self._iter = iter(iterable)\n", " def next(self): # Py2-style\n", " return self._iter.next().upper()\n", " def __iter__(self):\n", " return self\n", "\n", "itr = Upper('hello')\n", "assert itr.next() == 'H' # Py2-style\n", "assert list(itr) == list('ELLO')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "from builtins import object\n", "\n", "class Upper(object):\n", " def __init__(self, iterable):\n", " self._iter = iter(iterable)\n", " def __next__(self): # Py3-style iterator interface\n", " return next(self._iter).upper() # builtin next() function calls\n", " def __iter__(self):\n", " return self\n", "\n", "itr = Upper('hello')\n", "assert next(itr) == 'H' # compatible style\n", "assert list(itr) == list('ELLO')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "from future.utils import implements_iterator\n", "\n", "@implements_iterator\n", "class Upper(object):\n", " def __init__(self, iterable):\n", " self._iter = iter(iterable)\n", " def __next__(self): # Py3-style iterator interface\n", " return next(self._iter).upper() # builtin next() function calls\n", " def __iter__(self):\n", " return self\n", "\n", "itr = Upper('hello')\n", "assert next(itr) == 'H'\n", "assert list(itr) == list('ELLO')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Custom ``__str__`` methods" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "class MyClass(object):\n", " def __unicode__(self):\n", " return 'Unicode string: \\u5b54\\u5b50'\n", " def __str__(self):\n", " return unicode(self).encode('utf-8')\n", "\n", "a = MyClass()\n", "print(a) # prints encoded string" ] }, { "cell_type": "code", "execution_count": 11, "metadata": { "collapsed": false }, "outputs": [ { "name": "stdout", "output_type": "stream", "text": [ "Unicode string: 孔子\n" ] } ], "source": [ "# Python 2 and 3:\n", "from future.utils import python_2_unicode_compatible\n", "\n", "@python_2_unicode_compatible\n", "class MyClass(object):\n", " def __str__(self):\n", " return u'Unicode string: \\u5b54\\u5b50'\n", "\n", "a = MyClass()\n", "print(a) # prints string encoded as utf-8 on Py2" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Custom ``__nonzero__`` vs ``__bool__`` method:" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "class AllOrNothing(object):\n", " def __init__(self, l):\n", " self.l = l\n", " def __nonzero__(self):\n", " return all(self.l)\n", "\n", "container = AllOrNothing([0, 100, 200])\n", "assert not bool(container)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from builtins import object\n", "\n", "class AllOrNothing(object):\n", " def __init__(self, l):\n", " self.l = l\n", " def __bool__(self):\n", " return all(self.l)\n", "\n", "container = AllOrNothing([0, 100, 200])\n", "assert not bool(container)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Lists versus iterators" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### xrange" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "for i in xrange(10**8):\n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: forward-compatible\n", "from builtins import range\n", "for i in range(10**8):\n", " ..." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: backward-compatible\n", "from past.builtins import xrange\n", "for i in xrange(10**8):\n", " ..." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### range" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "mylist = range(5)\n", "assert mylist == [0, 1, 2, 3, 4]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: forward-compatible: option 1\n", "mylist = list(range(5)) # copies memory on Py2\n", "assert mylist == [0, 1, 2, 3, 4]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: forward-compatible: option 2\n", "from builtins import range\n", "\n", "mylist = list(range(5))\n", "assert mylist == [0, 1, 2, 3, 4]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 3\n", "from future.utils import lrange\n", "\n", "mylist = lrange(5)\n", "assert mylist == [0, 1, 2, 3, 4]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: backward compatible\n", "from past.builtins import range\n", "\n", "mylist = range(5)\n", "assert mylist == [0, 1, 2, 3, 4]" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### map" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "mynewlist = map(f, myoldlist)\n", "assert mynewlist == [f(x) for x in myoldlist]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "# Idiomatic Py3, but inefficient on Py2\n", "mynewlist = list(map(f, myoldlist))\n", "assert mynewlist == [f(x) for x in myoldlist]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "from builtins import map\n", "\n", "mynewlist = list(map(f, myoldlist))\n", "assert mynewlist == [f(x) for x in myoldlist]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 3\n", "try:\n", " import itertools.imap as map\n", "except ImportError:\n", " pass\n", "\n", "mynewlist = list(map(f, myoldlist)) # inefficient on Py2\n", "assert mynewlist == [f(x) for x in myoldlist]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 4\n", "from future.utils import lmap\n", "\n", "mynewlist = lmap(f, myoldlist)\n", "assert mynewlist == [f(x) for x in myoldlist]" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 5\n", "from past.builtins import map\n", "\n", "mynewlist = map(f, myoldlist)\n", "assert mynewlist == [f(x) for x in myoldlist]" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### imap" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from itertools import imap\n", "\n", "myiter = imap(func, myoldlist)\n", "assert isinstance(myiter, iter)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only:\n", "myiter = map(func, myoldlist)\n", "assert isinstance(myiter, iter)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "from builtins import map\n", "\n", "myiter = map(func, myoldlist)\n", "assert isinstance(myiter, iter)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "try:\n", " import itertools.imap as map\n", "except ImportError:\n", " pass\n", "\n", "myiter = map(func, myoldlist)\n", "assert isinstance(myiter, iter)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### zip, izip" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "As above with ``zip`` and ``itertools.izip``." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### filter, ifilter" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "As above with ``filter`` and ``itertools.ifilter`` too." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Other builtins" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### File IO with open()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": true }, "outputs": [], "source": [ "# Python 2 only\n", "f = open('myfile.txt')\n", "data = f.read() # as a byte string\n", "text = data.decode('utf-8')\n", "\n", "# Python 2 and 3: alternative 1\n", "from io import open\n", "f = open('myfile.txt', 'rb')\n", "data = f.read() # as bytes\n", "text = data.decode('utf-8') # unicode, not bytes\n", "\n", "# Python 2 and 3: alternative 2\n", "from io import open\n", "f = open('myfile.txt', encoding='utf-8')\n", "text = f.read() # unicode, not bytes" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### reduce()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "assert reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) == 1+2+3+4+5" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from functools import reduce\n", "\n", "assert reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) == 1+2+3+4+5" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### raw_input()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "name = raw_input('What is your name? ')\n", "assert isinstance(name, str) # native str" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from builtins import input\n", "\n", "name = input('What is your name? ')\n", "assert isinstance(name, str) # native str on Py2 and Py3" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### input()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "input(\"Type something safe please: \")" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3\n", "from builtins import input\n", "eval(input(\"Type something safe please: \"))" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Warning: using either of these is **unsafe** with untrusted input." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### file()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "f = file(pathname)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "f = open(pathname)\n", "\n", "# But preferably, use this:\n", "from io import open\n", "f = open(pathname, 'rb') # if f.read() should return bytes\n", "# or\n", "f = open(pathname, 'rt') # if f.read() should return unicode text" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### exec" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": true }, "outputs": [], "source": [ "# Python 2 only:\n", "exec 'x = 10'\n", "\n", "# Python 2 and 3:\n", "exec('x = 10')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": true }, "outputs": [], "source": [ "# Python 2 only:\n", "g = globals()\n", "exec 'x = 10' in g\n", "\n", "# Python 2 and 3:\n", "g = globals()\n", "exec('x = 10', g)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": true }, "outputs": [], "source": [ "# Python 2 only:\n", "l = locals()\n", "exec 'x = 10' in g, l\n", "\n", "# Python 2 and 3:\n", "exec('x = 10', g, l)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "But note that Py3's `exec()` is less powerful (and less dangerous) than Py2's `exec` statement." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### execfile()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "execfile('myfile.py')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 1\n", "from past.builtins import execfile\n", "\n", "execfile('myfile.py')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 2\n", "exec(compile(open('myfile.py').read()))\n", "\n", "# This can sometimes cause this:\n", "# SyntaxError: function ... uses import * and bare exec ...\n", "# See https://github.com/PythonCharmers/python-future/issues/37" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### unichr()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "assert unichr(8364) == '€'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only:\n", "assert chr(8364) == '€'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from builtins import chr\n", "assert chr(8364) == '€'" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### intern()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "intern('mystring')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only:\n", "from sys import intern\n", "intern('mystring')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 1\n", "from past.builtins import intern\n", "intern('mystring')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 2\n", "from six.moves import intern\n", "intern('mystring')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 3\n", "from future.standard_library import install_aliases\n", "install_aliases()\n", "from sys import intern\n", "intern('mystring')" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 2\n", "try:\n", " from sys import intern\n", "except ImportError:\n", " pass\n", "intern('mystring')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### apply()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "args = ('a', 'b')\n", "kwargs = {'kwarg1': True}" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "apply(f, args, kwargs)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 1\n", "f(*args, **kwargs)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 2\n", "from past.builtins import apply\n", "apply(f, args, kwargs)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### chr()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "assert chr(64) == b'@'\n", "assert chr(200) == b'\\xc8'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only: option 1\n", "assert chr(64).encode('latin-1') == b'@'\n", "assert chr(0xc8).encode('latin-1') == b'\\xc8'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 1\n", "from builtins import chr\n", "\n", "assert chr(64).encode('latin-1') == b'@'\n", "assert chr(0xc8).encode('latin-1') == b'\\xc8'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only: option 2\n", "assert bytes([64]) == b'@'\n", "assert bytes([0xc8]) == b'\\xc8'" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: option 2\n", "from builtins import bytes\n", "\n", "assert bytes([64]) == b'@'\n", "assert bytes([0xc8]) == b'\\xc8'" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### cmp()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "assert cmp('a', 'b') < 0 and cmp('b', 'a') > 0 and cmp('c', 'c') == 0" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 1\n", "from past.builtins import cmp\n", "assert cmp('a', 'b') < 0 and cmp('b', 'a') > 0 and cmp('c', 'c') == 0" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 2\n", "cmp = lambda(x, y): (x > y) - (x < y)\n", "assert cmp('a', 'b') < 0 and cmp('b', 'a') > 0 and cmp('c', 'c') == 0" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### reload()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "reload(mymodule)" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3\n", "from imp import reload\n", "reload(mymodule)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Standard library" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### dbm modules" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "import anydbm\n", "import whichdb\n", "import dbm\n", "import dumbdbm\n", "import gdbm\n", "\n", "# Python 2 and 3: alternative 1\n", "from future import standard_library\n", "standard_library.install_aliases()\n", "\n", "import dbm\n", "import dbm.ndbm\n", "import dbm.dumb\n", "import dbm.gnu\n", "\n", "# Python 2 and 3: alternative 2\n", "from future.moves import dbm\n", "from future.moves.dbm import dumb\n", "from future.moves.dbm import ndbm\n", "from future.moves.dbm import gnu\n", "\n", "# Python 2 and 3: alternative 3\n", "from six.moves import dbm_gnu\n", "# (others not supported)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### commands / subprocess modules" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "from commands import getoutput, getstatusoutput\n", "\n", "# Python 2 and 3\n", "from future import standard_library\n", "standard_library.install_aliases()\n", "\n", "from subprocess import getoutput, getstatusoutput" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### subprocess.check_output()" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2.7 and above\n", "from subprocess import check_output\n", "\n", "# Python 2.6 and above: alternative 1\n", "from future.moves.subprocess import check_output\n", "\n", "# Python 2.6 and above: alternative 2\n", "from future import standard_library\n", "standard_library.install_aliases()\n", "\n", "from subprocess import check_output" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### collections: Counter, OrderedDict, ChainMap" ] }, { "cell_type": "code", "execution_count": 6, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2.7 and above\n", "from collections import Counter, OrderedDict, ChainMap\n", "\n", "# Python 2.6 and above: alternative 1\n", "from future.backports import Counter, OrderedDict, ChainMap\n", "\n", "# Python 2.6 and above: alternative 2\n", "from future import standard_library\n", "standard_library.install_aliases()\n", "\n", "from collections import Counter, OrderedDict, ChainMap" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### StringIO module" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only\n", "from StringIO import StringIO\n", "from cStringIO import StringIO" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3\n", "from io import BytesIO\n", "# and refactor StringIO() calls to BytesIO() if passing byte-strings" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### http module" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "import httplib\n", "import Cookie\n", "import cookielib\n", "import BaseHTTPServer\n", "import SimpleHTTPServer\n", "import CGIHttpServer\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "import http.client\n", "import http.cookies\n", "import http.cookiejar\n", "import http.server" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### xmlrpc module" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "import DocXMLRPCServer\n", "import SimpleXMLRPCServer\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "import xmlrpc.server" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "import xmlrpclib\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "import xmlrpc.client" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### html escaping and entities" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3:\n", "from cgi import escape\n", "\n", "# Safer (Python 2 and 3, after ``pip install future``):\n", "from html import escape\n", "\n", "# Python 2 only:\n", "from htmlentitydefs import codepoint2name, entitydefs, name2codepoint\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "from html.entities import codepoint2name, entitydefs, name2codepoint" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### html parsing" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from HTMLParser import HTMLParser\n", "\n", "# Python 2 and 3 (after ``pip install future``)\n", "from html.parser import HTMLParser\n", "\n", "# Python 2 and 3 (alternative 2):\n", "from future.moves.html.parser import HTMLParser" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### urllib module" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "``urllib`` is the hardest module to use from Python 2/3 compatible code. You may like to use Requests (http://python-requests.org) instead." ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from urlparse import urlparse\n", "from urllib import urlencode\n", "from urllib2 import urlopen, Request, HTTPError" ] }, { "cell_type": "code", "execution_count": 2, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 3 only:\n", "from urllib.parse import urlparse, urlencode\n", "from urllib.request import urlopen, Request\n", "from urllib.error import HTTPError" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: easiest option\n", "from future.standard_library import install_aliases\n", "install_aliases()\n", "\n", "from urllib.parse import urlparse, urlencode\n", "from urllib.request import urlopen, Request\n", "from urllib.error import HTTPError" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 2\n", "from future.standard_library import hooks\n", "\n", "with hooks():\n", " from urllib.parse import urlparse, urlencode\n", " from urllib.request import urlopen, Request\n", " from urllib.error import HTTPError" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 3\n", "from future.moves.urllib.parse import urlparse, urlencode\n", "from future.moves.urllib.request import urlopen, Request\n", "from future.moves.urllib.error import HTTPError\n", "# or\n", "from six.moves.urllib.parse import urlparse, urlencode\n", "from six.moves.urllib.request import urlopen\n", "from six.moves.urllib.error import HTTPError" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 and 3: alternative 4\n", "try:\n", " from urllib.parse import urlparse, urlencode\n", " from urllib.request import urlopen, Request\n", " from urllib.error import HTTPError\n", "except ImportError:\n", " from urlparse import urlparse\n", " from urllib import urlencode\n", " from urllib2 import urlopen, Request, HTTPError" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Tkinter" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "import Tkinter\n", "import Dialog\n", "import FileDialog\n", "import ScrolledText\n", "import SimpleDialog\n", "import Tix \n", "import Tkconstants\n", "import Tkdnd \n", "import tkColorChooser\n", "import tkCommonDialog\n", "import tkFileDialog\n", "import tkFont\n", "import tkMessageBox\n", "import tkSimpleDialog\n", "import ttk\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "import tkinter\n", "import tkinter.dialog\n", "import tkinter.filedialog\n", "import tkinter.scrolledtext\n", "import tkinter.simpledialog\n", "import tkinter.tix\n", "import tkinter.constants\n", "import tkinter.dnd\n", "import tkinter.colorchooser\n", "import tkinter.commondialog\n", "import tkinter.filedialog\n", "import tkinter.font\n", "import tkinter.messagebox\n", "import tkinter.simpledialog\n", "import tkinter.ttk" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### socketserver" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "import SocketServer\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "import socketserver" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### copy_reg, copyreg" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "import copy_reg\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "import copyreg" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### configparser" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from ConfigParser import ConfigParser\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "from configparser import ConfigParser" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### queue" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from Queue import Queue, heapq, deque\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "from queue import Queue, heapq, deque" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### repr, reprlib" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from repr import aRepr, repr\n", "\n", "# Python 2 and 3 (after ``pip install future``):\n", "from reprlib import aRepr, repr" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### UserDict, UserList, UserString" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from UserDict import UserDict\n", "from UserList import UserList\n", "from UserString import UserString\n", "\n", "# Python 3 only:\n", "from collections import UserDict, UserList, UserString\n", "\n", "# Python 2 and 3: alternative 1\n", "from future.moves.collections import UserDict, UserList, UserString\n", "\n", "# Python 2 and 3: alternative 2\n", "from six.moves import UserDict, UserList, UserString\n", "\n", "# Python 2 and 3: alternative 3\n", "from future.standard_library import install_aliases\n", "install_aliases()\n", "from collections import UserDict, UserList, UserString" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### itertools: filterfalse, zip_longest" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "collapsed": false }, "outputs": [], "source": [ "# Python 2 only:\n", "from itertools import ifilterfalse, izip_longest\n", "\n", "# Python 3 only:\n", "from itertools import filterfalse, zip_longest\n", "\n", "# Python 2 and 3: alternative 1\n", "from future.moves.itertools import filterfalse, zip_longest\n", "\n", "# Python 2 and 3: alternative 2\n", "from six.moves import filterfalse, zip_longest\n", "\n", "# Python 2 and 3: alternative 3\n", "from future.standard_library import install_aliases\n", "install_aliases()\n", "from itertools import filterfalse, zip_longest" ] } ], "metadata": { "kernelspec": { "display_name": "Python 3", "language": "python", "name": "python3" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.4.3" } }, "nbformat": 4, "nbformat_minor": 0 } 07070100000099000081A400000000000000000000000166C8A4FD00000122000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/tests/data/k.k// 8 lines 2 code 4 comments 2 blanks /suduko solver / initial state x:.:'"200370009009200007001004002050000800008000900006000040900100500800007600400089001" / breadth search all solutions (p:row col box for each position) *(,x)(,/{@[x;y;:;]'&~in[!10]x*|/p[;y]=p,:3/:_(p:9\:!81)%3}')/&~x 0707010000009A000081A400000000000000000000000166C8A4FD000000E2000000000000000000000000000000000000003800000000tokei-13.0.0.alpha.5+git0/tests/data/kakoune_script.kak# 13 lines, 8 code, 2 comments, 3 blanks hook global BufCreate (.*/)?(kakrc|.*.kak) %{ set-option buffer filetype kak } echo "This is a string". echo 'This is a multiline string # with a hash in it.' # This is a comment. 0707010000009B000081ED00000000000000000000000166C8A4FD00000128000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/ksh.ksh#!/bin/ksh # 17 lines, 11 code, 4 comments, 2 blanks # first comment files="/etc/passwd /etc/group /etc/hosts" for f in $files; do if [ ! -f $f ] then echo "$f file missing!" fi done # second comment for f in $(ls /tmp/*) do print "Full file path in /tmp dir : $f" done 0707010000009C000081A400000000000000000000000166C8A4FD0000020F000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/kvlanguage.kv# 22 lines 17 code 3 comments 2 blanks #:kivy 2.0.0 #:import C kivy.utils.get_color_from_hex #:import KeypadButton keypadbutton #:include keypadbutton.kv #:set name value <DynamicWidgetClass>: color: C('#27272A') # general comment <Keypad@GridLayout>: width: self.minimum_width height: self.minimum_height size_hint: None, None cols: 3 spacing: 6 KeypadButton: text: '1' disabled: root.disabled on_press: root.dispatch('on_key_pressed', self.key_val) # a final comment 0707010000009D000081A400000000000000000000000166C8A4FD0000035C000000000000000000000000000000000000003500000000tokei-13.0.0.alpha.5+git0/tests/data/lalrpop.lalrpop// 37 lines 26 code 3 comments 8 blanks use crate::ast::{ExprSymbol, Opcode}; use crate::tok9::Tok; grammar<'input>(input: &'input str); // line comment pub Expr: Box<ExprSymbol<'input>> = { // comment 1 Expr r##"verbatim2"## Factor => Box::new(ExprSymbol::Op(<>)), Factor, // comment 2 }; Factor: Box<ExprSymbol<'input>> = { // comment 3 Factor "FactorOp" Term => Box::new(ExprSymbol::Op(<>)), Term, }; // comment 4 Term: Box<ExprSymbol<'input>> = { r#"verbatim"# => Box::new(ExprSymbol::NumSymbol(<>)), "(" <Expr> ")" }; extern { type Location = usize; type Error = (); enum Tok<'input> { r#"verbatim"# => Tok::NumSymbol(<&'input str>), "FactorOp" => Tok::FactorOp(<Opcode>), r##"verbatim2"## => Tok::ExprOp(<Opcode>), "(" => Tok::ParenOpen, ")" => Tok::ParenClose, } } 0707010000009E000081A400000000000000000000000166C8A4FD00000314000000000000000000000000000000000000003500000000tokei-13.0.0.alpha.5+git0/tests/data/linguafranca.lf// 36 lines 16 code 9 comments 11 blanks target Rust; // A C style comment import KeyboardEvents from "KeyboardEvents.lf"; /* A block comment */ # a python like comment main reactor Snake(grid_side: usize(32), food_limit: u32(2)) { // counts as 2 lines of Rust code and one blank preamble {= use crate::snakes::*; use rand::prelude::*; =} /// rust doc comment keyboard = new KeyboardEvents(); // T state snake: CircularSnake ({= CircularSnake::new(grid_side) =}); state grid: SnakeGrid ({= SnakeGrid::new(grid_side, &snake) =}); state food_on_grid: u32(0); // 1 line of rust code reaction(shutdown) {= // comment in Rust println!("New high score: {}", self.snake.len()); =} } 0707010000009F000081A400000000000000000000000166C8A4FD00000345000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/liquid.liquid{% comment %} 24 lines 19 code 1 comments 4 blanks {% endcomment %} {% paginate collection.products by 20 %} <ul id="product-collection"> {% for product in collection.products %} <li class="singleproduct clearfix"> <div class="small"> <div class="prodimage"><a href="{{product.url}}"><img src="{{ product.featured_image | product_img_url: 'small' }}" /></a></div> </div> <div class="description"> <h3><a href="{{product.url}}">{{product.title}}</a></h3> <p>{{ product.description | strip_html | truncatewords: 35 }}</p> <p class="money">{{ product.price_min | money }}{% if product.price_varies %} - {{ product.price_max | money }}{% endif %}</p> </div> </li> {% endfor %} </ul> <div id="pagination"> {{ paginate | default_pagination }} </div> {% endpaginate %} 070701000000A0000081A400000000000000000000000166C8A4FD00000174000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/livescript.ls# 28 lines, 10 code, 12 comments, 6 blanks /* * /* Nested comment * # single line comment * */ /* add = (a, b) -> return a + b */ hello = -> console.log 'hello, world!' "hello!" |> capitalize |> console.log # Easy listing of implicit objects table1 = * id: 1 name: 'george' * id: 2 name: 'mike' # comment * id: 3 name: 'donald' # Comment 070701000000A1000081A400000000000000000000000166C8A4FD0000017C000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/llvm.ll; 21 lines 17 code 1 comments 3 blanks define i32 @add1(i32 %a, i32 %b) { entry: %tmp1 = add i32 %a, %b ret i32 %tmp1 } define i32 @add2(i32 %a, i32 %b) { entry: %tmp1 = icmp eq i32 %a, 0 br i1 %tmp1, label %done, label %recurse recurse: %tmp2 = sub i32 %a, 1 %tmp3 = add i32 %b, 1 %tmp4 = call i32 @add2(i32 %tmp2, i32 %tmp3) ret i32 %tmp4 done: ret i32 %b }070701000000A2000081A400000000000000000000000166C8A4FD00000575000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/logtalk.lgt/* Test file for the Logtalk programming language (copied by the author from a Logtalk distribution example) 65 lines 27 code 18 comments 20 blanks */ % Alf believes he is the only survivor of his species; no point in % defining a class if there is only going to be a single instance: % a prototype, which is also a stand-alone object :- object(alf). % prototypes declare predicates for themselves (and derived prototypes) :- public([ name/1, planet/1, stomachs/1, favorite_food/1, chases/1, motto/1 ]). name('Gordon Shumway'). planet('Melmac'). stomachs(8). favorite_food(cats). chases('Lucky'). motto('Are you going to finish that sandwich?'). :- end_object. % later on, Alf finds out that his best friend, Skip, and his % girlfriend, Rhonda, also survived Melmac's explosion; as they % are all melmacians, they share most attributes (and add some % of their own): % "skip", a derived prototype from "alf", its parent prototype :- object(skip, extends(alf)). :- public(best_friend/1). best_friend(alf). name('Skip'). % still longing for a nice cat to eat since Melmac exploded chases(_) :- fail. :- end_object. % "rhonda" is also a prototype derived from "alf" :- object(rhonda, extends(alf)). :- public(boyfriend/1). boyfriend(alf). name('Rhonda'). % still longing for a nice cat to eat since Melmac exploded chases(_) :- fail. :- end_object. 070701000000A3000081A400000000000000000000000166C8A4FD0000018F000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/lolcode.lolBTW 26 lines 11 code 9 comments 6 blanks HAI 1.3 BTW TEST! I HAS A MSG ITZ "BYE! OBTW" HOW IZ I PRINT_HELLO I HAS A MSG ITZ "BTW Hello, World!" BTW OBTW BTW MORE COMMENTS! VISIBLE MSG BTW TLDR IF U SAY SO I HAS A MSG ITZ "Hello OBTW BTW TLDR" I IZ PRINT_HELLO MKAY OBTW a longer test asd TLDR OBTW TLDR I IZ PRINT_HELLO MKAY OBTW should be valid foo bar TLDR VISIBLE MSG KTHXBYE 070701000000A4000081A400000000000000000000000166C8A4FD000000E5000000000000000000000000000000000000002B00000000tokei-13.0.0.alpha.5+git0/tests/data/m4.m4dnl 7 lines 3 code 1 blanks 3 comments The builtin `dnl' stands for “Discard to Next Line”: dnl this line is not emitted Other text is emitted You can also make comments with `#' # this is a comment # This is a comment, too 070701000000A5000081A400000000000000000000000166C8A4FD0000040D000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/menhir.mly// 47 lines 31 code 7 comments 9 blanks (* Example from the menhir development with instrumented comments. * (* Note: nested C style comments are not allowed. *) * https://gitlab.inria.fr/fpottier/menhir/-/tree/master/demos/calc-alias *) %token<int> INT "42" %token PLUS "+" %token MINUS "-" %token TIMES "*" %token DIV "/" %token LPAREN "(" %token RPAREN ")" %token EOL (* Token aliases can be used throughout the rest of the grammar. E.g., they can be used in precedence declarations: *) %left "+" "-" /* lowest " precedence */ %left "*" "/" /* medium precedence */ %nonassoc UMINUS // highest "precedence" %start <int> main %% main: | e = expr EOL { e } (* Token aliases can also be used inside rules: *) expr: | i = "42" { i } | "(" e = expr ")" { e } | e1 = expr "+" e2 = expr { e1 + e2 } | e1 = expr "-" e2 = expr { e1 - e2 } | e1 = expr "*" e2 = expr { e1 * e2 } | e1 = expr "/" e2 = expr { e1 / e2 } | "-" e = expr %prec UMINUS { - e } 070701000000A6000081A400000000000000000000000166C8A4FD000000CA000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/meson.build# 12 lines 6 code 2 comments 4 blanks project('xyz', 'c', meson_version : '>=0.30.0') # not counted xyz_gen = ''' # comment inside print("This is generated source.") ''' # this is a comment 070701000000A7000081A400000000000000000000000166C8A4FD000001C1000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/metal.metal/* 32 lines 21 code 5 comments 6 blanks */ #include <metal_stdlib> // comment struct Uniforms { float2 extent; }; struct VertexIn { float2 position [[attribute(0)]]; }; struct VertexOut { float2 position [[position]]; }; /* multi-line comment */ vertex VertexOut vs_main( VertexIn in [[stage_in]] ) { VertexOut out; return out; } fragment float4 fs_main( VertexOut in [[stage_in]] ) { return float4(0.0); } 070701000000A8000081A400000000000000000000000166C8A4FD00000208000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/mlatu.mlt// 22 lines 14 code 3 comments 5 blanks define divisible (Int, Int -> Bool +Fail) { (%) 0 (=) } // Here's a random comment that is definitely useful define fizzbuzz (Int -> String) { -> n; do (with (+Fail)) { n 5 divisible n 3 divisible } if { if { "FizzBuzz" } else { "Fizz" } } else { if { "Buzz" } else { n show } } } define fizzbuzzes (Int, Int -> +IO) { -> c, m; c fizzbuzz println (c < m) if { (c + 1) m fizzbuzzes } else {} // We don't need anything here } 1 100 fizzbuzzes // Comment at end 070701000000A9000081A400000000000000000000000166C8A4FD00000135000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/moduledef.def; 17 lines 9 code 6 comments 2 blanks ; ; Definition file of KERNEL32.dll ; Automatic generated by gendef ; written by Kai Tietz 2008 ; LIBRARY "KERNEL32.dll" EXPORTS "BaseThreadInitThunk;@4" InterlockedPushListSList@8 AcquireSRWLockExclusive@4 AcquireSRWLockShared@4 ActivateActCtx@8 AddAtomA@4 AddAtomW@4 070701000000AA000081A400000000000000000000000166C8A4FD00000831000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/monkeyc.mc// 69 lines 41 code 18 comments 10 blanks // Slightly modified template from the "Garmin.monkey-c" VS Code extension. import Toybox.Application; import Toybox.Graphics; import Toybox.Lang; import Toybox.System; import Toybox.WatchUi; class WatchFaceView extends WatchUi.WatchFace { function initialize() { WatchFace.initialize(); } // Load your resources here function onLayout(dc as Dc) as Void { setLayout(Rez.Layouts.WatchFace(dc)); } /* Called when this View is brought to the foreground. Restore the state of this View and prepare it to be shown. This includes loading resources into memory. */ function onShow() as Void { } // Update the view function onUpdate(dc as Dc) as Void { // Get the current time and format it correctly var timeFormat = "$1$:$2$"; var clockTime = System.getClockTime(); var hours = clockTime.hour; if (!System.getDeviceSettings().is24Hour) { if (hours > 12) { hours = hours - 12; } } else { if (getApp().getProperty("UseMilitaryFormat")) { timeFormat = "$1$$2$"; hours = hours.format("%02d"); } } var timeString = Lang.format(timeFormat, [hours, clockTime.min.format("%02d")]); // Update the view var view = View.findDrawableById("TimeLabel") as Text; view.setColor(getApp().getProperty("ForegroundColor") as Number); view.setText(timeString); View.onUpdate(dc); // Call the parent onUpdate function to redraw the layout } /* Called when this View is removed from the screen. Save the state of this View here. This includes freeing resources from memory. */ function onHide() as Void { } // The user has just looked at their watch. Timers and animations may be started here. function onExitSleep() as Void { } // Terminate any active timers and prepare for slow updates. function onEnterSleep() as Void { } }070701000000AB000081A400000000000000000000000166C8A4FD000000F9000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/nextflow.nf/* 18 lines 10 code 5 comments 3 blanks */ /* Nextflow - hello */ // comment cheers = Channel.from 'Bonjour', 'Ciao', 'Hello', 'Hola' process sayHello { echo true input: val x from cheers script: """ echo '$x world!' """ } 070701000000AC000081A400000000000000000000000166C8A4FD00000223000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/nqp.nqp# 24 lines 14 code 8 comments 2 blanks =begin Regex methods and functions =end =begin item match Match C<$text> against C<$regex>. If the C<$global> flag is given, then return an array of all non-overlapping matches. =end item sub match ($text, $regex, :$global?) { my $match := $text ~~ $regex; if $global { my @matches; while $match { nqp::push(@matches, $match); $match := $match.parse($text, :rule($regex), :c($match.to)); } @matches; } else { $match; } } 070701000000AD000081A400000000000000000000000166C8A4FD0000021E000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/odin.odin// 29 lines 17 code 7 comments 5 blanks import "core:fmt" /* * Calculates the next number in the Collatz sequence * * If `x` is divisible by two, the result is `x` divided by two * If `x` is not divisible by two, the result is `x` multiplied by three plus one */ collatz :: inline proc(x: int) -> int { if x & 1 == 0 do return x >> 1; else do return x * 3 + 1; } steps :: proc(x: int) -> int { count := 0; y := x; for y != 1 { y = collatz(y); count += 1; } return count; } main :: proc() { fmt.println(steps(42)); // 8 }070701000000AE000081A400000000000000000000000166C8A4FD00000133000000000000000000000000000000000000003C00000000tokei-13.0.0.alpha.5+git0/tests/data/open_policy_agent.rego# 13 lines 8 code 3 comments 2 blanks package application.authz # Only owner can update the pet's information # Ownership information is provided as part of OPA's input default allow = false allow { input.method == "PUT" some petid input.path = ["pets", petid] input.user == input.owner } 070701000000AF000081A400000000000000000000000166C8A4FD000002C8000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/openscad.scad//! 34 lines 15 code 16 comments 3 blanks // https://en.wikibooks.org/wiki/OpenSCAD_User_Manual/Commented_Example_Projects // The idea is to twist a translated circle: // - /* linear_extrude(height = 10, twist = 360, scale = 0) translate([1,0]) circle(r = 1); */ module horn(height = 10, radius = 6, twist = 720, $fn = 50) { // A centered circle translated by 1xR and // twisted by 360° degrees, covers a 2x(2xR) space. // - radius = radius/4; // De-translate. // - translate([-radius,0]) // The actual code. // - linear_extrude(height = height, twist = twist, scale=0, $fn = $fn) translate([radius,0]) circle(r=radius); } translate([3,0]) mirror() horn(); translate([-3,0]) horn(); 070701000000B0000081A400000000000000000000000166C8A4FD00000810000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/opentype.fea# 54 lines 24 code 24 comments 6 blanks languagesystem DFLT dflt; languagesystem latn dflt; languagesystem latn DEU; languagesystem latn TRK; languagesystem cyrl dflt; feature smcp { sub [a-z] by [A.sc-Z.sc]; # Since all the rules in this feature are of the same type, they will be grouped in a single lookup. # Since no script or language keyword has been specified yet, # the lookup will be registered for this feature under all the language systems. } smcp; feature liga { sub f f by f_f; sub f i by f_i; sub f l by f_l; # Since all the rules in this feature are of the same type, they will be # grouped in a single lookup. # Since no script or language keyword has been specified yet, # the lookup will be registered for this feature under all the language systems. script latn; language dflt; # lookupflag 0; (implicit) sub c t by c_t; sub c s by c_s; # The rules above will be placed in a lookup that is registered for all # the specified languages for the script latn, but not any other scripts. language DEU; # script latn; (stays the same) # lookupflag 0; (stays the same) sub c h by c_h; sub c k by c_k; # The rules above will be placed in a lookup that is registered only # under the script 'latn', 'language DEU'. language TRK; # This will inherit both the top level default rules - the rules defined # before the first 'script' statement, and the script-level default # rules for 'latn: all the lookups of this feature defined after the # 'script latn' statement, and before the 'language DEU' statement. # If 'TRK' were not named here, it would not inherit the default rules # for the script 'latn'. } liga; feature kern { pos a y -150; # [more pos statements] # All the rules in this feature will be grouped in a single lookup # that is registered under all the languagesystems. } kern; 070701000000B1000081A400000000000000000000000166C8A4FD000000BA000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/org_mode.org# 13 lines 7 code 2 comments 4 blanks #+TITLE: This is the title, not a comment # This is comment Some text * Heading 1 :PROPERTIES: :CUSTOM_ID: heading-1 :END: Text under heading 1 070701000000B2000081A400000000000000000000000166C8A4FD00000276000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/pan.pan# 21 lines 11 code 4 comments 6 blanks # Pan example code, see https://quattor-pan.readthedocs.io/en/stable/pan-book/index.html prefix "/system/aii/osinstall/ks"; "clearpart" = append("vdb"); "ignoredisk" = list(); # no disks to ignore prefix "/system/blockdevices"; "physical_devs/vdb/label" = "msdos"; "partitions/vdb1" = dict( "holding_dev", "vdb", ); "files/{/srv/elasticsearch}" = dict('size', 0); # To facilitate adding other partitions at a later stage, a # logical volume will be created "volume_groups/vg1/device_list" = append("partitions/vdb1"); "logical_volumes" = lvs_add('vg1', dict("elasticsearch", -1)); 070701000000B3000081A400000000000000000000000166C8A4FD000000D4000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/pcss.pcss/* 14 lines 6 code 5 comments 3 blanks */ .foo { color: #f00; &.bar { background: url("foobar.jpg"); } } // inline comments are allowed by some PostCSS syntaxes /* * block comments are standard */ 070701000000B4000081A400000000000000000000000166C8A4FD00000103000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/pest.pest// 9 lines 4 code 3 comments 2 blanks alpha = { 'a'..'z' | 'A'..'Z' } digit = { '0'..'9' } ident = { (alpha | digit)+ } ident_list = _{ !digit ~ ident ~ (" " ~ ident)+ } // ^ // ident_list rule is silent which means it produces no tokens070701000000B5000081A400000000000000000000000166C8A4FD00000403000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/plantuml.puml' 35 lines 10 code 13 comments 12 blanks ' plantuml line comments must start at the beginning of a line. ' plantuml block comments must either start on a newline or start and end on the same line as they start. ' strings cannot span multiple lines. ' single quotes are a valid string wrapper '', but not when they are the first non-whitespace characters on a line ' comment at start uml @startuml !include <C4/C4_Container> '' this is also a comment rectangle "this is a string" as r /' this is a multi-line comment '/ /' this is also a multi-line comment '/ Container(C, "This is some more text", "text") node n /' this is a multi-line comment at the end of a line '/ /' this is /' a valid '/ block comment '/ component "'this is not a comment" /' this is a multi-line comment at the start of a line '/ interface i boundary "/' this is not a multi-line comment '/" System(s, "this is /' not part of a comment", "'/ this is also not part of a comment", "/' '/ /' neither is this") ' comment after start uml @enduml 070701000000B6000081A400000000000000000000000166C8A4FD000001E6000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/pofile.po# 14 lines 6 code 5 comments 3 blanks #: lib/error.c:116 msgid "Unknown system error" msgstr "Error desconegut del sistema" #: disk-utils/addpart.c:15 #, c-format msgid " %s <disk device> <partition number> <start> <length>\n" msgstr " %s <périphérique disque> <numéro de partition> <début> <longueur>\n" #: disk-utils/addpart.c:19 msgid "Tell the kernel about the existence of a specified partition.\n" msgstr "Informer le noyau de l’existence d’une partition indiquée.\n" 070701000000B7000081A400000000000000000000000166C8A4FD00000197000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/tests/data/pofile_pot.pot# 17 lines 8 code 5 comments 4 blanks #: disk-utils/addpart.c:60 disk-utils/delpart.c:61 disk-utils/resizepart.c:101 msgid "invalid partition number argument" msgstr "" #: disk-utils/addpart.c:61 msgid "invalid start argument" msgstr "" #: disk-utils/addpart.c:62 disk-utils/resizepart.c:111 msgid "invalid length argument" msgstr "" #: disk-utils/addpart.c:63 msgid "failed to add partition" msgstr "" 070701000000B8000081A400000000000000000000000166C8A4FD00000066000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/poke.pk/* 4 lines 2 code 1 comments 1 blanks */ var N = 3; fun getoff = offset<uint<64>,B>: { return 2#B; } 070701000000B9000081A400000000000000000000000166C8A4FD000000B6000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/pony.pony// 12 lines 7 code 3 comments 2 blanks /* com- -ment */ actor Main """ Some Docs """ new create(env: Env) => env.out.print("Hello, world.") 070701000000BA000081A400000000000000000000000166C8A4FD00000154000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/postcss.sss// 27 lines 18 code 4 comments 5 blanks /** multi-line */ div { width: calc(99.9% * 1/3 - (30px - 30px * 1/3)); } div:nth-child(1n) { float: left; margin-right: 30px; clear: none; } div:last-child { margin-right: 0; } div:nth-child(3n) { margin-right: 0; float: right; } div:nth-child(3n + 1) { clear: both; } 070701000000BB000081A400000000000000000000000166C8A4FD000000A7000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/tests/data/powershell.ps1# 17 lines 9 code 4 comments 4 blanks <# Test #> 'a' + "b" Write-Host @" Name: $name Address: $address "@ $template = @' Name: {0} Address: {0} '@ 070701000000BC000081A400000000000000000000000166C8A4FD000000F9000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/pug.pug//- 13 lines, 8 code, 3 comments, 2 blanks doctype html // this comment will be translated to an HTML comment //- this comment will be excluded from the generated HTML html head title Hello, World! body p | Hello, | World! 070701000000BD000081A400000000000000000000000166C8A4FD00000132000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/puppet.pp# 18 lines 14 code 3 comments 1 blanks class example::class( $param1, $param2=2, $param3=undef, # pass this one ) { # comments are really simple some::resource { 'bar': param1 => param2, # comments here too param3 => param4; } some::other::resource { 'baz': } } 070701000000BE000081A400000000000000000000000166C8A4FD000000E1000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/python.py# 15 lines, 10 code, 2 comments, 3 blanks def add(x, y): """ Hello World # Real Second line Second line """ string = "Hello World #\ " y += len(string) # Add the two numbers. x + y 070701000000BF000081A400000000000000000000000166C8A4FD00000170000000000000000000000000000000000000002900000000tokei-13.0.0.alpha.5+git0/tests/data/q.q// 14 lines 5 code 5 comments 4 blanks /calc nav for sets of portfolios,ETFs,indices,.. /one day of ([]time;sym;price) sorted by time n:10000000;S:-10000?`4 t:([]time:09:30:00.0+til n;sym:n?S;price:n?1.0) /calc price deltas once \t update deltas price by sym from`t /for each portfolio a:([sym:-100?S]weight:100?1.0) \t r:select time,sums price*weight from t ij a 070701000000C0000081A400000000000000000000000166C8A4FD0000012F000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/qml.qml// 20 lines 11 code 5 comments 4 blanks import QtQuick 2.7 import QtQuick.Controls 2.0 ApplicationWindow { visible: true /* * Multiline comment */ Text { text: "string type 1" } // comment function testfunc() { console.log('string type 2'); } } 070701000000C1000081A400000000000000000000000166C8A4FD00000309000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/racket.rkt;;; 40 lines 15 code 14 comments 11 blanks #lang racket ; defines the language we are using ;;; Comments ;; Single line comments start with a semicolon #| Block comments can span multiple lines and... #| they can be nested! |# |# ;; S-expression comments discard the following expression ;; since this is syntax-aware, tokei counts this as code #; (this expression is discarded) ;; Constant (define %pi 3.14159265358979323846) #| This is a block comment |# (define (degrees->radians deg) (* deg (/ %pi 180))) ;; Function (define (sq x) (* x x)) (define (sum xs) "Sum list of elements." (foldl + 0 xs)) ; comment (define (sum-upto n) (/ (* n (+ 1 n)) 2)) (define (test-sums n) (= (sum-upto n) (sum (range (+ 1 n))))) (test-sums 100) 070701000000C2000081A400000000000000000000000166C8A4FD00000310000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/raku.raku# 49 lines 37 code 6 comments 6 blanks =begin pod =begin DESCRIPTION =head1 Test file for Tokei =end DESCRIPTION =begin code :lang<raku> say 'Hello World'; =end code =end pod #| Fibonacci with multiple dispatch multi sub fib (0 --> 0) {} multi sub fib (1 --> 1) {} multi sub fib (\n where * > 1) { fib(n - 1) + fib(n - 2) } #|{ Role shape for printing area of different shapes } role Shape { method area { ... } method print_area { say "Area of {self.^name} is {self.area}."; } } class Rectangle does Shape { has $.width is required; #= Width of rectangle has $.height is required; #= Height of rectangle method area { #`( area of rectangle: width times height ) $!width × $!height } } 070701000000C3000081A400000000000000000000000166C8A4FD000005B6000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/razor.cshtml@* 55 lines 35 code 15 comments 5 blanks *@ @page "/" @using Microsoft.AspNetCore.Components.Web @namespace temp.Pages @addTagHelper *, Microsoft.AspNetCore.Mvc.TagHelpers @{ // foo string foo = "bar"; /* * bar */ string bar = "foo"; } <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <base href="~/" /> <link rel="stylesheet" href="css/bootstrap/bootstrap.min.css" /> <link href="css/site.css" rel="stylesheet" /> <link href="temp.styles.css" rel="stylesheet" /> <link rel="icon" type="image/png" href="favicon.png"/> <component type="typeof(HeadOutlet)" render-mode="ServerPrerendered" /> </head> <body> @* multi-line comment *@ <component type="typeof(App)" render-mode="ServerPrerendered" /> <div id="blazor-error-ui"> <environment include="Staging,Production"> An error has occurred. This application may no longer respond until reloaded. </environment> <!-- different multi-line comment --> <environment include="Development"> An unhandled exception has occurred. See browser dev tools for details. </environment> <a href="" class="reload">Reload</a> <a class="dismiss">🗙</a> </div> <script src="_framework/blazor.server.js"></script> </body> </html> 070701000000C4000081A400000000000000000000000166C8A4FD00000257000000000000000000000000000000000000003A00000000tokei-13.0.0.alpha.5+git0/tests/data/razorcomponent.razor@* 45 lines 16 code 21 comments 8 blanks *@ @page "/counter" @{ // foo string foo = "bar"; /* * bar */ string bar = "foo"; } <PageTitle>Counter</PageTitle> @* multi-line comment *@ <h1>Counter</h1> <p role="status">Current count: @currentCount</p> <!-- different multi-line comment --> <button class="btn btn-primary" @onclick="IncrementCount">Click me</button> @code { /* C# style multi-line comment */ private int currentCount = 0; private void IncrementCount() { // increment the count currentCount++; } } 070701000000C5000081A400000000000000000000000166C8A4FD00000885000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/tests/data/redscript.reds// 75 lines 47 code 20 comments 8 blanks // redscript allows line comments /* as well as block comments */ // it supports global functions func add2(x: Int32, y: Int32) -> Int32 { return x + y; } // functions without a type annotation default to Void return type func tutorial() { let x: Int32 = 10; // compiler can infer types for local variables, y will be Int32 let y = 20; // it supports arithmetic let sum = x + y + 13; // as well as mutation let mutable = 0; mutable += 10; // numbers with decimal points default to type Float let num = 10.0; // you can cast between some types let uint: Uint8 = Cast(10); // array literals let arr = [1, 2, 3]; // array iteration for item in arr { // logging and string operations Log("at " + ToString(item)); } } // you can define your own classes public class IntTuple { let fst: Int32; let snd: Int32; // you can define static member functions public static func Create(fst: Int32, snd: Int32) -> ref<IntTuple> { let tuple = new IntTuple(); tuple.fst = fst; tuple.snd = snd; return tuple; } public func Swap() { let tmp = this.fst; this.fst = this.snd; this.snd = tmp; } } // you can replace existing in-game methods by specifying the class they belong to @replaceMethod(CraftingSystem) private final func ProcessCraftSkill(xpAmount: Int32, craftedItem: StatsObjectID) { // instantiate a class using the new operator let xpEvent = new ExperiencePointsEvent(); xpEvent.amount = xpAmount * 100; xpEvent.type = gamedataProficiencyType.Crafting; GetPlayer(this.GetGameInstance()).QueueEvent(xpEvent); } // you can add new methods to existing classes as well // they are visible to other code using the class @addMethod(BackpackMainGameController) private final func DisassembleAllJunkItems() -> Void { let items = this.m_InventoryManager.GetPlayerItemsByType(gamedataItemType.Gen_Junk); let i = 0; for item in items { ItemActionsHelper.DisassembleItem(this.m_player, InventoryItemData.GetID(item)); }; // some methods require CName literals, they need to be prefixed with the n letter this.PlaySound(n"Item", n"OnBuy"); }070701000000C6000081A400000000000000000000000166C8A4FD00000299000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/renpy.rpy# 32 lines 8 code 9 comments 15 blanks # Declare characters used by this game. The color argument colorizes the # name of the character. define e = Character("Eileen") # The game starts here. label start: # Show a background. This uses a placeholder by default, but you can # add a file (named either "bg room.png" or "bg room.jpg") to the # images directory to show it. scene bg room show eileen happy # These display lines of dialogue. e "You've created a new Ren'Py game." e 'Once you add a story, pictures, and music, you can release it to the world!' e `Testing, testing` # This ends the game. return 070701000000C7000081A400000000000000000000000166C8A4FD0000143D000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/ron.ron// 157 lines 137 code 7 comments 13 blanks #![enable(implicit_some)] Container( transform: ( id: "background", anchor: Middle, stretch: XY( x_margin: 0., y_margin: 0., keep_aspect_ratio: false), width: 20., height: 20., ), background: SolidColor(0.03, 0.03, 0.03, 1.0), children: [ Container( transform: ( id: "container_start", y: 180, width: 755., height: 170., anchor: Middle, ), background: SolidColor(1.0, 0.65, 0.0, 1.0), children: [ // Complex Button Button( transform: ( id: "start", width: 750., height: 165., tab_order: 1, anchor: Middle, mouse_reactive: true, ), button: ( text: "START GAME", font: File("font/square.ttf", ("TTF", ())), font_size: 75., normal_text_color: (1.0, 0.65, 0., 1.0), // ffa500 // hover_text_color: (1.0, 0.65, 0., 1.0), // press_text_color: (1.0, 0.65, 0., 1.0), normal_image: SolidColor(0., 0., 0., 1.), hover_image: SolidColor(0.1, 0.1, 0.1, 1.), press_image: SolidColor(0.15, 0.15, 0.15, 1.), ) ), ] ), Container( transform: ( id: "container_load", y: 0, width: 755., height: 170., anchor: Middle, ), background: SolidColor(1.0, 0.65, 0.0, 1.0), children: [ // Complex Button Button( transform: ( id: "load", width: 750., height: 165., tab_order: 3, anchor: Middle, mouse_reactive: true, ), button: ( text: "LOAD GAME", font: File("font/square.ttf", ("TTF", ())), font_size: 75., normal_text_color: (1.0, 0.65, 0., 1.0), // ffa500 normal_image: SolidColor(0., 0., 0., 1.), hover_image: SolidColor(0.1, 0.1, 0.1, 1.), press_image: SolidColor(0.15, 0.15, 0.15, 1.), ) ), ] ), Container( transform: ( id: "container_options", y: -180, width: 755., height: 170., anchor: Middle, ), background: SolidColor(1.0, 0.65, 0.0, 1.0), children: [ // Complex Button Button( transform: ( id: "options", width: 750., height: 165., tab_order: 3, anchor: Middle, mouse_reactive: true, ), button: ( text: "OPTIONS", font: File("font/square.ttf", ("TTF", ())), font_size: 75., normal_text_color: (1.0, 0.65, 0., 1.0), // ffa500 normal_image: SolidColor(0., 0., 0., 1.), hover_image: SolidColor(0.1, 0.1, 0.1, 1.), press_image: SolidColor(0.15, 0.15, 0.15, 1.), ) ), ] ), Container( transform: ( id: "container_credits", y: -360, width: 755., height: 170., anchor: Middle, ), background: SolidColor(1.0, 0.65, 0.0, 1.0), children: [ // Complex Button Button( transform: ( id: "credits", width: 750., height: 165., tab_order: 3, anchor: Middle, mouse_reactive: true, ), button: ( text: "CREDITS", font: File("font/square.ttf", ("TTF", ())), font_size: 75., normal_text_color: (1.0, 0.65, 0., 1.0), // ffa500 normal_image: SolidColor(0., 0., 0., 1.), hover_image: SolidColor(0.1, 0.1, 0.1, 1.), press_image: SolidColor(0.15, 0.15, 0.15, 1.), ) ), ] ), ], ) 070701000000C8000081A400000000000000000000000166C8A4FD000001CD000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/rpmspec.spec# 42 lines 22 code 4 comments 16 blanks Name: example Version: 0.0.1 Release: 1%{?dist} Summary: an example specfile Group: URL: Source0: # test comments for requirements BuildRequires: Requires: %description %prep %setup -q # build the project %build %configure make build # install the files here %install make install %clean %files %defattr(-,root,root,-) %doc %changelog 070701000000C9000081A400000000000000000000000166C8A4FD000000C7000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/ruby.rb# 20 lines 9 code 8 comments 3 blanks x = 3 if x < 2 p = "Smaller" else p = "Bigger" end =begin Comments Comments Comments Comments =end # testing. while x > 2 and x < 10 x += 1 end 070701000000CA000081A400000000000000000000000166C8A4FD000000A5000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/ruby_env#!/usr/bin/env ruby # 11 lines 3 code 6 comments 2 blanks =begin Comment that only counts if detected as ruby Comments =end while x > 2 and x < 10 x += 1 end070701000000CB000081A400000000000000000000000166C8A4FD000002DA000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/ruby_html.erb<!-- 34 lines 21 code 8 comments 5 blanks --> <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width" /> <title><%= title %></title> </head> <body> <nav class="navbar navbar-default navbar-fixed-top navbar-custom"> <%# ruby comment %> <div id="modalSearch" class="modal fade" role="dialog"> </div> </nav> <!-- HTML single line Comment--> <main> <article> <h1><%= header %></h1> <p><%= text %></p> </article> </main> <%= template "footer" %> </body> <!-- document.write("Multi-line and Code comment!"); //--> <!--[if IE 8]> IE Special comment <![endif]--> </html> 070701000000CC000081A400000000000000000000000166C8A4FD00000348000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/rust.rs//! 48 lines 36 code 6 comments 6 blanks //! ```rust //! fn main () { //! // Comment //! //! println!("Hello World!"); //! } //! ``` /* /**/ */ fn main() { let start = r##"/*##\" \"##; // comment loop { if x.len() >= 2 && x[0] == '*' && x[1] == '/' { // found the */ break; } } } fn foo<'a, 'b>(name: &'b str) { let this_ends = "a \"test/*."; call1(); call2(); let this_does_not = /* a /* nested */ comment " */ "*/another /*test call3(); */"; } fn foobar() { let does_not_start = // " "until here, test/* test"; // a quote: " let also_doesnt_start = /* " */ "until here, test,*/ test"; // another quote: " } fn foo() { let a = 4; // /* let b = 5; let c = 6; // */ } 070701000000CD000081A400000000000000000000000166C8A4FD000001C3000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/scheme.scm;;; 26 lines 14 code 4 comments 8 blanks (import (srfi srfi-1)) ; for reduce ;; Constant (define %pi 3.14159265358979323846) #| This is a block comment |# (define (degrees->radians deg) (* deg (/ %pi 180))) ;; Function (define (sq x) (* x x)) (define (sum xs) "Sum list of elements." (reduce + 0 xs)) ; comment (define (sum-upto n) (/ (* n (1+ n)) 2)) (define (test-sums n) (= (sum-upto n) (sum (iota (1+ n))))) (test-sums 100) 070701000000CE000081A400000000000000000000000166C8A4FD0000036B000000000000000000000000000000000000003600000000tokei-13.0.0.alpha.5+git0/tests/data/shaderlab.shader// 43 lines 31 code 8 comments 4 blanks Shader "Custom/Sample shader" { Properties { _MainTex ("Texture", 2D) = "white" {} } SubShader { Tags { "Queue"="Transparent" "RenderType"="Transparent" } // blending Blend SrcAlpha OneMinusSrcAlpha /* multi-line comment */ Pass { CGPROGRAM #pragma vertex vert struct appdata { float4 vertex : POSITION; float2 uv : TEXCOORD0; }; sampler2D _MainTex; // vertex v2f vert (appdata v) { v2f o; o.vertex = UnityObjectToClipPos(v.vertex); o.uv = TRANSFORM_TEX(v.uv, _MainTex); return o; } ENDCG } } } 070701000000CF000081A400000000000000000000000166C8A4FD00000113000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/slang.slang// 15 lines 8 code 5 comments 2 blanks Texture2D<float4> in_tex; RWTexture2D<float4> out_tex; // Blit compute shader [shader("compute")] [numthreads(8, 8, 1)] void main(uint2 id: SV_DispatchThreadID) { /* Perform the blit */ out_tex[id] = in_tex[id]; return; } 070701000000D0000081A400000000000000000000000166C8A4FD000000F8000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/solidity.sol// 14 lines 6 code 7 comments 1 blanks pragma solidity >=0.4.22 <0.6.0; // Comment line contract Foo { /* Comment line Comment line Comment line */ function foo(address bar) public { require(bar != 0); } } 070701000000D1000081A400000000000000000000000166C8A4FD00000151000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/sql.sql-- 12 lines 4 code 5 comments 3 blanks SELECT * FROM Users WHERE FirstName is not null; -- select rows where the user has a first name /* this is the beginning of a block comment insert a new user into the Users table -- line comment in a block comment */ INSERT INTO Users (FirstName, LastName) VALUES ("John", "Does");070701000000D2000081A400000000000000000000000166C8A4FD0000028C000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/srecode.srt;; 37 lines 23 code 2 comments 12 blanks set escape_start "$" set escape_end "$" set mode "srecode-template-mode" set priority "70" set comment_start ";;" set comment_end "" set comment_prefix ";;" set SEPARATOR "----" set DOLLAR "$" context file prompt MAJORMODE "Major Mode for templates: " read srecode-read-major-mode-name prompt START "Escape Start Characters: " default "{{" prompt END "Escape End Characters: " default "}}" template empty :file :user :time :srt "Insert a skeleton for a template file." ---- $>:filecomment$ set mode "$?MAJORMODE$" set escape_start "$?START$" set escape_end "$?END$" context file $^$ ;; end ---- 070701000000D3000081A400000000000000000000000166C8A4FD000016F1000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/stan.stan// 142 lines 123 code 17 comments 2 blanks // Example code from https://github.com/TheEconomist/us-potus-model/blob/85be55ae7b0bc68cb155a9ca975e155837eb4851/scripts/model/poll_model_2020.stan data{ int N_national_polls; // Number of polls int N_state_polls; // Number of polls int T; // Number of days int S; // Number of states (for which at least 1 poll is available) + 1 int P; // Number of pollsters int M; // Number of poll modes int Pop; // Number of poll populations int<lower = 1, upper = S + 1> state[N_state_polls]; // State index int<lower = 1, upper = T> day_state[N_state_polls]; // Day index int<lower = 1, upper = T> day_national[N_national_polls]; // Day index int<lower = 1, upper = P> poll_state[N_state_polls]; // Pollster index int<lower = 1, upper = P> poll_national[N_national_polls]; // Pollster index int<lower = 1, upper = M> poll_mode_state[N_state_polls]; // Poll mode index int<lower = 1, upper = M> poll_mode_national[N_national_polls]; // Poll mode index int<lower = 1, upper = Pop> poll_pop_state[N_state_polls]; // Poll mode index int<lower = 1, upper = Pop> poll_pop_national[N_national_polls]; // Poll mode index int n_democrat_national[N_national_polls]; int n_two_share_national[N_national_polls]; int n_democrat_state[N_state_polls]; int n_two_share_state[N_state_polls]; vector<lower = 0, upper = 1.0>[N_national_polls] unadjusted_national; vector<lower = 0, upper = 1.0>[N_state_polls] unadjusted_state; // cov_matrix[S] ss_cov_mu_b_walk; // cov_matrix[S] ss_cov_mu_b_T; // cov_matrix[S] ss_cov_poll_bias; //*** prior input vector[S] mu_b_prior; vector[S] state_weights; real sigma_c; real sigma_m; real sigma_pop; real sigma_measure_noise_national; real sigma_measure_noise_state; real sigma_e_bias; // covariance matrix and scales cov_matrix[S] state_covariance_0; real random_walk_scale; real mu_b_T_scale; real polling_bias_scale; } transformed data { real national_cov_matrix_error_sd = sqrt(transpose(state_weights) * state_covariance_0 * state_weights); cholesky_factor_cov[S] cholesky_ss_cov_poll_bias; cholesky_factor_cov[S] cholesky_ss_cov_mu_b_T; cholesky_factor_cov[S] cholesky_ss_cov_mu_b_walk; // scale covariance matrix[S, S] ss_cov_poll_bias = state_covariance_0 * square(polling_bias_scale/national_cov_matrix_error_sd); matrix[S, S] ss_cov_mu_b_T = state_covariance_0 * square(mu_b_T_scale/national_cov_matrix_error_sd); matrix[S, S] ss_cov_mu_b_walk = state_covariance_0 * square(random_walk_scale/national_cov_matrix_error_sd); // transformation cholesky_ss_cov_poll_bias = cholesky_decompose(ss_cov_poll_bias); cholesky_ss_cov_mu_b_T = cholesky_decompose(ss_cov_mu_b_T); cholesky_ss_cov_mu_b_walk = cholesky_decompose(ss_cov_mu_b_walk); } parameters { vector[S] raw_mu_b_T; matrix[S, T] raw_mu_b; vector[P] raw_mu_c; vector[M] raw_mu_m; vector[Pop] raw_mu_pop; real<offset=0, multiplier=0.02> mu_e_bias; real<lower = 0, upper = 1> rho_e_bias; vector[T] raw_e_bias; vector[N_national_polls] raw_measure_noise_national; vector[N_state_polls] raw_measure_noise_state; vector[S] raw_polling_bias; real mu_b_T_model_estimation_error; } transformed parameters { //*** parameters matrix[S, T] mu_b; vector[P] mu_c; vector[M] mu_m; vector[Pop] mu_pop; vector[T] e_bias; vector[S] polling_bias = cholesky_ss_cov_poll_bias * raw_polling_bias; vector[T] national_mu_b_average; real national_polling_bias_average = transpose(polling_bias) * state_weights; real sigma_rho; //*** containers vector[N_state_polls] logit_pi_democrat_state; vector[N_national_polls] logit_pi_democrat_national; //*** construct parameters mu_b[:,T] = cholesky_ss_cov_mu_b_T * raw_mu_b_T + mu_b_prior; // * mu_b_T_model_estimation_error for (i in 1:(T-1)) mu_b[:, T - i] = cholesky_ss_cov_mu_b_walk * raw_mu_b[:, T - i] + mu_b[:, T + 1 - i]; national_mu_b_average = transpose(mu_b) * state_weights; mu_c = raw_mu_c * sigma_c; mu_m = raw_mu_m * sigma_m; mu_pop = raw_mu_pop * sigma_pop; e_bias[1] = raw_e_bias[1] * sigma_e_bias; sigma_rho = sqrt(1-square(rho_e_bias)) * sigma_e_bias; for (t in 2:T) e_bias[t] = mu_e_bias + rho_e_bias * (e_bias[t - 1] - mu_e_bias) + raw_e_bias[t] * sigma_rho; //*** fill pi_democrat for (i in 1:N_state_polls){ logit_pi_democrat_state[i] = mu_b[state[i], day_state[i]] + mu_c[poll_state[i]] + mu_m[poll_mode_state[i]] + mu_pop[poll_pop_state[i]] + unadjusted_state[i] * e_bias[day_state[i]] + raw_measure_noise_state[i] * sigma_measure_noise_state + polling_bias[state[i]]; } logit_pi_democrat_national = national_mu_b_average[day_national] + mu_c[poll_national] + mu_m[poll_mode_national] + mu_pop[poll_pop_national] + unadjusted_national .* e_bias[day_national] + raw_measure_noise_national * sigma_measure_noise_national + national_polling_bias_average; } model { //*** priors raw_mu_b_T ~ std_normal(); //mu_b_T_model_estimation_error ~ scaled_inv_chi_square(7, 1); to_vector(raw_mu_b) ~ std_normal(); raw_mu_c ~ std_normal(); raw_mu_m ~ std_normal(); raw_mu_pop ~ std_normal(); mu_e_bias ~ normal(0, 0.02); rho_e_bias ~ normal(0.7, 0.1); raw_e_bias ~ std_normal(); raw_measure_noise_national ~ std_normal(); raw_measure_noise_state ~ std_normal(); raw_polling_bias ~ std_normal(); //*** likelihood n_democrat_state ~ binomial_logit(n_two_share_state, logit_pi_democrat_state); n_democrat_national ~ binomial_logit(n_two_share_national, logit_pi_democrat_national); } generated quantities { matrix[T, S] predicted_score; for (s in 1:S){ //predicted_score[1:T, s] = inv_logit(mu_a[1:T] + to_vector(mu_b[s, 1:T])); predicted_score[1:T, s] = inv_logit(to_vector(mu_b[s, 1:T])); } } 070701000000D4000081A400000000000000000000000166C8A4FD000000FB000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/stata.do* 16 lines 6 code 7 comments 3 blanks * This is a comment **** Any number of * symbol use "foo.dta", replace gen x = 1*2 gen x2 = 1/2 /* Here's a comment block */ if c(username) == "foobar" { global FOO 1 } // Finally another symbol for comment070701000000D5000081A400000000000000000000000166C8A4FD0000022B000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/stratego.str// 24 lines 12 code 6 comments 6 blanks module stratego strategies /** // */ main = !"/* " ; id // */ foo = ?'a' rules foobar: "//" -> "\\" // " ' /* " ' */ foo: a -> a // /* where b := 'b' // */ // ; c := $[quotes with anti quotes [b], which are not supported by tokei atm so this is a commented line of code] // ; c := ${quotes with anti quotes {b}, which are not supported by tokei atm so this is a commented line of code} // ; c := $<quotes with anti quotes <b>, which are not supported by tokei atm so this is a commented line of code> 070701000000D6000081A400000000000000000000000166C8A4FD00000108000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/stylus.styl// 20 lines, 10 code, 5 comments, 5 blanks /* * Multi-line comment */ // Single-line comment #app position: absolute left: 0 top: 0 .item::before content: "Stylus" color: orange background-color: white .item::after content: 'Lang' 070701000000D7000081A400000000000000000000000166C8A4FD000001C4000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/svelte.svelte<!-- 41 lines 15 code 21 comments 5 blanks --> <script> /* Javascript multi-line Comment */ let count = 0; // Single line comment function handleClick() { count += 1; } </script> <!--- multi line comment ---> <button on:click={handleClick}> Clicked {count} {count === 1 ? 'time' : 'times'} </button> <style> /* CSS multi line comment */ button { border-radius: 50; background-color: darkorange; } </style> 070701000000D8000081A400000000000000000000000166C8A4FD0000015F000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/swift.swift// 24 lines 6 code 14 comments 4 blanks // Single-line comment /* multi-line comment */ /* /* nested */ */ /* multi line comment */ /* nested /* */ /* nested */ */ import UIKit class ViewController: UIViewController { override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. } } 070701000000D9000081A400000000000000000000000166C8A4FD000000FB000000000000000000000000000000000000002C00000000tokei-13.0.0.alpha.5+git0/tests/data/swig.i/* 16 lines 8 code 5 comments 3 blanks */ %module mymodule /* * Wrapper-includes */ %{ #include "myheader.h" //dummy header %} // Now list ANSI C/C++ declarations int foo; int bar(int x); %rename(my_print) print; extern void print(const char *); 070701000000DA000081A400000000000000000000000166C8A4FD0000016E000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/tact.tact// 20 lines 12 code 4 comments 4 blanks import "@stdlib/deploy"; // comment /* comment */ fun global() { let str: String = "\n \r \t \u1234 \xFF"; // comment while (true) { // comment if /* comment */ (true) { /* comment */ } } } // "quoted" struct St { /* " */ field1: Int; // /* field2: Int as uint128; field3: Int; // */ } 070701000000DB000081A400000000000000000000000166C8A4FD00000340000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/thrift.thrift// 38 lines 29 code 2 comments 7 blanks namespace java test namespace py test /* /* */ service Twitter extends core.BaseService { void ping(), bool postTweet(1: Tweet tweet) throws (1: TwitterUnavailable unavailable), TweetSearchResult searchTweets(1: string query), } enum TweetType { TWEET, # 1 /* RETWEET = 2, // 2 DM = 0xa, // 3 */ REPLY } struct Tweet { 1: required i32 userId, 2: required string userName = "/*", 3: required string text = '...', 4: optional Location loc, 5: optional TweetType tweetType = TweetType.TWEET, 16: optional string language = "en\"glish", // */ } const string TEST1 = // " "starts here, test/* test" // a quote: " const string TEST2 = /* " */ 'starts here, test,*/ test' # another quote: " 070701000000DC000081A400000000000000000000000166C8A4FD000000F3000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/tsx.tsx// 9 lines, 5 code, 3 comments, 1 blanks /** string two numbers together */ const stringNums = (x: number, y: number) => { // the line below makes a string const firstNum = x + ""; const secondNum = firstNum + y; return secondNum; }; 070701000000DD000081A400000000000000000000000166C8A4FD00000148000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/ttcn.ttcn3// 16 lines 7 code 6 comments 3 blanks /** * @description A TTCN-3 demo module * @author John Doe */ module demo { import from definitions all; control { log("Hello world!"); // write something to log // execute(altstepWithTimeout()); execute(test(), 5.0); /* terminate after 5s */ } } 070701000000DE000081A400000000000000000000000166C8A4FD00000282000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/twig.twig{# 16 lines 14 code 1 comments 1 blanks #} <ul id="product-collection"> {% for product in products %} <li class="singleproduct clearfix"> <div class="small"> <div class="prodimage"><a href="{{product.url}}"><img src="{{ product.featured_image | url }}" /></a></div> </div> <div class="description"> <h3><a href="{{product.url}}">{{- product.title -}}</a></h3> <p>{{ product.description | capitalize }}</p> <p class="money">{{ product.price_min | default('0') }}{% if product.price_varies %} - {{ product.price_max | number_format(2, '.', ',') }}{% endif %}</p> </div> </li> {% endfor %} </ul> 070701000000DF000081A400000000000000000000000166C8A4FD000001C9000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/typescript.ts// 33 lines, 20 code, 10 comments, 3 blanks /* Multi-line comment with blanks * */ // Comment class Person { #age: number; #name: string; // end of line comment #height: number; constructor(age: number, name: string, height: number) { this.#age = age; this.#name = name; this.#height = height; } } let main = () => { // Comment with quote " let person = new Person( 5, `Phill the giant`, 7 ); }; main(); 070701000000E0000081A400000000000000000000000166C8A4FD000001B6000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/typst.typ// 16 lines 9 code 3 comments 4 blanks // Some example settings #set document(title: "a title", author: "an author") #set page(numbering: "1 / 1", number-align: center) #set par(justify: true) #set text(size: 13pt, lang: "fr") // with a trailing comment #set heading(numbering: "1.1") /* with another trailing comment */ #let foo = "multiline string" #let bar = "singleline string" /* comment */ /* nested /* comment */ */ #lorem(50) 070701000000E1000081A400000000000000000000000166C8A4FD00000112000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/unison.u-- 16 lines 6 code 8 comments 2 blanks x = 3 if x < 2 then "-- {- -} -- Smaller. Test escaped quote \"!" else "Bigger -- {- -} --" {- Comments Comments -- nested -- Comments Comments -} -- testing quote in comment "hello there!" List.map (a -> a + 1) [1,2,3] 070701000000E2000081A400000000000000000000000166C8A4FD000000EB000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/urweb.ur(* 14 lines 8 code 4 comments 2 blanks *) fun main () = return <xml> <head> <title>Hello world!</title> </head> (* multi line comment *) <body> (* uncounted comment *) <h1>Hello world!</h1> </body> </xml> 070701000000E3000081A400000000000000000000000166C8A4FD00000040000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/urweb_urp.urp# 3 lines 1 code 1 comments 1 blanks urweb # uncounted comment 070701000000E4000081A400000000000000000000000166C8A4FD00000066000000000000000000000000000000000000003300000000tokei-13.0.0.alpha.5+git0/tests/data/urweb_urs.urs(* 3 lines 1 code 1 comments 1 blanks *) val main : unit -> transaction page (* uncounted comment *) 070701000000E5000081A400000000000000000000000166C8A4FD00000112000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/vb6_bas.bas' 12 lines 6 code 3 comments 3 blanks Attribute VB_Name = "Module1" Public Function SayHello(Name As String) ' Create a response string Dim Response As String Response = "Hello " & Name 'Return response string SayHello = Response End Function 070701000000E6000081A400000000000000000000000166C8A4FD00000213000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/vb6_cls.cls' 22 lines 17 code 3 comments 2 blanks VERSION 1.0 CLASS BEGIN MultiUse = -1 'True Persistable = 0 'NotPersistable DataBindingBehavior = 0 'vbNone DataSourceBehavior = 0 'vbNone MTSTransactionMode = 0 'NotAnMTSObject END Attribute VB_Name = "Class1" Attribute VB_GlobalNameSpace = False Attribute VB_Creatable = True Attribute VB_PredeclaredId = False Attribute VB_Exposed = False 'This is a comment Private Sub Class_Initialize() 'This is another comment Dim test As String test = "TESTING" End Sub 070701000000E7000081A400000000000000000000000166C8A4FD0000035D000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/vb6_frm.frm' 34 lines 29 code 3 comments 2 blanks VERSION 5.00 Begin VB.Form Form1 Caption = "Form1" ClientHeight = 3015 ClientLeft = 120 ClientTop = 465 ClientWidth = 4560 LinkTopic = "Form1" ScaleHeight = 3015 ScaleWidth = 4560 StartUpPosition = 3 'Windows Default Begin VB.CommandButton btnTest Caption = "Test" Height = 495 Left = 720 TabIndex = 0 Top = 840 Width = 1095 End End Attribute VB_Name = "Form1" Attribute VB_GlobalNameSpace = False Attribute VB_Creatable = False Attribute VB_PredeclaredId = True Attribute VB_Exposed = False 'This is a comment Private Sub btnTest_Click() 'This is another comment Dim test As String test = "TESTING" End Sub 070701000000E8000081A400000000000000000000000166C8A4FD0000008D000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/vbscript.vbs' 8 lines 3 code 3 comments 2 blanks Dim MyStr1, MyStr2 MyStr1 = "Hello" ' This is also a comment MyStr2 = "Goodbye" REM Comment on a line 070701000000E9000081A400000000000000000000000166C8A4FD0000015A000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/velocity.vm## 11 lines 4 code 5 comments 2 blanks This text is visible. #* This text, as part of a multi-line comment, is not visible. This text is not visible; it is also part of the multi-line comment. This text still not visible. *# This text is outside the comment, so it is visible. ## This text is not visible. #macro( d ) <tr><td></td></tr> #end 070701000000EA000081A400000000000000000000000166C8A4FD00000278000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/vhdl.vhd-- 34 lines 20 code 7 comments 7 blanks /* Since VHDL 2008 C-Style delimited comment are allowed. */ library IEEE; use IEEE.STD_LOGIC_1164.ALL; use IEEE.NUMERIC_STD.ALL; entity tb is Port ( clk : in STD_LOGIC; -- clock rst : in STD_LOGIC; -- reset -- removed: in STD_LOGIC_VECTOR(7 downto 0) ); end tb; -- architecture architecture behavioural of tb is signal toggle : STD_LOGIC := '0'; begin -- Toggles signal process(clk, rst) begin if (rst='1') then toggle <= '0'; else toggle <= not toggle; end if; end process; end 070701000000EB000081A400000000000000000000000166C8A4FD00000076000000000000000000000000000000000000003400000000tokei-13.0.0.alpha.5+git0/tests/data/visualbasic.vb' 7 lines 4 code 2 comments 1 blanks Public Class C Public Sub M() ' This is a comment End Sub End Class 070701000000EC000081A400000000000000000000000166C8A4FD00000A7D000000000000000000000000000000000000002E00000000tokei-13.0.0.alpha.5+git0/tests/data/vqe.qasm// 89 lines 58 code 21 comments 10 blanks /* * Variational eigensolver example * * Goal is to estimate the energy for a fixed set of parameters. * The parameters are updated outside of this program and a new * OpenQASM circuit is generated for the next iteration. */ include "stdgates.inc"; const int[32] n = 10; // number of qubits const int[32] layers = 3; // number of entangler layers const int[32] prec = 16; // precision of all types const int[32] shots = 1000; // number of shots per Pauli observable // Parameters could be written to local variables for this // iteration, but we will request them using extern functions extern get_parameter(uint[prec], uint[prec]) -> angle[prec]; extern get_npaulis() -> uint[prec]; extern get_pauli(int[prec]) -> bit[2 * n]; // The energy calculation uses floating point division, // so we do that calculation in an extern function extern update_energy(int[prec], uint[prec], float[prec]) -> float[prec]; gate entangler q { for uint i in [0:n-2] { cx q[i], q[i+1]; } } def xmeasure(qubit q) -> bit { h q; return measure q; } def ymeasure(qubit q) -> bit { s q; h q; return measure q; } /* Pauli measurement circuit. * The first n-bits of spec are the X component. * The second n-bits of spec are the Z component. */ def pauli_measurement(bit[2*n] spec, qubit[n] q) -> bit { bit b = 0; for uint[prec] i in [0: n - 1] { bit temp; if(spec[i]==1 && spec[n+i]==0) { temp = xmeasure(q[i]); } if(spec[i]==0 && spec[n+i]==1) { temp = measure q[i]; } if(spec[i]==1 && spec[n+i]==1) { temp = ymeasure(q[i]); } b ^= temp; } return b; } // Circuit to prepare trial wave function def trial_circuit(qubit[n] q) { for int[prec] l in [0: layers - 1] { for uint[prec] i in [0: n - 1] { angle[prec] theta; theta = get_parameter(l * layers + i); ry(theta) q[i]; } if(l != layers - 1) entangler q; } } /* Apply VQE ansatz circuit and measure a Pauli operator * given by spec. Return the number of 1 outcomes. */ def counts_for_term(bit[2*n] spec, qubit[n] q) -> uint[prec] { uint[prec] counts; for uint i in [1: shots] { bit b; reset q; trial_circuit q; b = pauli_measurement(spec, q); counts += int[1](b); } return counts; } // Estimate the expected energy def estimate_energy(qubit[n] q) -> float[prec] { float[prec] energy; uint[prec] npaulis = get_npaulis(); for int[prec] t in [0:npaulis-1] { bit[2*n] spec = get_pauli(t); uint[prec] counts; counts = counts_for_term(spec, q); energy = update_energy(t, counts, energy); } return energy; } qubit[n] q; float[prec] energy; energy = estimate_energy(q); 070701000000ED000081A400000000000000000000000166C8A4FD000001FD000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/vue.vue<!-- 36 lines, 24 code, 9 comments, 3 blanks --> <template> <div id="app"> <button v-on:click="clicked"> <!-- Button that increments count --> Clicked {{ count }} {{ count == 1 ? "time" : "times" }} </button> </div> </template> <script> /* Javascript Section */ // Single line export default { data() { return { count: 0, }; }, clicked() { this.count++; }, }; </script> <style> /* Styling Section */ button { background-color: darkorange; } </style> 070701000000EE000081A400000000000000000000000166C8A4FD00000121000000000000000000000000000000000000003500000000tokei-13.0.0.alpha.5+git0/tests/data/webassembly.wat;; 10 lines 8 code 1 comments 1 blanks (module (import "console" "log" (func $log (param i32 i32))) (import "js" "mem" (memory 1)) (data (i32.const 0) "Hi") (func (export "writeHi") i32.const 0 ;; pass offset 0 to log i32.const 2 ;; pass length 2 to log call $log)) 070701000000EF000081A400000000000000000000000166C8A4FD00001D35000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/wenyan.wy//! 141 lines 107 code 1 comments 33 blanks 吾嘗觀「「曆法」」之書。方悟「今何紀元時」「彼時何小時」「彼刻何刻」「彼分何分」「彼秒何秒」之義。 吾嘗觀「「畫譜」」之書。方悟「備紙」「擇筆」「蘸色」「落筆」「運筆」「提筆」「設色」「裱畫」之義。 吾嘗觀「「算經」」之書。方悟「倍圓周率」「正弦」「餘弦」之義。 施「今何紀元時」。名之曰「紀元時」。 施「彼時何小時」於「紀元時」。名之曰「小時」。 施「彼刻何刻」於「紀元時」。名之曰「刻」。 施「彼分何分」於「紀元時」。名之曰「分」。 施「彼秒何秒」於「紀元時」。名之曰「秒」。 有數四百。名之曰「紙縱」。 有數四百。名之曰「紙橫」。 除二於「紙縱」。名之曰「半縱」。 除二於「紙橫」。名之曰「半橫」。 吾有一數。名之曰「比例」。 批曰。「「文氣淋灕。字句切實」」。 若「半橫」小於「半縱」者。 昔之「比例」者。今「半橫」是矣。 若非。 昔之「比例」者。今「半縱」是矣。 云云。 吾有一術。名之曰「縱坐標」。欲行是術。必先得一數。曰「南」。是術曰。 乘「南」以「比例」。減其於「半縱」。乃得矣。 是謂「縱坐標」之術也。 吾有一術。名之曰「橫坐標」。欲行是術。必先得一數。曰「東」。是術曰。 乘「東」以「比例」。減其於「半橫」。乃得矣。 是謂「橫坐標」之術也。 吾有一術。名之曰「極坐標」。欲行是術。必先得二數。曰「距」。曰「角」。是術曰。 施「餘弦」於「角」。乘其以「距」。取一以施「縱坐標」。名之曰「縱」。 施「正弦」於「角」。乘其以「距」。取一以施「橫坐標」。名之曰「橫」。 吾有一物。名之曰「坐標」。其物如是。 物之「「橫」」者。數曰「橫」。 物之「「縱」」者。數曰「縱」。 是謂「坐標」之物也。乃得「坐標」。 是謂「極坐標」之術也。 吾有一術。名之曰「畫鐘面」。 欲行是術。必先得一物。曰「紙」。一數。曰「半徑」。 是術曰。 有數一千零二十四。名之曰「割圓」。 夫「半徑」。夫零。取二以施「極坐標」。名之曰「始坐標」。 夫「紙」。夫「始坐標」之「「橫」」。夫「始坐標」之「「縱」」。取三以施「落筆」。 有數一。名之曰「甲」。 為是「割圓」遍。 除「甲」以「割圓」。乘其以「倍圓周率」。名之曰「乙」。 夫「半徑」。夫「乙」。取二以施「極坐標」。名之曰「坐標」。 夫「紙」。夫「坐標」之「「橫」」。夫「坐標」之「「縱」」。取三以施「運筆」。 加「甲」以一。昔之「甲」者。今其是矣。 云云。 施「蘸色」於「紙」於「「鈦白」」。 施「設色」於「紙」。 施「蘸色」於「紙」於「「黑」」。 施「提筆」於「紙」。 有數零。名之曰「丙」。 為是六十遍。 除「丙」以六十。乘其以「倍圓周率」。名之曰「丁」。 夫「半徑」。夫「丁」。取二以施「極坐標」。名之曰「正刻外坐標」。 夫「紙」。夫「正刻外坐標」之「「橫」」。夫「正刻外坐標」之「「縱」」。取三以施「落筆」。 乘九分五於「半徑」。夫「丁」。取二以施「極坐標」。名之曰「正刻內坐標」。 夫「紙」。夫「正刻內坐標」之「「橫」」。夫「正刻內坐標」之「「縱」」。取三以施「運筆」。 施「提筆」於「紙」。 加「丙」以一。昔之「丙」者。今其是矣。 云云。 有數零。名之曰「丙」。 為是十二遍。 除「丙」以十二。乘其以「倍圓周率」。名之曰「戊」。 夫「半徑」。夫「戊」。取二以施「極坐標」。名之曰「初刻外坐標」。 夫「紙」。夫「初刻外坐標」之「「橫」」。夫「初刻外坐標」之「「縱」」。取三以施「落筆」。 乘八分五於「半徑」。夫「戊」。取二以施「極坐標」。名之曰「初刻內坐標」。 夫「紙」。夫「初刻內坐標」之「「橫」」。夫「初刻內坐標」之「「縱」」。取三以施「運筆」。 施「提筆」於「紙」。 加「丙」以一。昔之「丙」者。今其是矣。 云云。 是謂「畫鐘面」之術也。 吾有一術。名之曰「畫指針」。 欲行是術。必先得一物。曰「紙」。五數。曰「角」。曰「針長」。曰「尾長」。曰「針角」。曰「尾角」。 是術曰。 夫「針長」。加「針角」於「角」。取二以施「極坐標」。名之曰「甲」。 乘負一於「尾長」。減「尾角」於「角」。取二以施「極坐標」。名之曰「乙」。 乘負一於「尾長」。加「尾角」於「角」。取二以施「極坐標」。名之曰「丙」。 夫「針長」。減「針角」於「角」。取二以施「極坐標」。名之曰「丁」。 夫「紙」。夫「甲」之「「橫」」。夫「甲」之「「縱」」。取三以施「落筆」。 夫「紙」。夫「乙」之「「橫」」。夫「乙」之「「縱」」。取三以施「運筆」。 夫「紙」。夫「丙」之「「橫」」。夫「丙」之「「縱」」。取三以施「運筆」。 夫「紙」。夫「丁」之「「橫」」。夫「丁」之「「縱」」。取三以施「運筆」。 夫「紙」。夫「甲」之「「橫」」。夫「甲」之「「縱」」。取三以施「運筆」。 施「蘸色」於「紙」於「「花青」」。 施「設色」於「紙」。 是謂「畫指針」之術也。 吾有一術。名之曰「执笔」。是術曰。 施「(()=>document.getElementById("out").innerHTML="")」。 施「今何紀元時」。名之曰「紀元時」。 施「彼時何小時」於「紀元時」。名之曰「時」。 施「彼分何分」於「紀元時」。名之曰「分」。 施「彼刻何刻」於「紀元時」。名之曰「刻」。 施「彼秒何秒」於「紀元時」。名之曰「秒」。 乘「刻」以十五。加其於「分」。昔之「分」者。今其是矣。 除「秒」以六十。加其於「分」。昔之「分」者。今其是矣。 除「分」以六十。加其於「時」。昔之「時」者。今其是矣。 除「分」以六十。乘其以「倍圓周率」。乘其以負一。名之曰「分角」。 除「時」以十二。乘其以「倍圓周率」。乘其以負一。名之曰「時角」。 除「秒」以六十。乘其以「倍圓周率」。乘其以負一。名之曰「秒角」。 施「備紙」於「紙橫」。於「紙縱」。名之曰「紙」。 施「畫鐘面」於「紙」。於九分。 施「畫指針」於「紙」。於「秒角」。於八分。於一分。於三毫。於一分。 施「畫指針」於「紙」。於「分角」。於七分五釐。於一分。於三毫。於三分。 施「畫指針」於「紙」。於「時角」。於五分五釐。於八釐。於五毫。於五分。 施「裱畫」於「紙」於「「out」」。 是謂「执笔」之術也。 施「(x=>setInterval(x, 500))」於「执笔」。070701000000F0000081A400000000000000000000000166C8A4FD0000019D000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/wgsl.wgsl// 13 lines 10 code 2 comments 1 blanks // comment [[stage(vertex)]] fn vs_main([[builtin(vertex_index)]] in_vertex_index: u32) -> [[builtin(position)]] vec4<f32> { const x = f32(i32(in_vertex_index) - 1); const y = f32(i32(in_vertex_index & 1u) * 2 - 1); return vec4<f32>(x, y, 0.0, 1.0); } [[stage(fragment)]] fn fs_main() -> [[location(0)]] vec4<f32> { return vec4<f32>(1.0, 0.0, 0.0, 1.0); } 070701000000F1000081A400000000000000000000000166C8A4FD00000105000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/xsl.xsl<!-- 13 lines 7 code 4 comments 2 blanks --> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <!-- Some comment --> <xsl:template match="A"> <xsl:value-of select="."/> </xsl:template> </xsl:stylesheet> 070701000000F2000081A400000000000000000000000166C8A4FD0000017F000000000000000000000000000000000000003100000000tokei-13.0.0.alpha.5+git0/tests/data/xtend.xtend// 23 lines 13 code 4 comments 6 blanks class Test { static def void main(String[] args) { /* * Multiline comment */ val f = new Foo() f.bar() // Not counted } } class Foo { def bar() { println('string type 1') println("string type 2") println('''string type 3''') } } 070701000000F3000081A400000000000000000000000166C8A4FD000002A4000000000000000000000000000000000000002F00000000tokei-13.0.0.alpha.5+git0/tests/data/yaml.yaml# 34 lines 29 code 3 comments 2 blanks # Manifest file from Kubernetes documentation: # https://kubernetes.io/docs/tutorials/stateless-application/guestbook/ apiVersion: apps/v1 kind: Deployment metadata: name: redis-master labels: app: redis spec: selector: matchLabels: app: redis role: master tier: backend replicas: 1 template: metadata: labels: app: redis role: master tier: backend spec: containers: - name: master image: k8s.gcr.io/redis:e2e resources: requests: cpu: 100m memory: 100Mi ports: - containerPort: 6379070701000000F4000081A400000000000000000000000166C8A4FD0000018B000000000000000000000000000000000000003000000000tokei-13.0.0.alpha.5+git0/tests/data/zencode.zs// 21 lines 9 code 7 comments 5 blanks // This is a single line comment. /* This is a multiline comment on a single line. */ /* This is a multiline comment. */ var str = "/*"; var arr = [str, @"wysiwyg", '\"']; for item in arr { print(item); // Found the */ } // Comment with quote " var badStr = // Comment before value "\""; badStr = // Another comment before value @'zen'; 070701000000F5000081A400000000000000000000000166C8A4FD000000E9000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tests/data/zig.zig// 11 lines 5 code 3 comments 3 blanks /// Documentation comment pub fn main() void { const a = 5; // not-counted // Leading-comment const b = c"line comment embedded //"; const c = \\line comment embedded // // } 070701000000F6000081A400000000000000000000000166C8A4FD000000C6000000000000000000000000000000000000003200000000tokei-13.0.0.alpha.5+git0/tests/data/zokrates.zok// 11 lines 3 code 6 comments 2 blanks /* This is a multi-line comment written in more than just one line. */ def main() -> field { // an inline comment return 42; // on a line. } 070701000000F7000041ED00000000000000000000000266C8A4FD00000000000000000000000000000000000000000000002A00000000tokei-13.0.0.alpha.5+git0/tests/embedding070701000000F8000081A400000000000000000000000166C8A4FD00000337000000000000000000000000000000000000005000000000tokei-13.0.0.alpha.5+git0/tests/embedding/file_triggeringprincipal_frame_1.html<!-- 27 lines 20 code 5 comments 2 blanks --> < 0!DOCTYPE HTML> <html> <head><meta charset="utf-8"></head> <body> <b>Frame 1</b><br/> <script type="application/javascript"> // make sure to set document.domain to the same domain as the subframe window.onload = function() { document.domain = "mochi.test"; }; window.addEventListener("message", receiveMessage); function receiveMessage(event) { // make sure to get the right start command, otherwise // let the parent know and fail the test if (event.data.start !== "startTest") { window.removeEventListener("message", receiveMessage); window.parent.postMessage({triggeringPrincipalURI: "false"}, "*"); } // click the link to navigate the subframe document.getElementById("testlink").click(); } </script> </body> </html> 070701000000F9000081A400000000000000000000000166C8A4FD0000013A000000000000000000000000000000000000002D00000000tokei-13.0.0.alpha.5+git0/tokei.example.toml# The width of the terminal output in columns. columns = 80 # Sort languages based on the specified column. sort = "lines" # If set, tokei will only show the languages in `types`. types = ["Python"] # Any doc strings (e.g. `"""hello"""` in python) will be counted as comments. treat_doc_strings_as_comments = true 07070100000000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000B00000000TRAILER!!!1166 blocks
Locations
Projects
Search
Status Monitor
Help
OpenBuildService.org
Documentation
API Documentation
Code of Conduct
Contact
Support
@OBShq
Terms
openSUSE Build Service is sponsored by
The Open Build Service is an
openSUSE project
.
Sign Up
Log In
Places
Places
All Projects
Status Monitor
